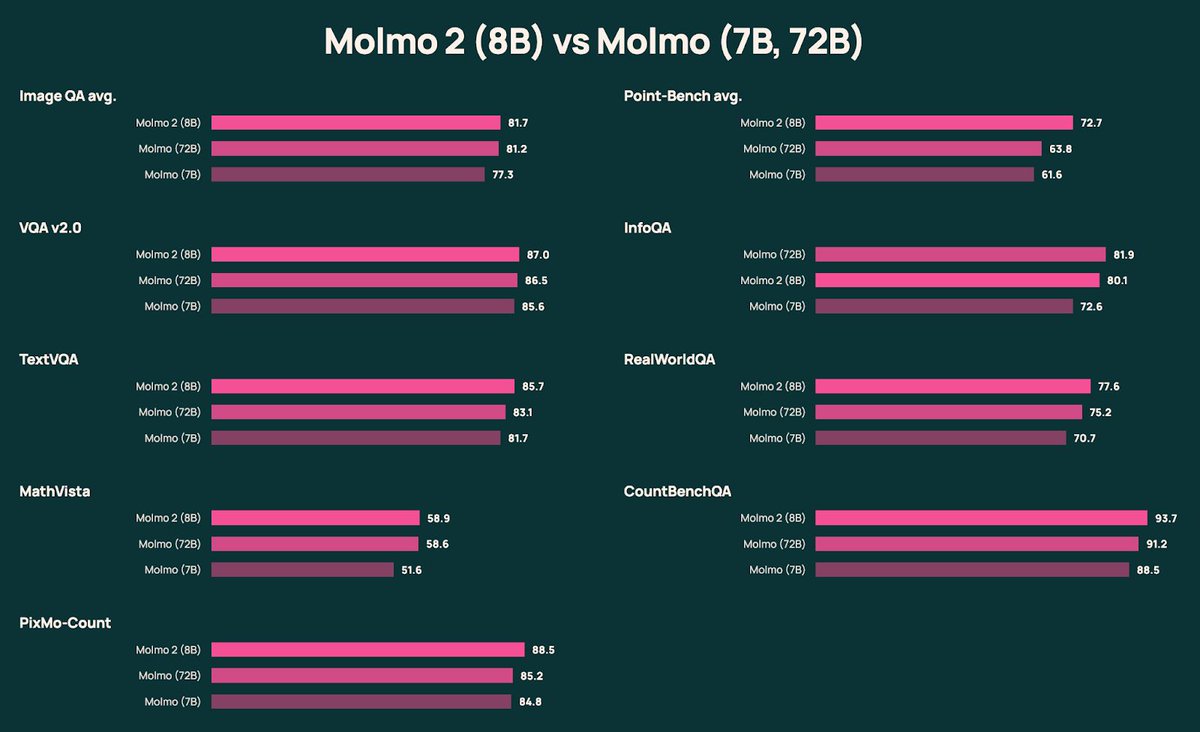
Last year Molmo set SOTA on image benchmarks + pioneered image pointing. Millions of downloads later, Molmo 2 brings Molmo’s grounded multimodal capabilities to video 🎥—and leads many open models on challenging industry video benchmarks. 🧵
📢Applications are open for summer'25 internships at the PRIOR (computer vision) team
@allen_ai:
Come join us in building large-scale models for:
📸 Open-source Vision-Language Models
💻 Multimodal Web Agents
🤖 Embodied AI + Robotics
🌎 Planet Monitoring
Apply by December 11, 2024!
This (& graduation) happened last week & I am a (fake) Dr. now!
I owe it all to my advisors, mentors, collaborators, friends, and family! -- I wrote a 6-page acknowledgment in my thesis without realizing😅
Thanks for all the fish @uwcse, @RAIVNLab, @uw_wail & @GoogleDeepMind🪆
Excited to introduce GPT-4o.
Language, vision, and sound -- all together and all in real time.
This thing has been so much fun to work on. It's been even more fun to play with -- with moments of magic where things feel totally fluid and I forget I'm video chatting with an AI.
🎉 Very Excited to present our recent work on “Selective🔍 Visual Representations for Embodied-AI🤖” next week at ICLR in Vienna🇦🇹!!
📣📣Important update! Our code and pretrained models are now available through our project website 🌐: https://t.co/LpojdZrFZn🚀
👋Come to my poster, say hi, and learn more about our findings! (Poster #111, Session 8, on Friday, May 10th at 4:30 PM)
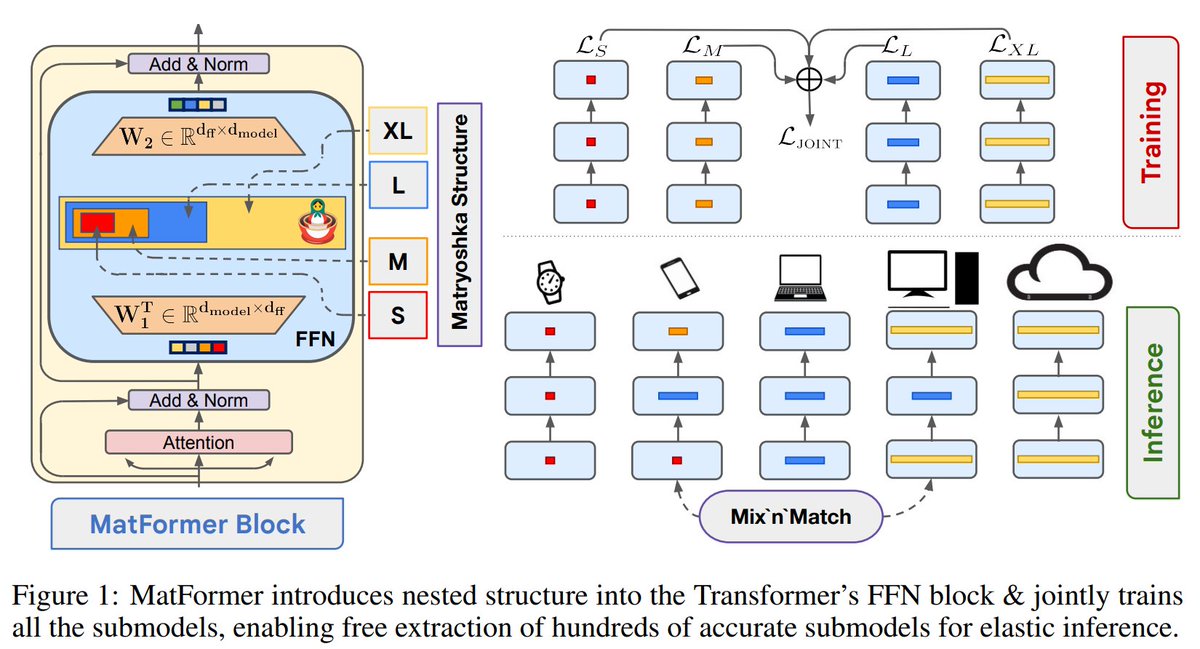
Check out🪆MatFormer🪆co-led by @adityakusupati: it’s a simple yet powerful general-purpose architecture with flexibility and elasticity built within. It works across modalities and enables super cool things at web-scale tasks🔥🔥
Announcing MatFormer - a nested🪆(Matryoshka) Transformer that offers elasticity across deployment constraints.
MatFormer is an architecture that lets us use 100s of accurate smaller models that we never actually trained for!
https://t.co/wzR7To7HZu 1/9
E) The attention logit growth instability is still present when replacing softmax with pointwise alternatives.
Side note: If you're interested in learning more about replacing softmax with a pointwise alternative like relu^2/√seqlen, checkout https://t.co/dDZZjxblSr!
(12/15)
Sharing some highlights from our work on small-scale proxies for large-scale Transformer training instabilities: https://t.co/mCNFJYO2z8
With fantastic collaborators @peterjliu, @Locchiu, @_katieeverett, many others (see final tweet!), @hoonkp, @jmgilmer, @skornblith!
(1/15)
🚨Is it possible to devise an intuitive approach for crowdsourcing trainable data for robots without requiring a physical robot🤖?
Can we democratize robot learning for all?🧑🤝🧑
Check out our latest #CoRL2023 paper->
AR2-D2: Training a Robot Without a Robot
Have vision-language models achieved human-level compositional reasoning? Our research suggests: not quite yet.
We’re excited to present CREPE – a large-scale Compositional REPresentation Evaluation benchmark for vision-language models – as a 🌟highlight🌟at #CVPR2023.
🧵1/7
Introducing💃AdANNS: A Framework for Adaptive Semantic Search🕺
TL;DR: Up to 90× faster nearest neighbor retrieval and 2× lower memory cost for web-scale search.
Applies to vector search at scale & improves all "retrieval" augmented models!
https://t.co/yEnrr4oCwa
[1/8]
Introducing💃AdANNS: A Framework for Adaptive Semantic Search🕺
TL;DR: Up to 90× faster nearest neighbor retrieval and 2× lower memory cost for web-scale search.
Applies to vector search at scale & improves all "retrieval" augmented models!
https://t.co/yEnrr4oCwa
[1/8]
1/9 I am excited to announce that our workshop "Towards the Next Generation of Computer Vision Datasets" will be happening at ICCV 2023 in Paris. We will feature DataComp submissions, other data-centric papers, and invited talks by experts. https://t.co/mMY0OOHLro
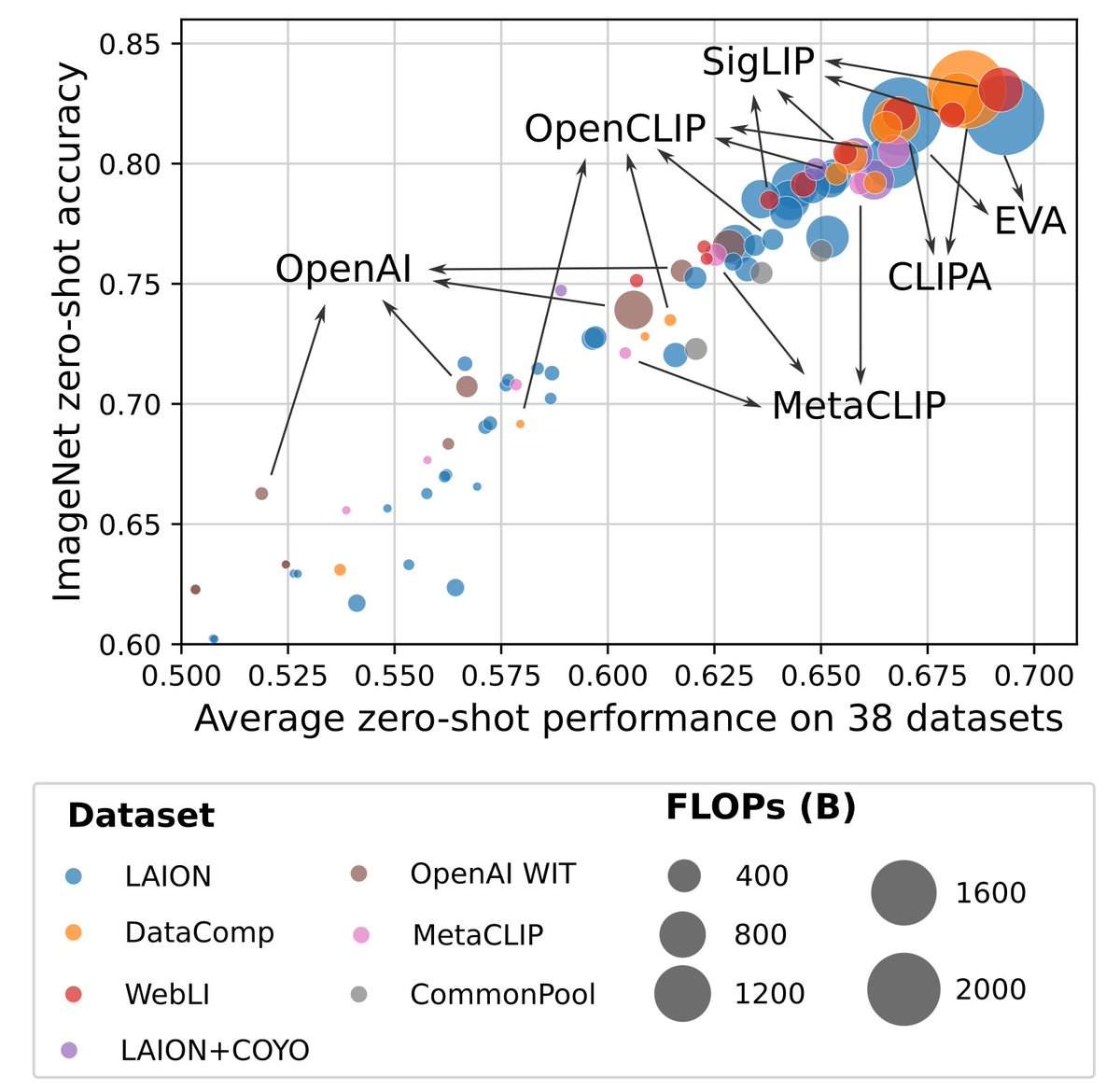
Introducing DataComp, a new benchmark for multimodal datasets!
We release 12.8B image-text pairs, 300+ experiments and a 1.4B subset that outcompetes compute-matched CLIP runs from OpenAI & LAION
📜 https://t.co/nz4I9Xwt8e
🖥️ https://t.co/XcAlKmMW1G
🌐 https://t.co/Um7OjgvGlA
Introducing DataComp, a new benchmark for multimodal datasets!
We release 12.8B image-text pairs, 300+ experiments and a 1.4B subset that outcompetes compute-matched CLIP runs from OpenAI & LAION
📜 https://t.co/nz4I9Xwt8e
🖥️ https://t.co/XcAlKmMW1G
🌐 https://t.co/Um7OjgvGlA
























![adityakusupati's tweet photo. Introducing💃AdANNS: A Framework for Adaptive Semantic Search🕺
TL;DR: Up to 90× faster nearest neighbor retrieval and 2× lower memory cost for web-scale search.
Applies to vector search at scale & improves all "retrieval" augmented models!
https://t.co/yEnrr4oCwa
[1/8] https://t.co/TXAnpleEpB](https://pbs.twimg.com/media/Fyb5TCCaAAEugwf.jpg)






























