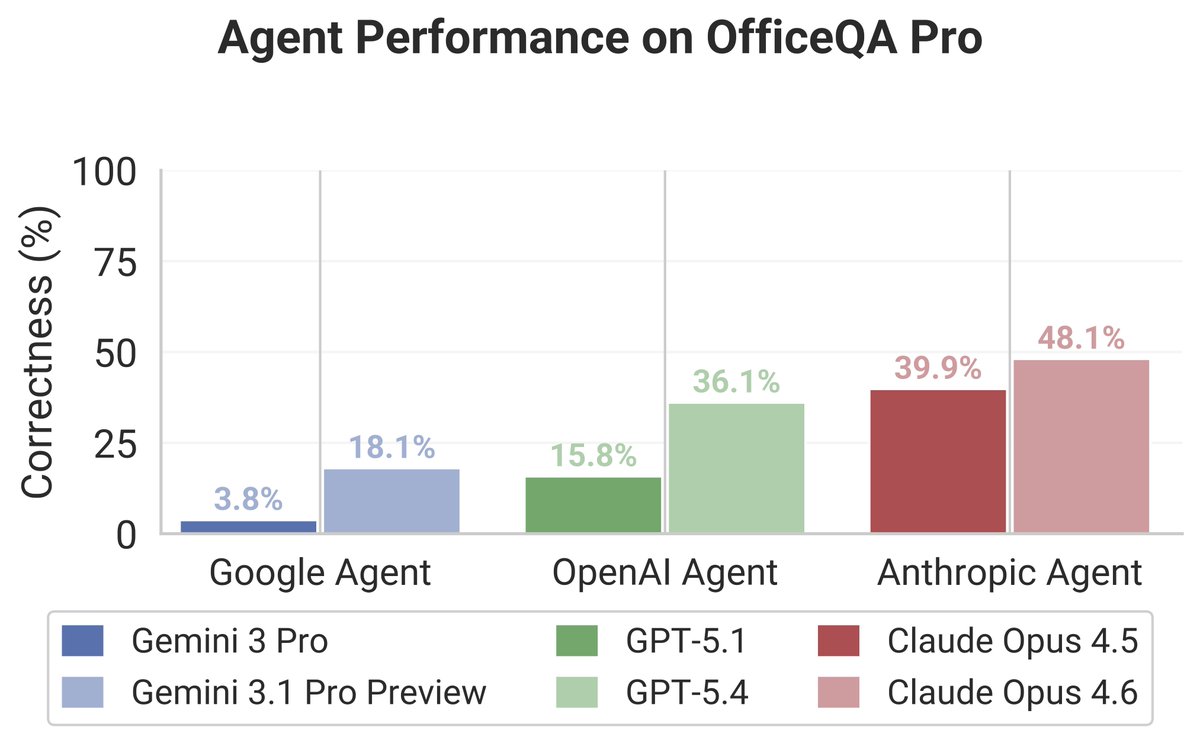
Genie has transformed how Databricks users work with data, with 3x the accuracy of generic agents. We're sharing some of the research behind it and what makes building data agents challenging. Super proud of our research team's impact with this! https://t.co/eLB2ElVo8S
Most AI benchmarks test reasoning in isolation.
Real enterprise tasks require grounded reasoning:
1️⃣ Find the right documents
2️⃣ Extract the right values
3️⃣ Perform analyses
OfficeQA Pro evaluates this end-to-end. Frontier agents still score <50%.
🧵Paper & details below!
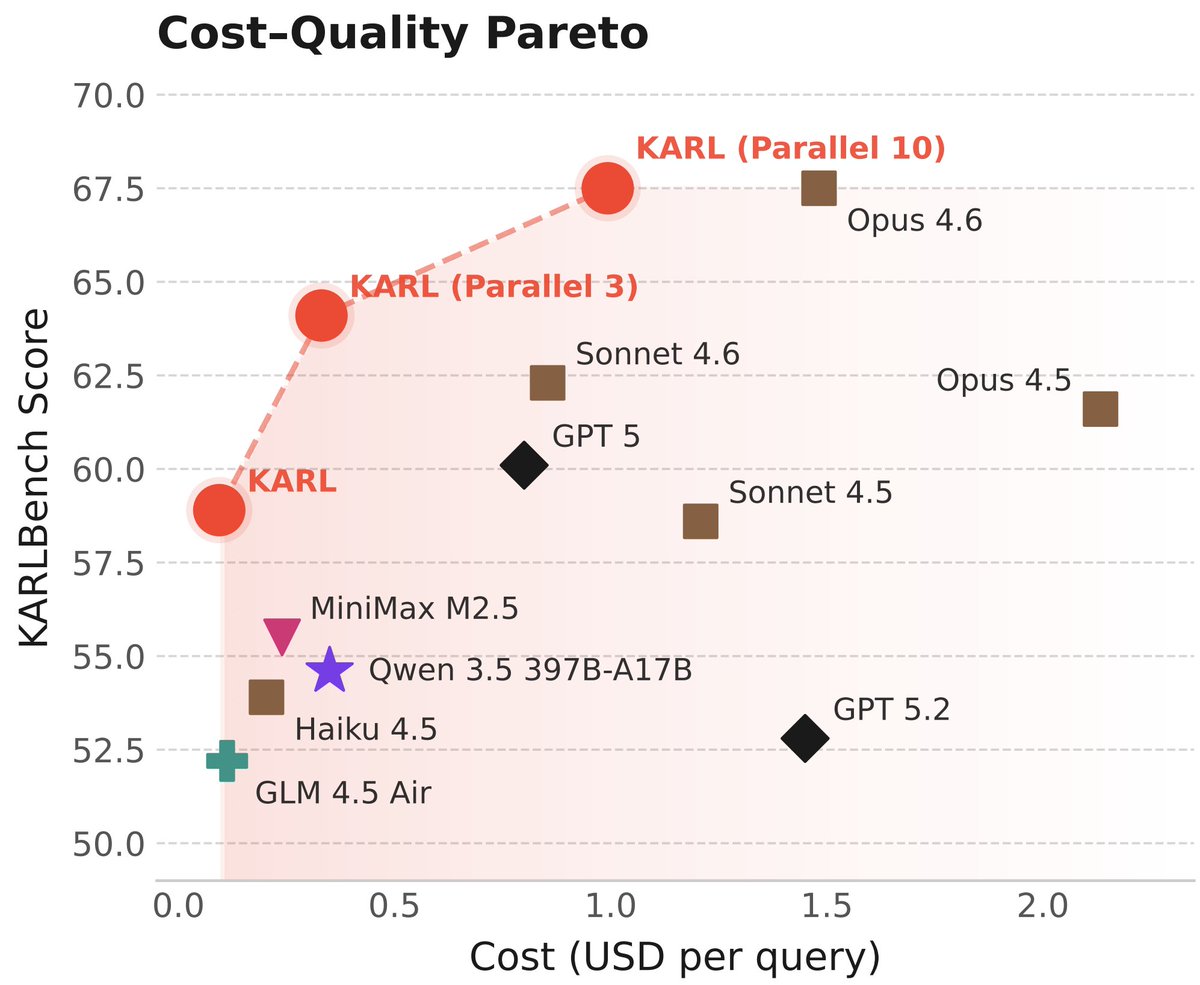
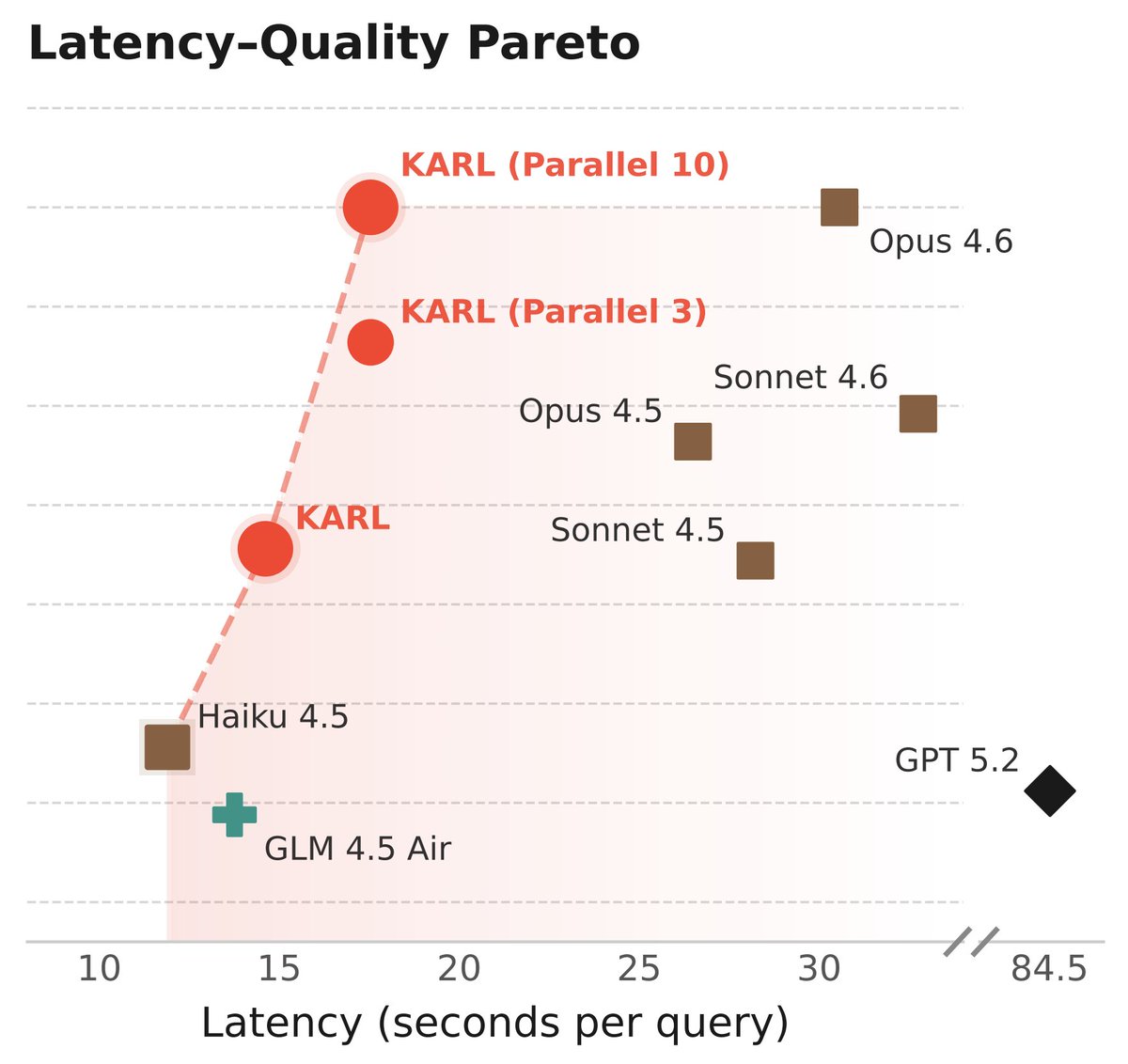
Meet KARL, an RL'd model for document-centric tasks at frontier quality and open source cost/speed. Great for @databricks customers and scientists (77-page tech report!) As usual, this isn't just one model - it's an RL assembly line to churn out models for us and our customers 🧵
🚀 Today we’re releasing FlashOptim: better implementations of Adam, SGD, etc, that compute the same updates but save tons of memory. You can use it right now via `pip install flashoptim`. 🚀
https://t.co/nRrLSpjnwV
A bunch of cool ideas make this possible: [1/n]
💡New blog on MemAlign: a lightweight dual-memory framework for aligning LLM judges with human feedback
It delivers competitive or better quality at orders-of-magnitude lower cost & latency, enabling memory scaling—quality from experience, not more per-query compute.
Agent memory is a simple and powerful way to do continual learning! With the new MemAlign method from Databricks Research, we can build better LLM judges from examples of human ratings, and they scale with more data. Now in Databricks and @MLflow. https://t.co/aMbc8IZ9zb
Instructed Retriever is a multi-tiered declarative approach for building high quality search agents. It's an example of an "instructed system", which goes beyond prompt tuning and tool calling by passing data among modules which work together to fulfill an information need.
Today we’re releasing OfficeQA — a new benchmark for end-to-end grounded reasoning that reflects the real work enterprises need AI agents to do.
More details below 👇
🚀 Our Databricks Mosaic Research team are looking for Research Interns for Summer 2026!
Our team explores exciting challenges at the intersection of AI and data, especially in how AI agents can help enterprises reason over knowledge and automate data workflows.
It’s a place for deep thinking, fast building, and a lot of fun!
If you’re a late-stage PhD student passionate about applied AI research, please email me your CV (veronica [dot] lyu [at] databricks [dot] com) with `[Research Intern]` in the title!
We work on areas like agentic systems for knowledge QA and data engineering, learning from feedback, agent memory, intelligent document parsing …… Check out some of our latest work in our blogs: https://t.co/2YMXjoOhyb
Not that I have a favorite recent project, but... 🧵 LLM judges are the popular way to evaluate generative models. But they have drawbacks. They're:
* Generative, so slow and expensive.
* Nondeterministic.
* Uncalibrated. They don't know how uncertain they are.
Meet PGRM!
Since joining @databricks, our research team has been hard at work on Agent Bricks, a new product that helps enterprises develop state-of-the-art domain-specific agents. We are now releasing a research blog about Agent Learning from Human Feedback (ALHF) https://t.co/2RDs3H6mkY
I'm at ICML 🇨🇦 and I'm hiring at @databricks. Visit our booth if you're interested. My scientific focus: It's 1972 in AI, there's an AI crisis, Dijkstra isn't here to save us, and maybe RL can. Why Databricks? The long road to AGI is being paved here and we have the real evals 🧵
Introducing Muscle v0 -- infinite degrees of freedom, from @DaxoRobotics. A different mountain to climb - with a far more beautiful peak.
We built this from the ground up:
- Ultra-dexterous
- Built for machine learning
- Durable and robust
More below (1/n)
Excited to launch Agent Bricks, a new way to build auto-optimized agents on your tasks. Agent Bricks uniquely takes a *declarative* approach to agent development: you tell us what you want, and we auto-generate evals and optimize the agent.
https://t.co/EVqwq583cF
🤔What model explanation method should you use? How to ensure it reflects the model’s true reasoning?
🌟 In our CL survey, Towards Faithful Model Explanation in NLP, we review 110+ explainability methods through the lens of faithfulness.
Check out my presentation at #EMNLP2024!
💬 We call for future work on standardizing faithfulness evaluation, exploring the relationship between interpretability and performance, and developing interpretability methods that consider high-level features, flexible explanation forms, and alternative task formats.






















![davisblalock's tweet photo. 🚀 Today we’re releasing FlashOptim: better implementations of Adam, SGD, etc, that compute the same updates but save tons of memory. You can use it right now via `pip install flashoptim`. 🚀
https://t.co/nRrLSpjnwV
A bunch of cool ideas make this possible: [1/n] https://t.co/xeaMyWztpv](https://pbs.twimg.com/media/HCgxeDgawAEzt6q.jpg)