Very excited about this line of research of fast-slow learning,
1) potential to solve a lot of issues with current RL (eg. entropy collapse, sparse rewards)
2) an intuitive way of incorporating rich feedback with RL
3) provides a way to transfer knowledge of text-only based learning into the model
4) a great candidate for model-harness co-evolution, seeing a lot discussion on X lately about future models developing their own harness.
5) most importantly, can imagine these kinds of algorithms to be more suitable candidates for discovery that requires both extreme exploration but at the same time improving the underlying model capabilities.
and much more ...
Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls
Physicists are still working on how to make general relativity and quantum mechanics consistent.
But there's one problem where they are confident they've made the two theories work together: how many bits of information can you store in a black hole?
1/ At Eragon, we’re building an AI operating system that connects a company’s entire tech stack into a single interface for work, powered by a model post-trained on the customer’s own data so it understands the company’s unique context.
We believe that AI system post-training shouldn’t have to choose between adapting quickly and learning durably: the future of adaptive AI is fast learning + slow learning:
- fast enough to absorb task-specific lessons
- slow enough to improve without forgetting
Our recent research paper: Learning, Fast and Slow, makes that case.
https://t.co/RG4wKWUk6i
🚀 Organizing the Efficient Qwen Competition @icmlconf !
Goal: Minimize LLM inference latency for a single GPU without breaking model quality.
Prizes: $3K / $2K / $1K + present at ICML 2026, Seoul
Getting Started - https://t.co/On1yK4fnu9
Leaderboard - https://t.co/7HUbO2oA3A
Proud to be part of StreamDiffusionV2!
Streaming video generation opens up a very different -algorithmic-systems codesign problem: low latency, continuous interaction, and maintaining quality over time. Excited to see this direction recognized at #MLSys26!
Excited that our paper StreamdiffusionV2 received the Best Research Paper Award at #MLSys26!
🚀Video generation is quickly moving from demos to production-facing workloads. It is no longer a turn-based pipeline but should be a streaming pipeline to interact with users.
📖Our project page: https://t.co/ItuO5zc6hT and paper: https://t.co/fmz2irYIm1
👂Come join the talk if you are interested in streaming video generation. Our talk will be at the Research Track Oral Presentation: Best Paper Session on Tue 8:45AM at #MLSys26 , I will talk about how we attacked the efficiency and quality challenges. Hope to see you there!
❤️Huge thanks to all authors! This work would not have been possible without the incredible effort from the entire team. Big shout out to Tianrui Feng, Zhi Li, @Andy_ShuoYang , @HaochengXiUCB, @lmxyy1999 , @lvminzhang , @xiuyu_l , Keting Yang, @ZiqiPeng, @songhan_mit , @magrawala, @KurtKeutzer , and @cumulo_autumn
Still there is no restriction stopping us from making heavy edits in the whole context, and thus can expect the model to considerably change its response, whereas we cant do the same in weight space. So in short, we can make large changes in context in one step (no matter how much time it takes to generate that step and how long the context grows).
interesting question, would love to add some nerdy comments, as RA suggests in his post the inspiration of "fast" and "slow" comes from Hinton and Plaut 1987 work, therefore we define "fast" weights as fast moving parameters (can make huge jumps in each update) and "slow" weights as gradually improving parameters (local changes). But one can arbitrarily scale compute in calculating the update for both parameters.
@nicbstme This itself is not enough, you also need to push stuff to weights periodically by retraining on the rollouts and accumulated context. Something like: https://t.co/3bz5KXKyNS
Nice! I've always thought this was one of the foundational principles of biological learning that we've never managed to get right in AI models. This is a nice iteration on how to instantiate the "fast and slow" idea in the modern LLM world that seems to work pretty well!
Thanks for sharing, I agree with the motivations and ideas you mentioned, for better understanding it can be seen as FST instantiation where:
*slow weights* update rule = self distillation
*fast weights* update rule = GEPA
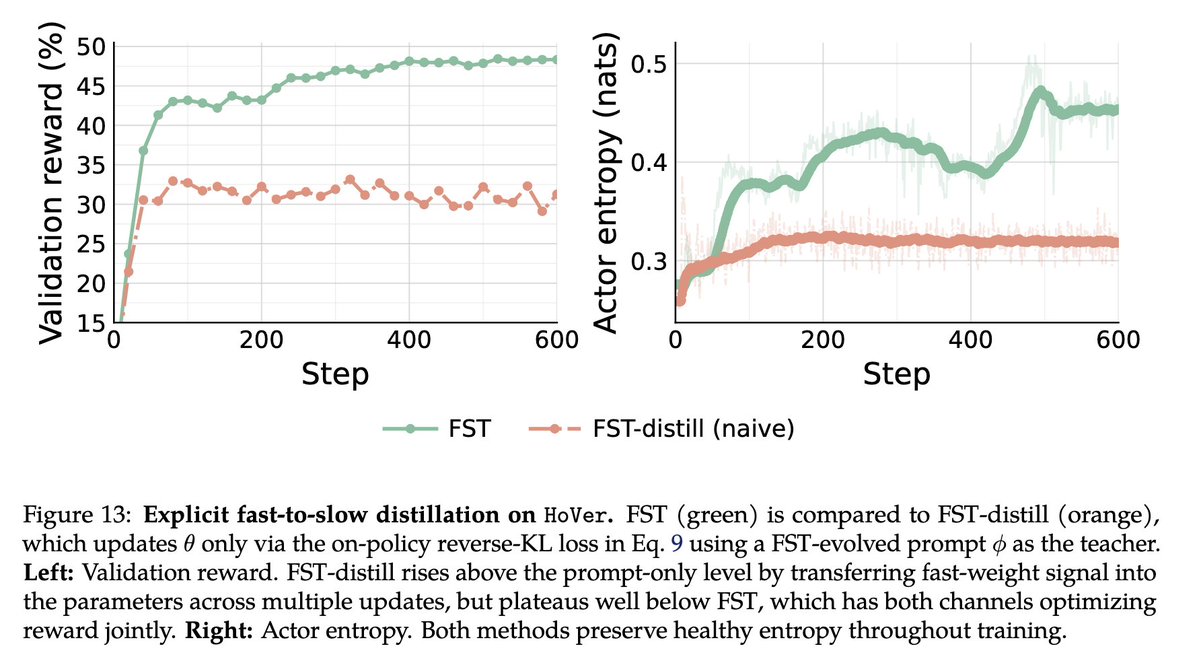
we did try one experiment in the same spirit in which we distilled FST fast-weights (gepa style prompt) back to the model using on-policy reverse KL (similar to SDFT paper) and leads to some learning but performs worse than FST w/ GEPA+RL (@LakshyAAAgrawal explained this result in more detail here: https://t.co/KLQWHv9WgE).
The idea of combining RLVR signal with self distillation signal is also very interesting and we did try that as well some time back in a related project, we are planning to release that as well soon.
ICL lets models adapt rapidly to changing tasks (✅), but the weights stay frozen - leaving performance gains on the table (⚠️).
Fine-tuning (like SFT, RL) reaches a higher perf ceiling (✅), but is slow, can hurt OOD performance, and often reduces plasticity (⚠️).
Why not combine the strengths (✅) of both?
We introduce Fast-Slow Training (FST): fast weights (prompts) quickly capture task-specific nuances, while slow weights (model parameters) internalize the more general, task-agnostic reasoning patterns that should persist across tasks.
FST reaches a higher perf asymptote while being more efficient. Since prompts absorb more of the task-specific information, the parameters do not need to move as much. As a result, the model stays closer to the base model, and preserves more plasticity for learning new tasks!
Training LLMs is synonymous with updating their weights. However, LLMs can also learn in-context using *frozen* weights. There is no good reason for restricting learning to being in-context or in-weights.
So a natural idea is "Learning, Fast and Slow" (FST). In FST, slow learning is LLM weights trained with RL while fast learning is context / prompt (fast weights) optimized with GEPA.
Compared to RL, FST performs better while being more data efficient, adaptable (plasticity), and forgetting less (stays closer to base models).
I think this idea of learning both fast-slow weights would be a good foundation for continual learning.
PS: Geoff Hinton (the OG) described the idea of fast weights and slow weights several years ago, and back then I remember thinking it's a very cool idea.
See more details here:
https://t.co/FACsHx7IpK
Very excited about this line of research of fast-slow learning,
1) potential to solve a lot of issues with current RL (eg. entropy collapse, sparse rewards)
2) an intuitive way of incorporating rich feedback with RL
3) provides a way to transfer knowledge of text-only based learning into the model
4) a great candidate for model-harness co-evolution, seeing a lot discussion on X lately about future models developing their own harness.
5) most importantly, can imagine these kinds of algorithms to be more suitable candidates for discovery that requires both extreme exploration but at the same time improving the underlying model capabilities.
and much more ...
Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls
Your RL post-training should co-evolve with prompt optimization, not run before it.
New paper out of Berkeley — Fast-Slow Training (FST). 3× more sample efficient than RL alone. 70% less KL drift. And the first continual learning result that actually holds: