Really excited to share our latest research on the Instructed Retriever - a novel retrieval architecture that reimagines search for the agentic era.
https://t.co/CwUWYIhFTJ
Amazing work by @cindyxinyiwang and @mrdrozdov who co-led this effort!
Most agentic search systems get better by thinking longer: more tool calls, more reason-act loops, each step waiting on the last. Quality goes up, but so does latency.
Instructed-Retriever-1 takes a different route. Instead of scaling test-time compute sequentially, it scales it in parallel. One retrieval-specialized model fans the work out: it generates multiple query and filter formulations to widen recall, then reranks the merged evidence with a multi-pivot reranker to sharpen precision. Both stages run at once, so searching more broadly no longer means searching more slowly.
The result inside Knowledge Assistant: search time drops more than 3x and answer time 2x, with time to first token around two seconds, and no drop in quality (it matches Claude Sonnet 4.5 retrieval quality on KARLBench). For the people using it, that means far less waiting between question and answer, the freedom to ask more follow-ups, and more of the knowledge base actually surfaced. Rolling out to all customers now, with no reconfiguration.
Read how we did it: https://t.co/yjqWN1KgTc
1/ "Can QPP Choose the Right Query Variant?" has been accepted at #SIGIR2026!🇦🇺
You can easily over-generate multiple query variants at low cost, but running RAG for all of them is expensive!
Can we pick the winner query before paying the generation cost?
https://t.co/mv5wgCgKul
Most enterprise questions don't live in one dataset. They span structured systems and unstructured sources like documents, reviews, and reports.
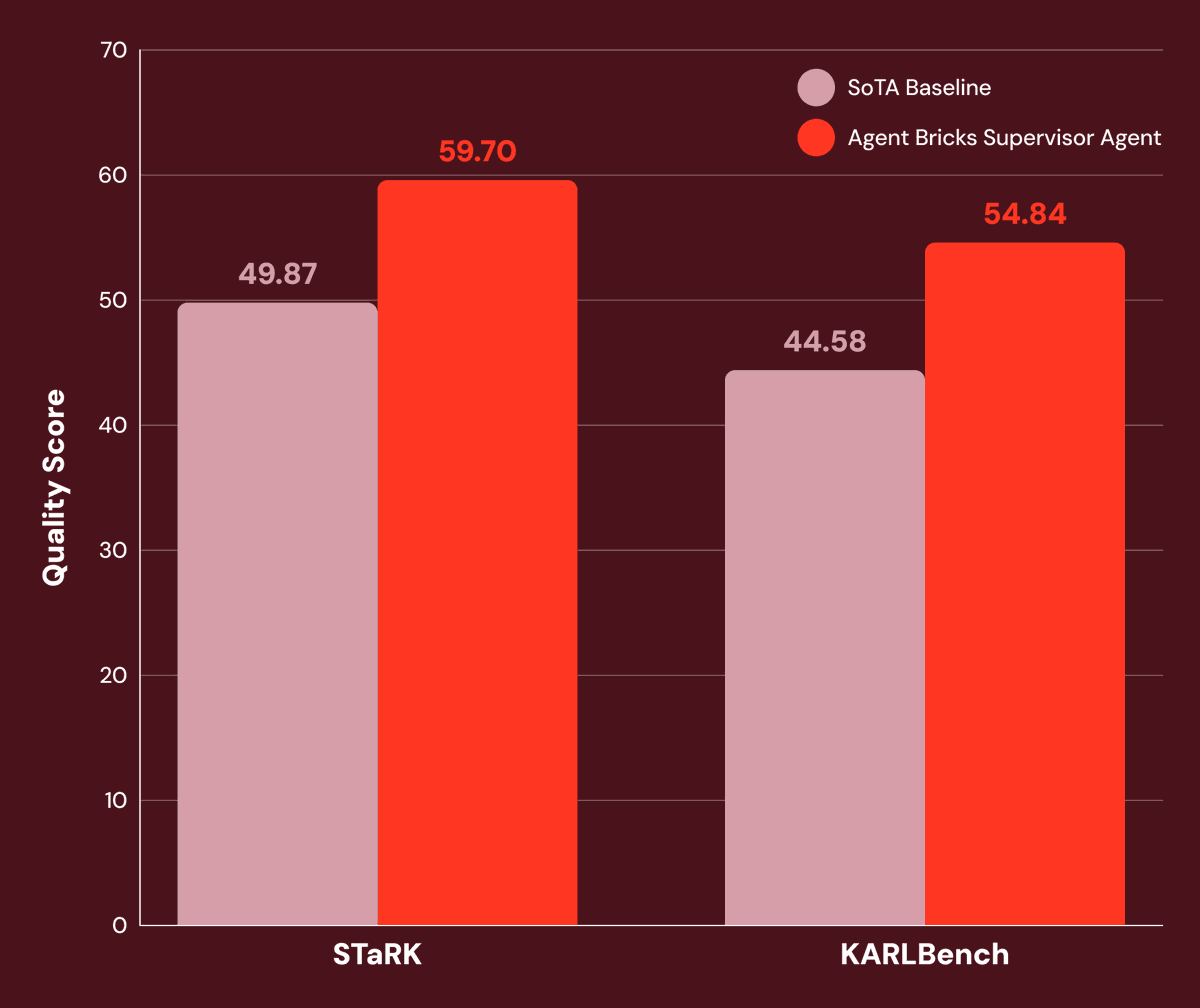
In our latest research, we show how Agent Bricks Supervisor Agent handles this by decomposing queries across structured and unstructured tools, then synthesizing results over multiple reasoning steps.
The results across STaRK and KARLBench: 20%+ improvement over SoTA baselines, with the biggest gains on tasks requiring tight integration of structured and unstructured data.
All built declaratively — no custom code, just precise instructions and the right tools. https://t.co/EBSM6iU89g
Applications are officially open for the Grounded Reasoning Cup at Data + AI Summit 2026! 🏆
We’re looking for students who want to:
- Tackle high‑impact enterprise challenges
- Showcase work to top researchers/engineers (with recruiters in the room)
- Compete for $100k in model credit prizes
Apply here: https://t.co/bjinqjwuWr
Competition overview: https://t.co/5lUJHB9V8u
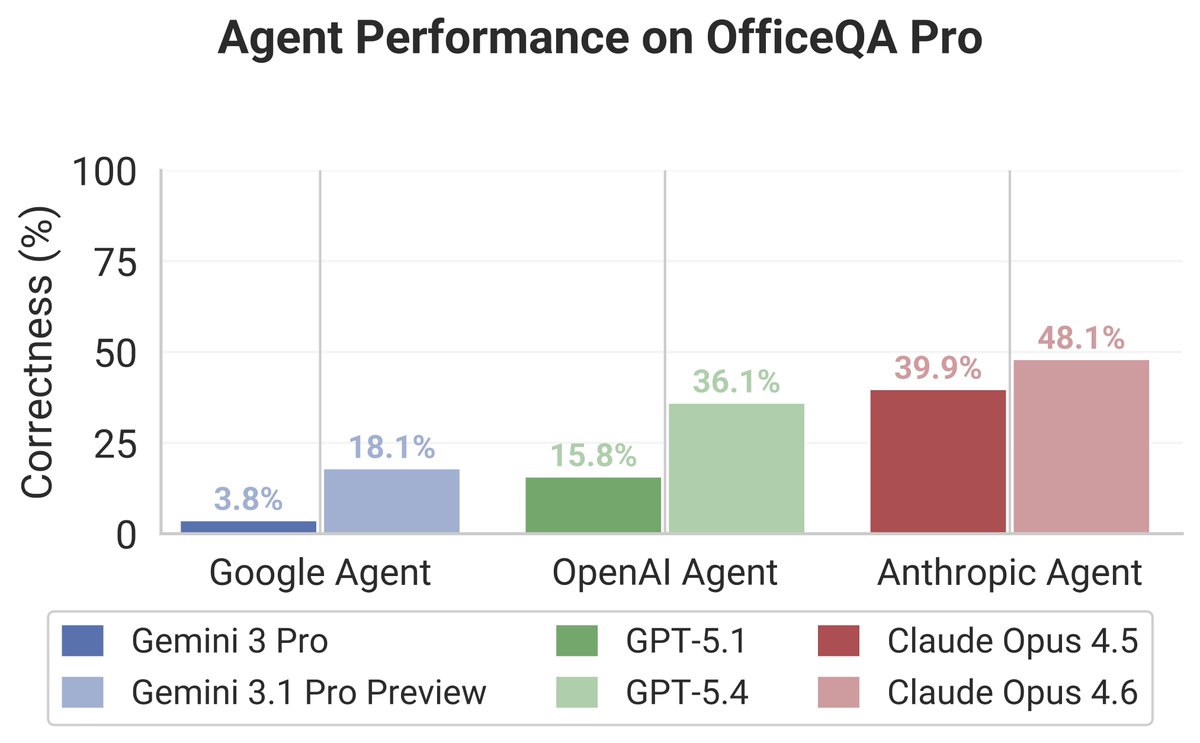
We just published OfficeQA Pro - a set of 133 challenging questions from the original OfficeQA benchmark. Even the best frontier agents still struggle on OfficeQA Pro with common issues stemming from errors in parsing, retrieval, and visual reasoning.
All of these are realistic problems that @databricks customers face in their daily work, and we hope that OfficeQA Pro will contribute to advancing SoTA on grounded reasoning tasks.
Technical Report: https://t.co/Eqezt8709W
Github: https://t.co/N9zFJPDC6t
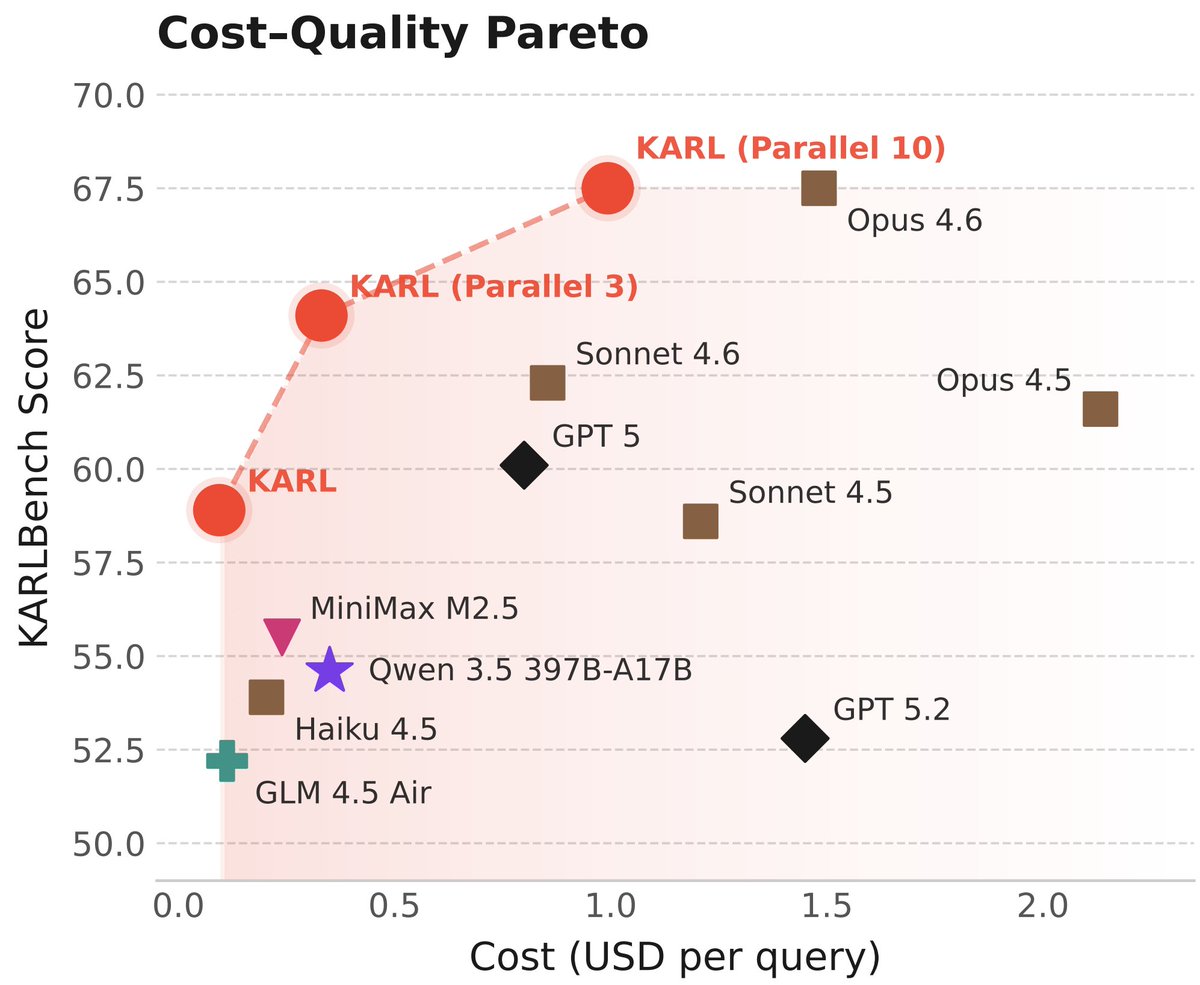
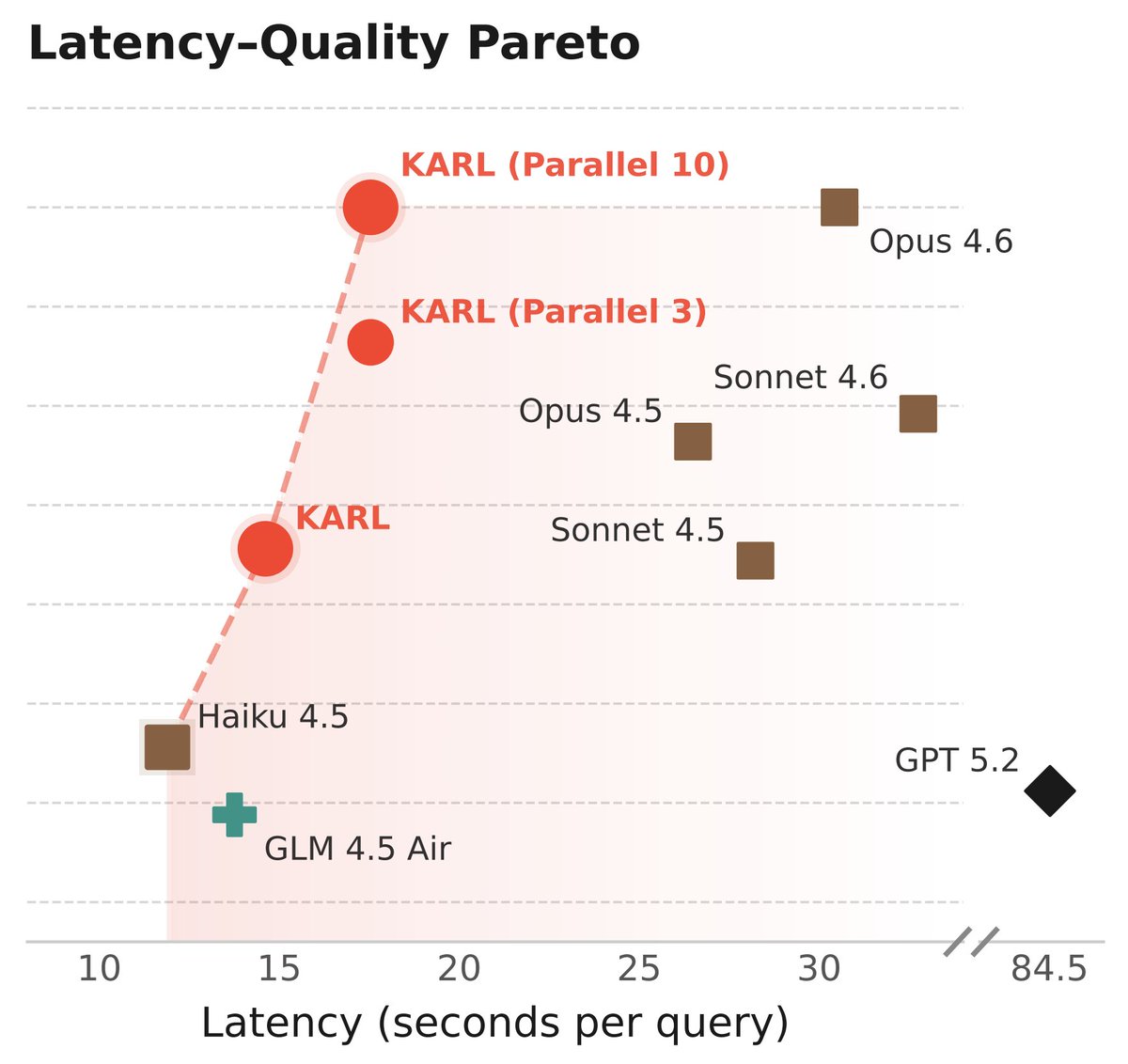
I thought about posting a thread on KARL, a new Pareto-optimal model for retrieval and grounded reasoning tasks. But @jefrankle did a much better job than I ever could. If you have any interest in information retrieval and/or RL, check it out! Full report: https://t.co/bKvxsA3lk7
Meet KARL, an RL'd model for document-centric tasks at frontier quality and open source cost/speed. Great for @databricks customers and scientists (77-page tech report!) As usual, this isn't just one model - it's an RL assembly line to churn out models for us and our customers 🧵
Agent memory is a simple and powerful way to do continual learning! With the new MemAlign method from Databricks Research, we can build better LLM judges from examples of human ratings, and they scale with more data. Now in Databricks and @MLflow. https://t.co/aMbc8IZ9zb
Instructed retriever is now available for all of our Agent Bricks Knowledge Assistant customers. Consider trying it out for your next retrieval agent project. https://t.co/ksHTvYRCJV
Really excited to share our latest research on the Instructed Retriever - a novel retrieval architecture that reimagines search for the agentic era.
https://t.co/CwUWYIhFTJ
Amazing work by @cindyxinyiwang and @mrdrozdov who co-led this effort!
Instructed retriever is not just better than RAG, but it is also a much more effective tool in a multi-step agentic setting, where it not only delivers better results, but also does it faster and in fewer steps.
@mrdrozdov@jeffreyhuber "Some people, when confronted with a problem, think 'I know, I’ll use 𝚛̶𝚎̶𝚐̶𝚞̶𝚕̶𝚊̶𝚛̶ ̶𝚎̶𝚡̶𝚙̶𝚛̶𝚎̶𝚜̶𝚜̶𝚒̶𝚘̶𝚗̶ search.' Now they have two problems."
If you are excited about the intersection of reinforcement learning and highly complex economically valuable tasks --I can't think of a better place to spend the summer of 2026!
I'm hiring interns for next summer at @databricks! Specifically on (1) empirical RL at scale on non-verifiable tasks and (2) enabling real people specify the behaviors they want out of AI (e.g., through evals) on highly complex tasks. 🧵
We released OfficeQA today -- a hard benchmark for evaluating agents on grounded reasoning tasks. More details in our blog https://t.co/fIRhi0sF8Y and the thread below