@_arohan_ It was a fun time. We pipelined 8 gpu (k20?) , yolo one cifar10 run, babysit for a month(!) via tensorboard. Now it feels scary, multi epoch, no skip connection , sgd, no clipping, no weight decay
@TheGregYang In my case, it correlates with exercise / sleep quite well ; exercise helps to improve both. Magnesium also boost hrv for 3-5 pts for me. No alcohol also helps 😂
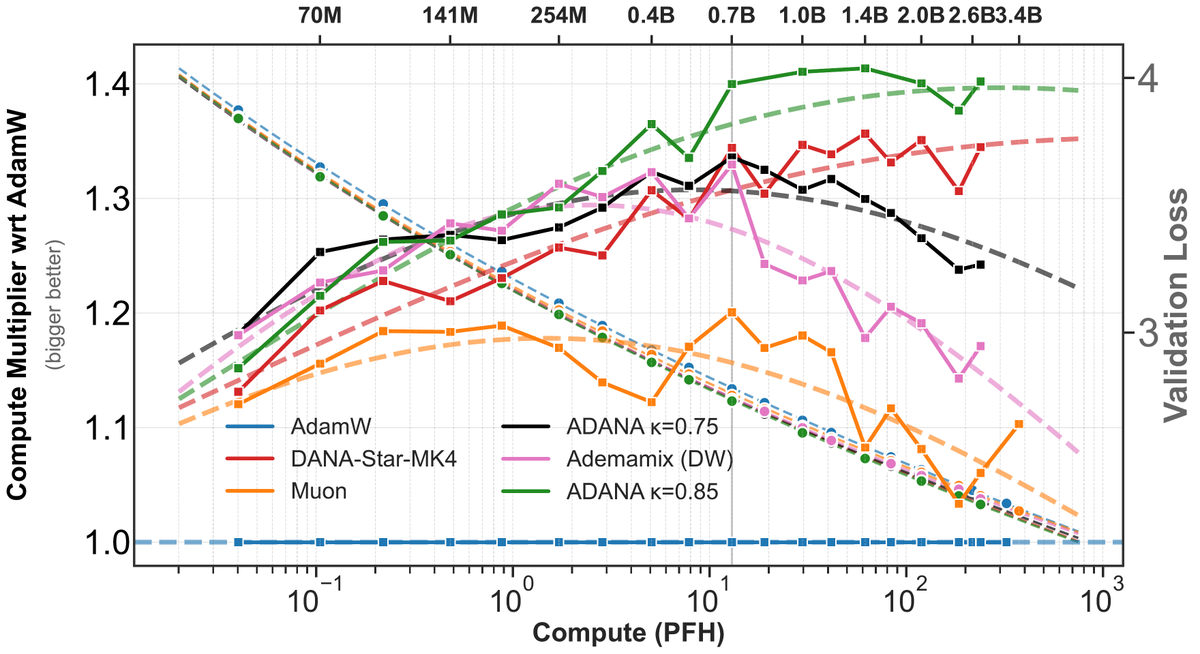
1/10 We built ADANA, an optimizer that gets better as you scale.
It extends AdamW with log-time schedules for momentum and weight decay — same hyperparameter count, no extra engineering. Scaled from 45M to 2.6B, it saves ~40% compute vs tuned AdamW, and the gap keeps growing.🧵
Mathematicians 🤝AI researchers https://t.co/5AvHC0Stin. Our take on AI solving Erdos problems:
* Many "Open" problems are actually just obscure: many cases the AI didn't find something new, only rediscovered solutions buried in the literature. We present our systematic approach to reporting AI results on Erdos.
* The real bottleneck is still human labor, e.g. we spent lots of time filtering out technically correct but meaningless solutions (AI missed Erdos’s original intent).
* Acceleration in solving low-hanging fruits is real, but we also need to highlight the many more misses that require human auditing. Clear research directions ahead though, and we feel optimistic about drastically increasing the signal-to-noise ratio.
More to come!
@peterjliu ”My preference would still be for the final writeup for this result to be primarily human-generated in the most essential portions of the paper, though I can see a case for delegating routine proofs to some combination of AI-generated text and Lean code. But to me, the ... ”
I am hiring a student researcher to work with our team in Montreal on LLMs architecture and pre-training in spring-summer 2026, if you're excited to push the frontier of research forward, join us to help keeping the TPUs warm.
fill out this form:
https://t.co/q8R3tPJkSV