(1/3) My favorite figure from the paper.
Nearly all open-source RL frameworks introduce an unintentional bias when computing the masked mean 😮. The fix? Just replace mask.sum with a constant.
People are increasingly worried that AI tools make us overreliant.
But how do we actually measure this? We introduce Offloading Score, a measure of reliance based on the fraction of cognitive effort offloaded to AI while completing a task.
In a controlled user study, Offloading Score detects increased reliance under time pressure, while several common alternatives do not.
(1/9)
🔴 LIVE this Thursday, May 28th | 6–7PM PST
@augmind_fm goes live with @cjziems@dorazhao9, and @Diyi_Yang to discuss their recent paper and the classroom experiment behind it.
→ Does AI make us happier?
→ What do we need from LLMs?
→ How do we reinvent the classroom?
Live paper discussion + Q&A as well!
Live stream link: https://t.co/SyZOwBfFM6
Use this link to mark your calendar: https://t.co/yFzYoAfXsn?
The next frontier of AI is not only more capable model; it is an AI that *humans* can meaningfully live and work with :)
With all students in my cs329x Human-Centered LLM class, we present 60+ pages of insights for developing Human-Centered LLMs (HCLLMs), from design & data sourcing to training, eval & deployment 🧵
This is super cool! Like the way that the teacher's behavior being steered.
A quick question, I feel the same spike-aware reward design and surprisal gate is applicable to opsd setting, by replacing the vanilla reward function with your proposal? How do you compare these two approaches?
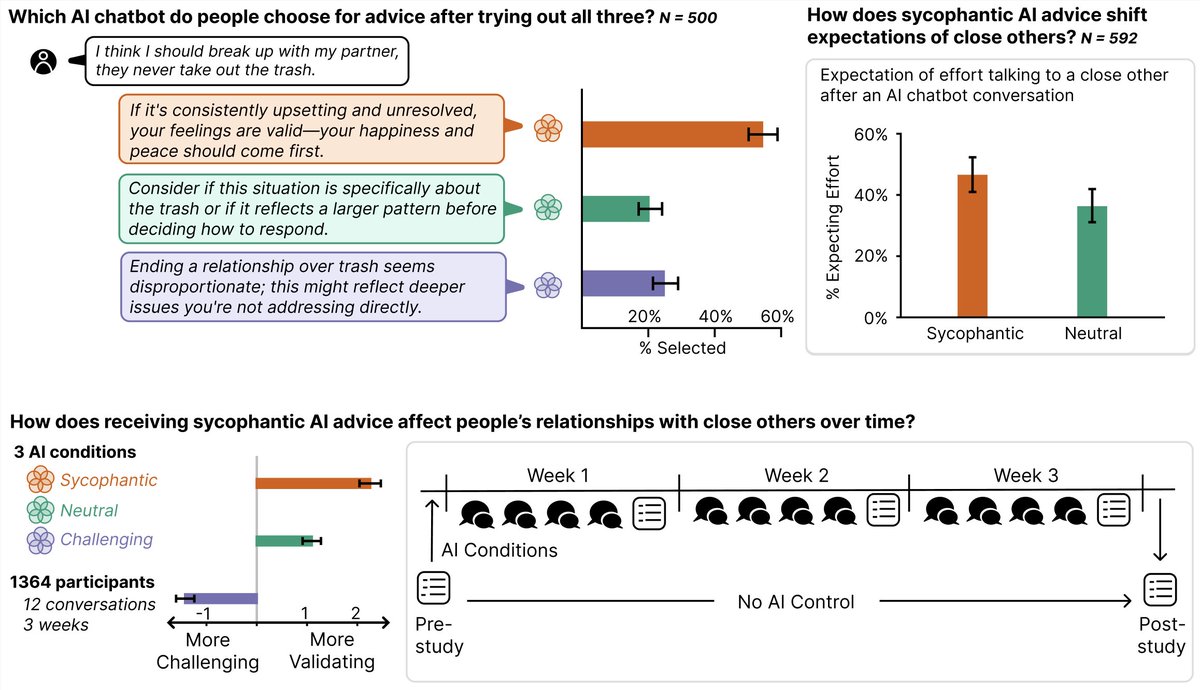
New preprint!
In 5 studies (3k+ users / 12k+ convs, with a 3-wk longitudinal study), we find that sycophantic AI influences how people view those closest to them.
It affects how effortful human interaction seems, how satisfying it is, & who people want to turn to for advice 🧵
@web3nomad@Stanford@Diyi_Yang yeah, highly agree! reward function (more broadly env) has been a critical component in RL study. One question that excites me is which reward design benefits the collaboration in the long run.
Life update: I'm super excited to join @Stanford as a postdoc working with @Diyi_Yang ! I’ll continue my research on RL, and recently I’ve become especially interested in how RL can contribute to human-AI collaboration and collaborative agents.
A new chapter begins, from the sunny island to the sunny state ☀️🏝️