In 1945, Vannevar Bush imagined a machine to extend a scientist's memory. He called it the MemEx.
80 years later, we built one for LLM agents.
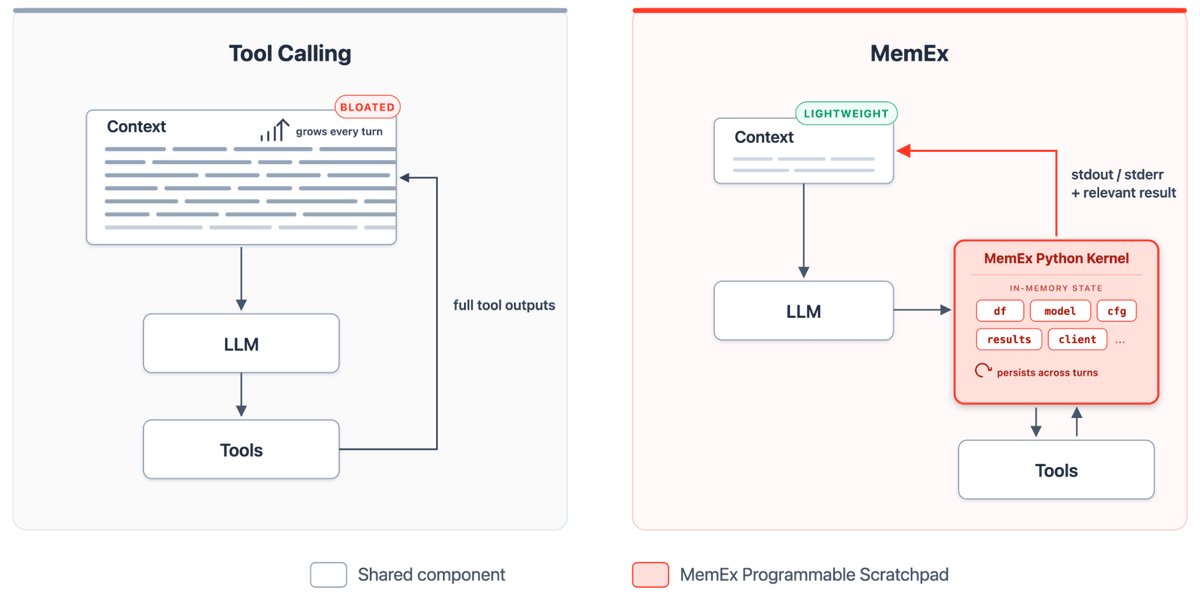
Tool outputs become Python objects; only print statements reach the model's context.
🧵 https://t.co/YyrGsn3TB7
Scriptable subagents are the key ingredient that makes dynamic workflows possible!
@DbrxMosaicAI we built MemEx harness which allows composing subagents via python code🐍. Subagents can also return live objects for further manipulation.
Read more here https://t.co/YyrGsn3TB7
@samdotb Checkout MemEx from @DbrxMosaicAI
We built a programmable scratchpad for LLM agents which does just that and a lot more!
https://t.co/FRKTls9xEa
In 1945, Vannevar Bush imagined a machine to extend a scientist's memory. He called it the MemEx.
80 years later, we built one for LLM agents.
Tool outputs become Python objects; only print statements reach the model's context.
🧵 https://t.co/YyrGsn3TB7
Ever wished we had fewer X-training hyphenates? Pre, mid, post etc. Why not just Training?
Trying to bridge the divides (and get all our friends into one team again), we intro *Introspective X Training*, an offline RL inspired method that scales effectively across any LLM stage by annotating your data with a thinking reward generated language critique!
Up to 2.8x FLOP efficiency + 5-10 point score gains (esp with math and code) at any stage from scratch to 24T tokens on 8b (active) sized models!! We burned much compute ablating so you wouldn't have to
Moral of the story is‼️don't throw out any data via filtering, just feedback condition it‼️
You can spend FLOPs up front on inference to *classify* data quality and then train so that tokens aren't all treated equally based on the feedback starting early in training itself. Right now they're really only separated out much later during mid/post training
This improves overall compute efficiency and gives us benchmark perf not possible with just baseline methods!
Paper here: https://t.co/9oSYwQEpbi
Thanks to @BrandoCui and @GXiming for leading this w/ @__SyedaAkter@davidjesusacu@hyunw_kim@jaehunjung_com Yuxiao Qu @shrimai_@YejinChoinka
Extremely excited to see this hit the timeline the same day I give a talk where I spend 2 minutes ranting about how As We May Think might be the most relevant essay to today's information retrieval world.
And on top of that, it's great work going in the right direction!
We're pushing the frontier of enterprise agents that reason over massive amounts of structured and unstructured data at @databricks. A recurring barrier is that agents burn tokens reading data and grow fuzzy as their context fills up. MemEx is an elegant solution. It lifts performance on both frontier and smaller OSS models, while significantly cutting the cost and latency of complex agentic tasks.
New research from Databricks: the context window is the only persistent substrate today's LLM agents have, and it floods fast. A single SQL query can return millions of rows that ride along in every subsequent turn, even when only one cell ever mattered. We hit this constraint every day in the agents we run in production, from Genie to Agent Bricks' Supervisor Agent to KARL.
In a new post from the Databricks research team, we introduce MemEx: a programmable Python scratchpad that lets agents transform, slice, and persist tool outputs as typed objects in a live kernel. Same observe-act loop. Different action space.
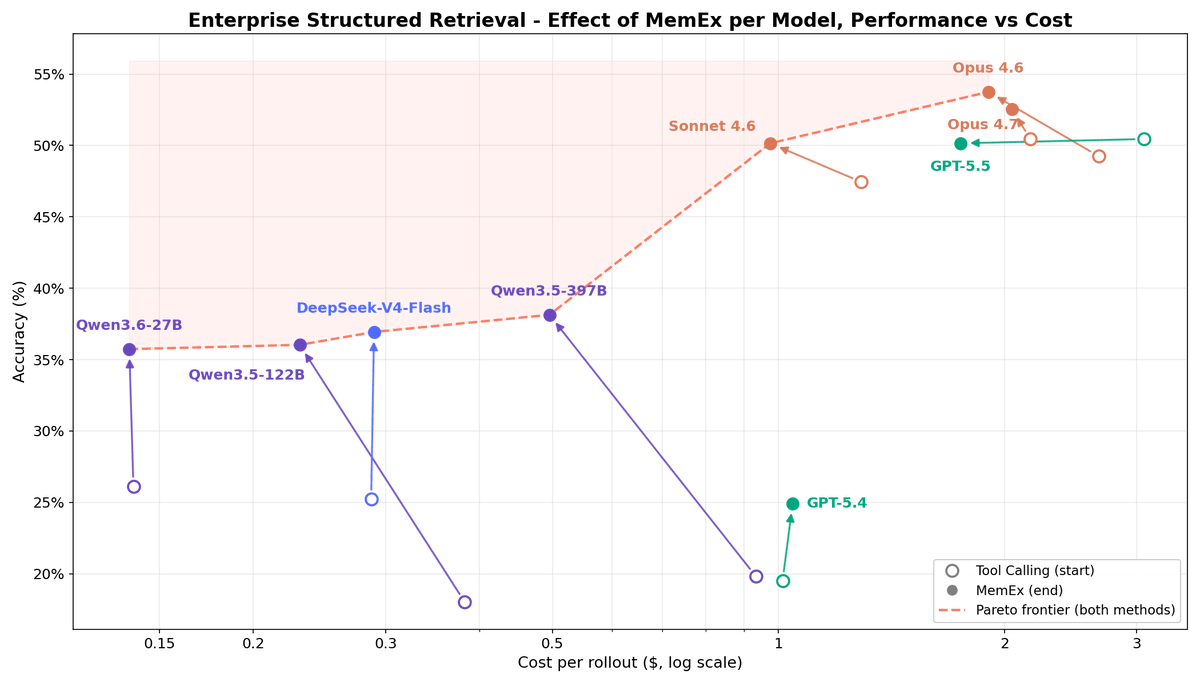
Across nine frontier and open-weight models on two enterprise agentic tasks (OfficeQA Pro and Enterprise Structured Retrieval):
• Frontier models (Opus 4.6, Sonnet 4.6, Gemini 3.1 Pro) gain 2 to 5 accuracy points at 25 to 30% lower cost
• Qwen 122B and Qwen 397B nearly double accuracy at 40 to 50% lower cost
• Four of the five points on the OfficeQA Pro cost-accuracy Pareto frontier are MemEx configurations
MemEx extends the code-as-action line (CodeAct, Anthropic Programmatic Tool Calling, Cloudflare Code Mode) with persistent scope across turns, eager spawn_agent for parallel sub-agents that share the parent's namespace, typed submit() for validated returns, and live-object scope injection. Built on aroll, the same Databricks agentic rollouts framework already powering those production systems.
MemEx is rolling out across Databricks first-party agents and Agent Bricks soon. If you build on Databricks agents today, you'll be able to try it.
Full write-up: https://t.co/WmyAQAmWEd
Agents are bottlenecked by the current tool-calling based harness. Outputs get flattened to text, added to context, and re-parsed each turn. The model spends most of its tokens transcribing.
We just shipped MemEx where the agent gets supercharged with a Python scratchpad!
🚀 MemEx is rolling out across @databricks's first-party agents and Agent Bricks.
Full write-up (numbers, design, trace analysis):
https://t.co/YyrGsn3TB7
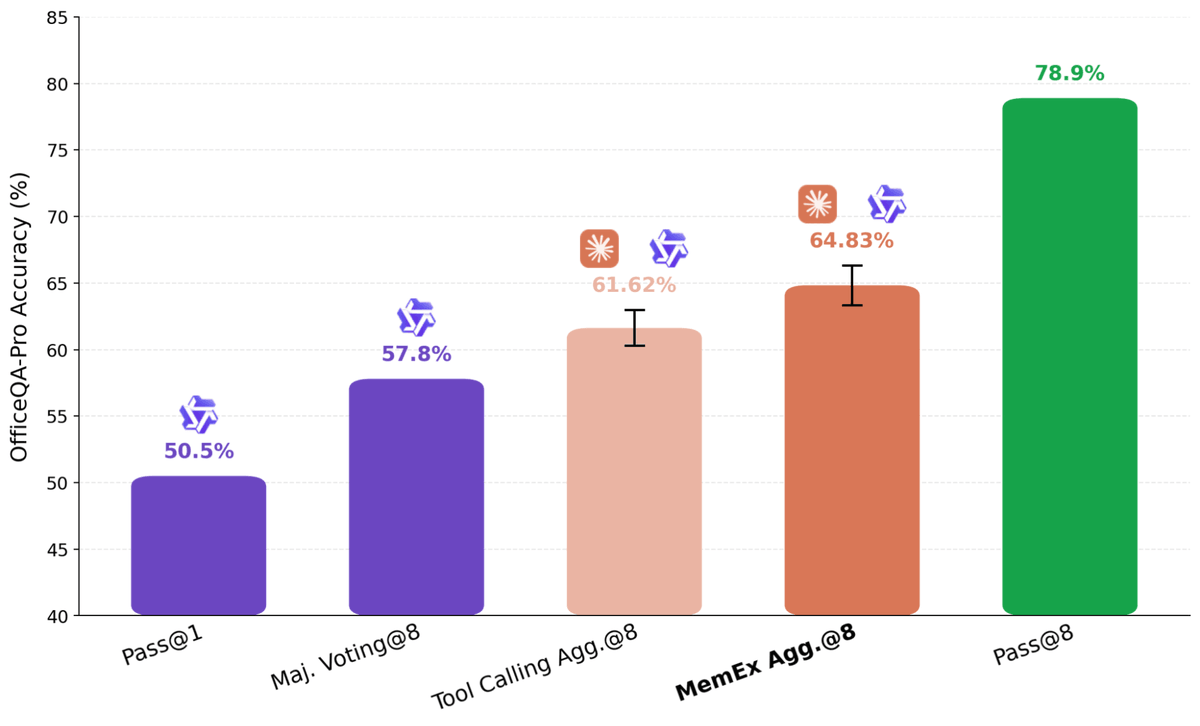
Same pattern for test-time scaling.
We aggregated 8 Qwen rollouts of OfficeQA-Pro. The Tool Calling aggregator worked from lossy summaries (full traces don't fit in context). The MemEx aggregator received the full trajectories as scope variables, and won.
📈 On complex long-horizon enterprise tasks like OfficeQA Pro and Enterprise Structured Retrieval:
Frontier models like Opus 4.6: +5pp at 30% less cost.
OSS like Qwen3.5-122B: doubles, 18% → 36%.
Same agent. Same model. Same tools. Same prompts.
Different action space.
🤖 We ran MemEx on the agents' OWN trajectories.
An audit agent loaded 6 of them (3 MemEx, 3 Tool Calling) into Python scope and classified failure modes.
MemEx had 2x fewer search/execution errors. Retrieval stays in variables, never copied between calls.
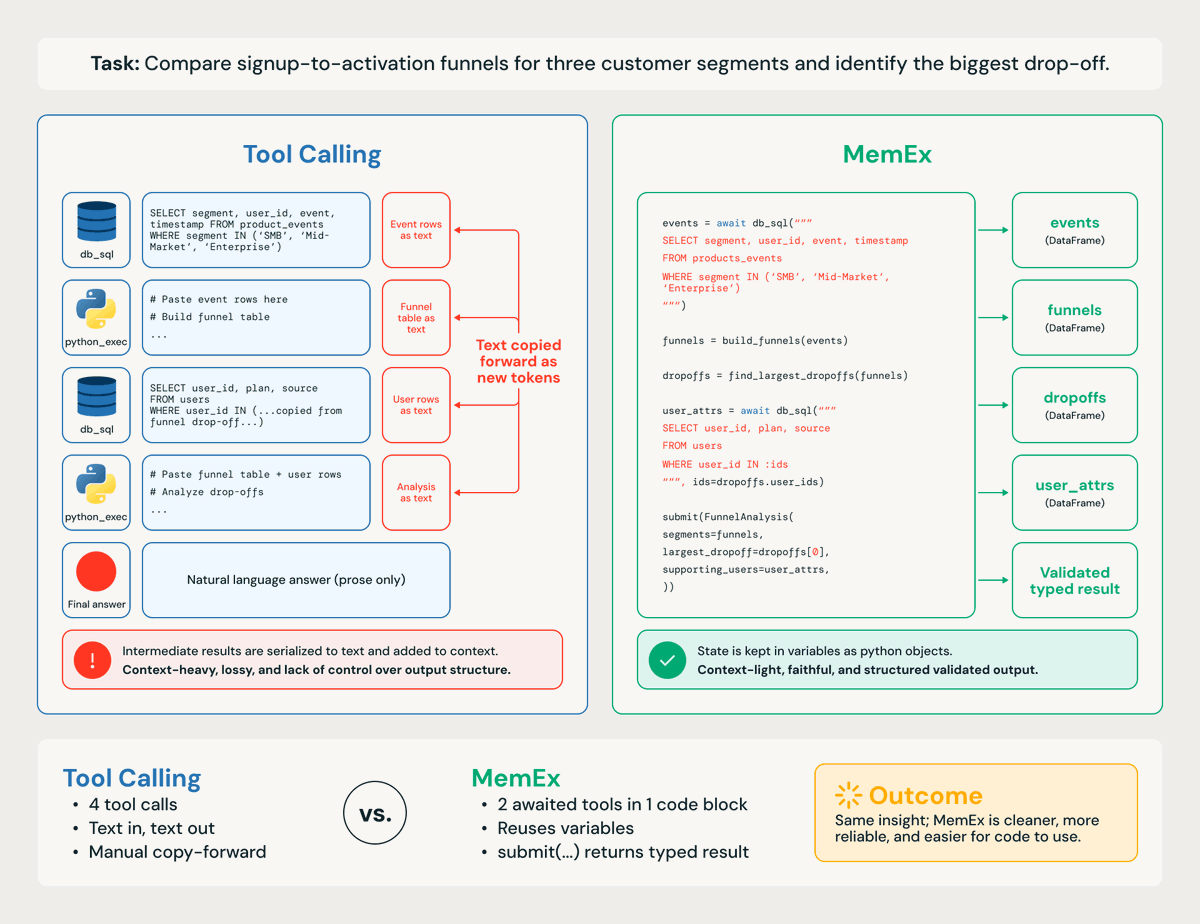
At Databricks, 🧞Genie hits this wall every day!
Its queries span an entire workspace and pulls data from tables, vector indices, and other sources via many tool calls.
Here's how MemEx can convert complex workflows like these into streamlined code with far less token repetition.
In 1945, Vannevar Bush imagined a machine to extend a scientist's memory. He called it the MemEx.
80 years later, we built one for LLM agents.
Tool outputs become Python objects; only print statements reach the model's context.
🧵 https://t.co/YyrGsn3TB7
I'm building a new team at @databricks AI Research and we're hiring.
We're focused on one of the hardest open problems in AI right now: how do you measure and continuously improve agents that operate on enterprise data at scale. We're looking for founding engineers to build the flywheel that turns evaluation results directly into better agents — from development and training all the way to production.
If you want to work on problems that actually matter at the frontier of AI research, I'd love to talk.
Link in comments 👇
🧞 is out of the bottle and answering every enterprise question I throw at it.
The pace of agent development has been incredible @databricks.
Excited for what's next. Lots more to come!
Genie has transformed how Databricks users work with data, with 3x the accuracy of generic agents. We're sharing some of the research behind it and what makes building data agents challenging. Super proud of our research team's impact with this! https://t.co/eLB2ElVo8S
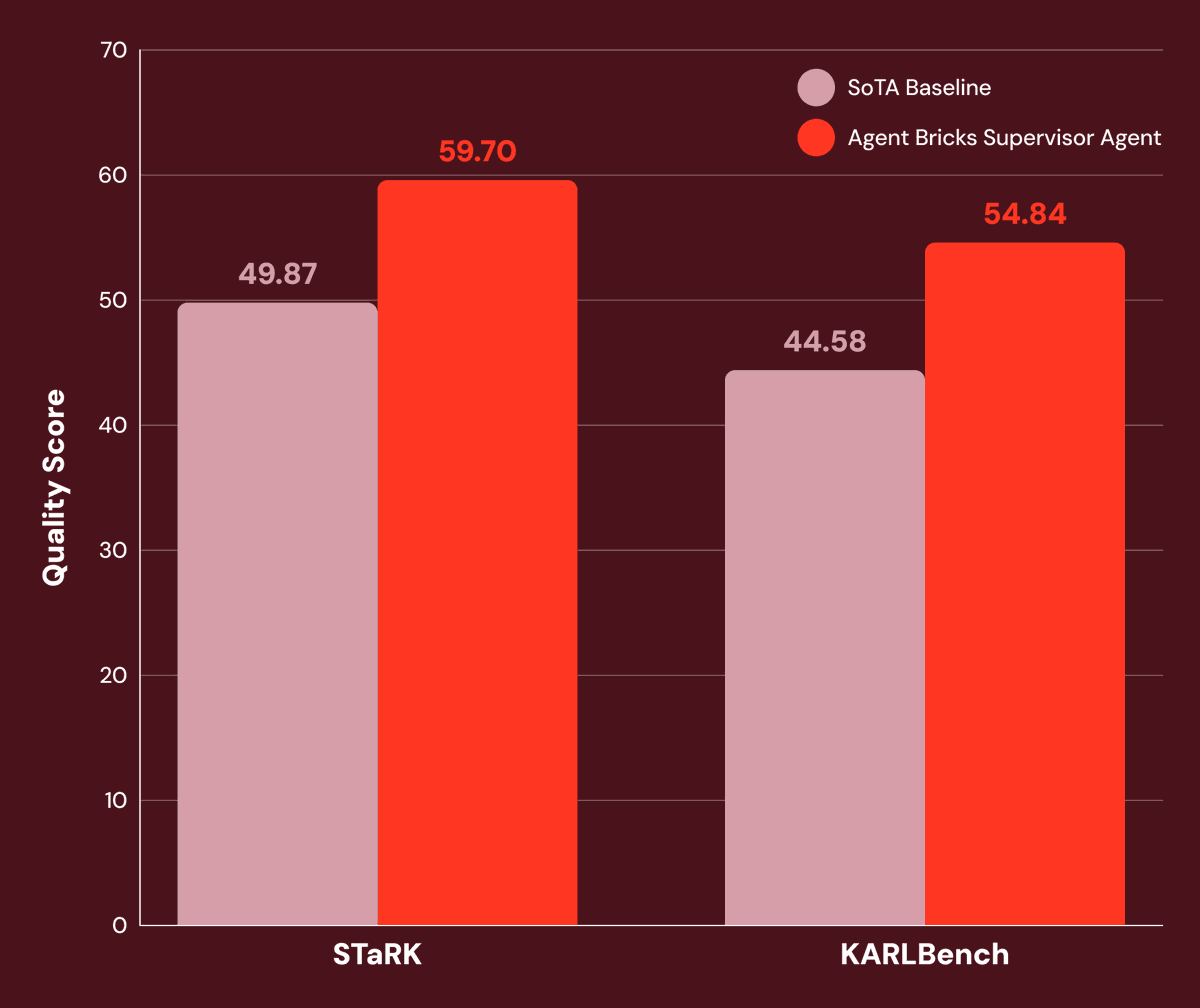
Most enterprise questions don't live in one dataset. They span structured systems and unstructured sources like documents, reviews, and reports.
In our latest research, we show how Agent Bricks Supervisor Agent handles this by decomposing queries across structured and unstructured tools, then synthesizing results over multiple reasoning steps.
The results across STaRK and KARLBench: 20%+ improvement over SoTA baselines, with the biggest gains on tasks requiring tight integration of structured and unstructured data.
All built declaratively — no custom code, just precise instructions and the right tools. https://t.co/EBSM6iU89g
As AI reasoning gets good enough, we think memory will be the next bottleneck for agents. Can your agent improve with more experience?
We call this Memory Scaling, and it's related but different from continual learning. A few examples and challenges:
https://t.co/raIa0U7MPs