Sharing some highlights from our work on small-scale proxies for large-scale Transformer training instabilities: https://t.co/mCNFJYO2z8
With fantastic collaborators @peterjliu, @Locchiu, @_katieeverett, many others (see final tweet!), @hoonkp, @jmgilmer, @skornblith!
(1/15)
Very excited to finally release our paper for OpenThoughts!
After DataComp and DCLM, this is the third large open dataset my group has been building in collaboration with the DataComp community. This time, the focus is on post-training, specifically reasoning data.
Introducing the next generation: Claude Opus 4 and Claude Sonnet 4.
Claude Opus 4 is our most powerful model yet, and the world’s best coding model.
Claude Sonnet 4 is a significant upgrade from its predecessor, delivering superior coding and reasoning.
Excited to share that I'll be joining @Anthropic to work on pretraining science! I've chosen to defer my Stanford PhD, where I'm honored to be supported by the Hertz Fellowship.
There's something special about the science, this place, and these people. Looking forward to joining some of my most brilliant and compassionate colleagues!
Many agents (Claude Code, Codex CLI) interact with the terminal to do valuable tasks, but do they currently work well enough to deploy en masse?
We’re excited to introduce Terminal-Bench: An evaluation environment and benchmark for AI agents on real-world terminal tasks. Tl;dr lots of room for improvement! https://t.co/qEczwCmyoQ
Excited to be presenting at #ICLR2025 at 10am today on how generative classifiers are much more robust to distribution shift. Come by to chat and say hello!
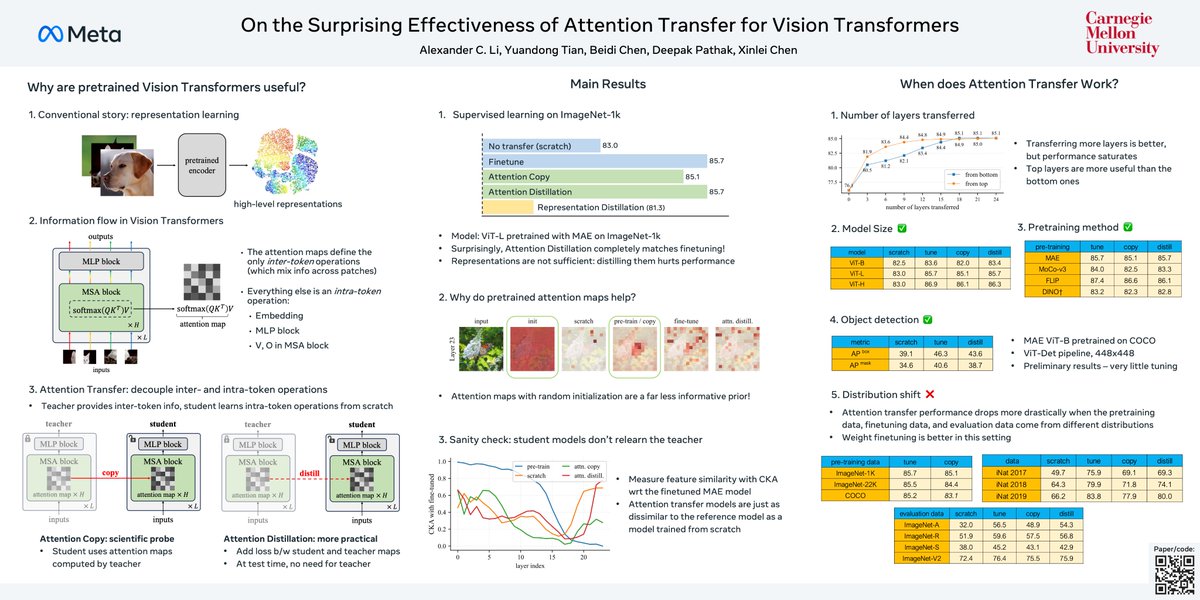
I'm presenting our #NeurIPS2024 work on Attention Transfer today!
Key finding: Pretrained representations aren't essential - just using attention patterns from pretrained models to guide token interactions is enough for models to learn high-quality features from scratch and match ImageNet performance! 🤯
Chat with me and @endernewton Dec 12 (today), 4:30 -7:30 pm PST, East Exhibit Hall #1900
🚨 I’m on the job market this year! 🚨
I’m completing my @uwcse Ph.D. (2025), where I identify and tackle key LLM limitations like hallucinations by developing new models—Retrieval-Augmented LMs—to build more reliable real-world AI systems. Learn more in the thread! 🧵
I'm on the academic job market!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!
Introducing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. We’re also introducing a new capability in beta: computer use.
Developers can now direct Claude to use computers the way people do—by looking at a screen, moving a cursor, clicking, and typing text.
OpenCLIP passed 10K stars on GitHub this week. A big milestone for any open-source project. 🍻 to the many collaborators that made that possible. Coincidentally, I pushed a new release with a port of the largest multi-lingual SigLIP -- a SO400M/16 @ 256x256 that appeared on big_vision a little while back.
Now on the @huggingface hub and useable via timm or OpenCLIP (update your timm too)! https://t.co/mfHsKFjvnk
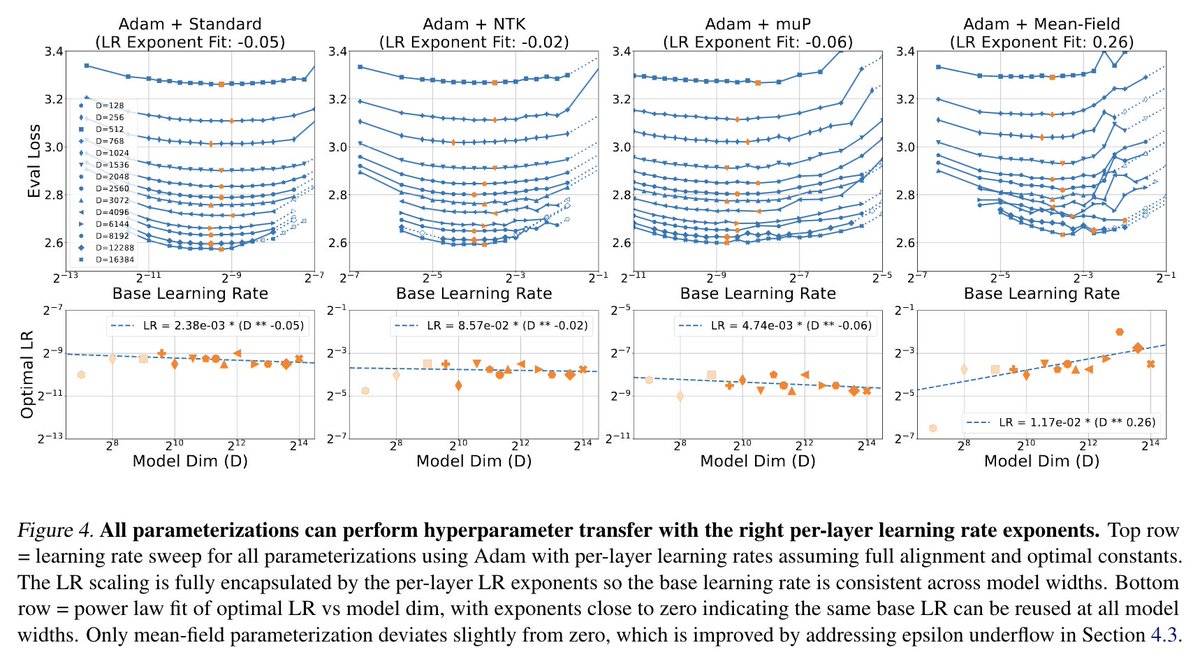
Come chat with me and @Locchiu at our ICML poster session 1:30-3pm CEST (Vienna time) today at Hall C 4-9 #2500 and see how our theory lets all parameterizations perform hyperparameter transfer!
https://t.co/It6ZvywPuI
We have released our DCLM models on huggingface! To our knowledge these are by far the best performing truly open-source models (open data, open weight models, open training code) 1/5
We've gotten some great questions about the notion of alignment in our width-scaling parameterization paper! https://t.co/It6Zvyxnkg
A deep dive into the alignment metric and intuition 🧵 [1/16]
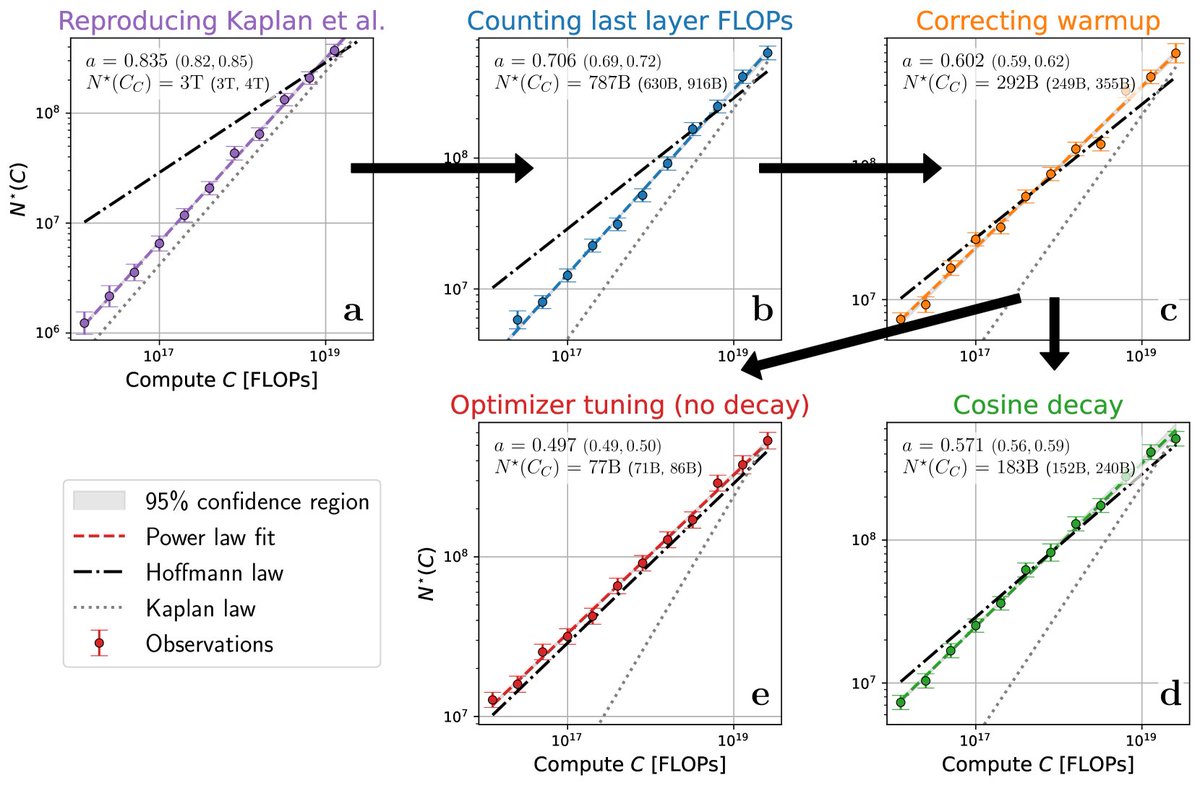
🧵1/8 We resolve the discrepancy between the compute optimal scaling laws of Kaplan (exponent 0.88, Figure 14, left) et al. and Hoffmann et al. (“Chinchilla”, exponent 0.5).
Paper: https://t.co/QKFbNl4J9t
Data + Code: https://t.co/N3p0Xg0THH
We're also launching a preview of Artifacts on https://t.co/uLbS2JMEK9.
You can ask Claude to generate docs, code, mermaid diagrams, vector graphics, or even simple games.
Artifacts appear next to your chat, letting you see, iterate, and build on your creations in real-time.
Introducing Claude 3.5 Sonnet—our most intelligent model yet.
This is the first release in our 3.5 model family.
Sonnet now outperforms competitor models on key evaluations, at twice the speed of Claude 3 Opus and one-fifth the cost.
Try it for free: https://t.co/uLbS2JMEK9
Thrilled to share our paper “Large-Scale Transfer Learning for Tabular Data via Language Modeling,” introducing TabuLa-8B: a foundation model for prediction on tabular data.
(with Juan C Perdomo + @lschmidt3)
📖 https://t.co/9Av649FWm6
🌐 https://t.co/wfIhEgDHC6
[long🧵]










![_katieeverett's tweet photo. We've gotten some great questions about the notion of alignment in our width-scaling parameterization paper! https://t.co/It6Zvyxnkg
A deep dive into the alignment metric and intuition 🧵 [1/16] https://t.co/Pvn7ewKCme](https://pbs.twimg.com/media/GSzuJZ9agAA4Ykc.jpg)

















![_katieeverett's tweet photo. We've gotten some great questions about the notion of alignment in our width-scaling parameterization paper! https://t.co/It6Zvyxnkg
A deep dive into the alignment metric and intuition 🧵 [1/16] https://t.co/Pvn7ewKCme](https://pbs.twimg.com/media/GSzuJqLaUAAS-Ac.jpg)