Out of all the announcements at @Google I/O today, this is the one closest to my heart - our foundational research on Co-Scientist was published in @Nature and we announced its broad availability via @GeminiApp for Science.
When you are suffering from a disease, time is everything. As our collaborator and @StanfordMed Professor Dr. Gary Peltz reminds us, there are thousands of diseases out there with zero treatments. There is simply so much left to solve.
Our goal with Co-Scientist has been to give scientists superpowers and help them get to these answers faster - compressing the scientific process from months and years down to hours and days.
Much like Galileo's telescope helped us look into the stars, Co-Scientist is designed to help us make sense of the vast complexity of biological and scientific data. It is among the first examples of a truly general-purpose multi-agent system for scientific discovery.
The core research question behind it was: How can an AI system engage in the rigorous, structured thinking that’s the hallmark of science and scientists?
To tackle this, Co-Scientist builds on the principles of self-play and self-improvement underpinning @GoogleDeepMind breakthroughs like AlphaGo, generalizing them to scientific reasoning through self-debates.
Since our preprint last year, we have further improved its capabilities and have been validating it in collaborations with scientists across over 100 institutions globally, spanning both academia and industry.
And we are thrilled to see the emergence of a new form of AI-human scientist collaboration that's already leading to important new insights, discoveries and peer reviewed publications - from understanding antimicrobial resistance (published in @CellCellPress) to decoding plant immunity, to identifying new treatments for liver fibrosis (Advanced Science), cancer, neurodegenerative diseases like ALS and the grand challenge of aging.
I have always believed AI's greatest promise is accelerating scientific discovery and advancing human health.
My genuine hope for the future is that AI tools like Co-Scientist help democratize science, giving anyone, anywhere the means to pursue their child-like curiosity and change the world.
This work was done with stellar team mates spanning @GoogleDeepMind@GoogleResearch, @googlecloud and @GoogleLabs especially Juro Gottweis (@Mysiak ), who is the heart and soul of this effort.
Special thanks also to all our wonderful collaborators: Gary Peltz, @CostaT_Lab, @jrpenades, @_e_d_v_ , @iambyronic, @OpsBug, @jgooten, @omarabudayyeh Ritu Raman, Ryan Flynn, Filippo Menolascina, Velia Siciliano, Clare Bryant, Matt Onsum, Katherine Labbé and more.
Nature paper link - https://t.co/ap4woY9Fo3
Google DeepMind blog - https://t.co/LLJZ27ufPP
Gemini for Science - https://t.co/lDhsHCCXrj.
Welcome to Gemini 3.5 Flash, our most powerful model to date. It pushes the frontier of intelligence, speed, and cost putting 3.5 Flash in a class of its own.
We spent the last 6 months making sure Flash is great for real world use cases. It's available everywhere now!
2/
Check out how Gemini 3.5 Flash instantly digests dense academic papers and autonomously codes a fully interactive, visual website explaining the intricacies of the research. It's an incredible stress test that seamlessly merges massive long context, deep reasoning, complex coding, and ultra-low latency.
It really helps you distill papers down to their essence and aid your understanding!
1/ Today at #GoogleIO, we’re releasing Gemini 3.5, our latest family of models combining frontier intelligence with action.
We’re starting by releasing 3.5 Flash, which is built to help you execute complex, long-horizon agentic workflows.
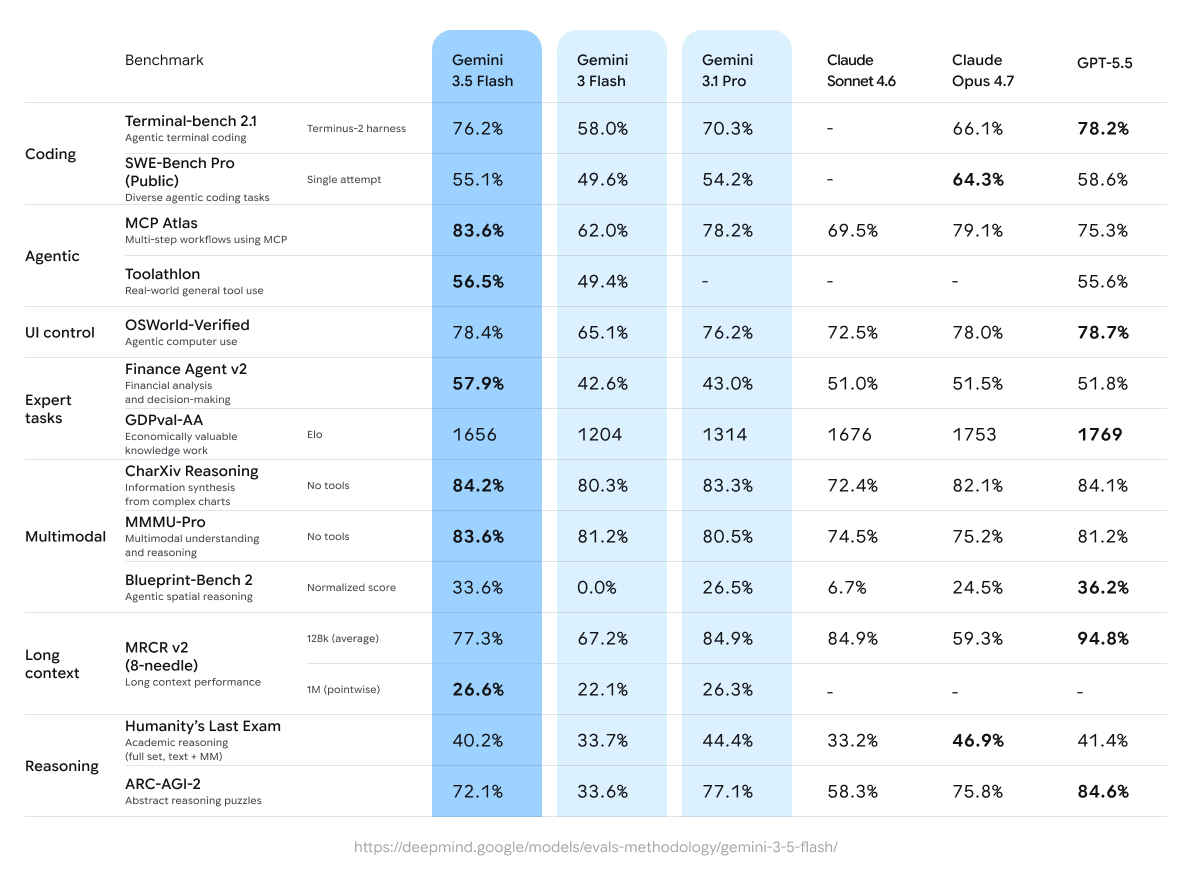
Gemini 3.5 Flash is our strongest model for coding and agent https://t.co/m62cBJhIjJ outscores 3.1 Pro on agentic and coding benchmarks like Terminal-Bench and MCP Atlas, while running 4x faster than other frontier models.
Used in Google Antigravity, 3.5 Flash is even further optimized to be up to 12x faster. It’s a powerful engine to deploy sub-agents that collaborate, run high-frequency iterative loops, and solve real-world problems at scale.
Some highlights we’re excited about 🔽
Training LLMs is synonymous with updating their weights. However, LLMs can also learn in-context using *frozen* weights. There is no good reason for restricting learning to being in-context or in-weights.
So a natural idea is "Learning, Fast and Slow" (FST). In FST, slow learning is LLM weights trained with RL while fast learning is context / prompt (fast weights) optimized with GEPA.
Compared to RL, FST performs better while being more data efficient, adaptable (plasticity), and forgetting less (stays closer to base models).
I think this idea of learning both fast-slow weights would be a good foundation for continual learning.
PS: Geoff Hinton (the OG) described the idea of fast weights and slow weights several years ago, and back then I remember thinking it's a very cool idea.
See more details here:
https://t.co/FACsHx7IpK
ICL lets models adapt rapidly to changing tasks (✅), but the weights stay frozen - leaving performance gains on the table (⚠️).
Fine-tuning (like SFT, RL) reaches a higher perf ceiling (✅), but is slow, can hurt OOD performance, and often reduces plasticity (⚠️).
Why not combine the strengths (✅) of both?
We introduce Fast-Slow Training (FST): fast weights (prompts) quickly capture task-specific nuances, while slow weights (model parameters) internalize the more general, task-agnostic reasoning patterns that should persist across tasks.
FST reaches a higher perf asymptote while being more efficient. Since prompts absorb more of the task-specific information, the parameters do not need to move as much. As a result, the model stays closer to the base model, and preserves more plasticity for learning new tasks!
Q1 earnings are in: 2026 is off to a terrific start.
Our AI investments and full stack approach are lighting up every part of the business: Search queries are at an all-time high with AI continuing to drive usage. Google Cloud revenue grew 63%, Gemini models have incredible momentum, and it was our strongest quarter ever for consumer AI subs, driven by @GeminiApp.
Thanks to our partners + employees around the world. Much more to share on our earnings call in 20 minutes… and at Google I/O in 20 days!
Very cool long-context scaling work!
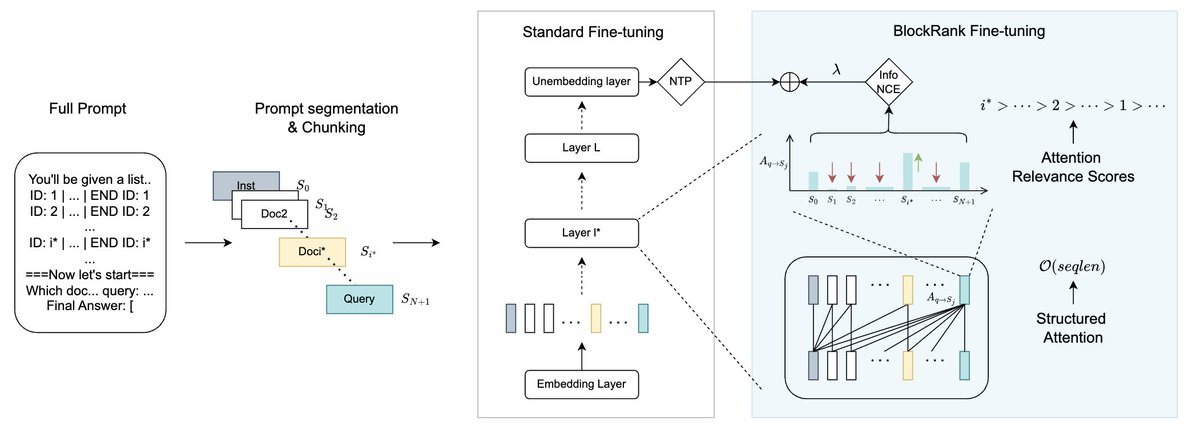
Glad to see BlockRank (https://t.co/vwQc3kzfUk) ideas in the paper - (a) contrastive L_aux; (b) document-wise block sparse attention; (c) per-document position encodings. The scale of MSA is def a step above and has more well executed ideas for scaling (topk attention routing, better training recipe)!
Congratulations to Charles H. Bennett (@IBMResearch) and Gilles Brassard ( @UMontreal) on receiving the 2025 ACM A.M. Turing Award!
🔗: https://t.co/UQ5C1K1kVT
@dem_fier@hugo_larochelle Nice! The tool would be even more helpful if it summarizes how the paper is relevant, and cites it properly. I find that 90% of paper citations have a very superficial reason to cite.
Excited for this promising start in extremal graph theory, building on our earlier work using AlphaEvolve for complexity theory for the TSP and other problems https://t.co/elcISfjtW1
Our graph constructions for these improved bounds are available at GitHub:
https://t.co/huOdB9itZi
Read the full working paper here: https://t.co/n9WywhyDLY
Happy to share new progress in AI for Maths @GoogleDeepMind .
In extremal combinatorics, AlphaEvolve has helped establish new lower bounds for FIVE classical Ramsey numbers - a problem so challenging that even Erdős commented on its difficulty.
Historically, computationally deriving these bounds required bespoke, human-designed search algorithms. For many of these bounds, the best previous results are at least a decade old. AlphaEvolve changes this by acting as a single meta-algorithm that automatically discovers the search procedures needed to find these new bounds. 📷
🚀 Today we’re releasing FlashOptim: better implementations of Adam, SGD, etc, that compute the same updates but save tons of memory. You can use it right now via `pip install flashoptim`. 🚀
https://t.co/nRrLSpjnwV
A bunch of cool ideas make this possible: [1/n]
A new era for Waymo. We’ve raised $16B to accelerate our mission, valuing the company at $126B. This capital is an investment in a future where more cities get a safer, more reliable way to move. Let's go. 🚀 https://t.co/UPBroOeWcR






















![davisblalock's tweet photo. 🚀 Today we’re releasing FlashOptim: better implementations of Adam, SGD, etc, that compute the same updates but save tons of memory. You can use it right now via `pip install flashoptim`. 🚀
https://t.co/nRrLSpjnwV
A bunch of cool ideas make this possible: [1/n] https://t.co/xeaMyWztpv](https://pbs.twimg.com/media/HCgxeDgawAEzt6q.jpg)





























