Curious about why contrastive learning produces representations useful for downstream tasks? Check out @jhaochenz, @ColinWei11, and @tengyuma's theoretical explanation in our latest blog post: https://t.co/9mFT9Pvb1n
Based on the NeurIPS 2021 oral paper: https://t.co/IKqUVtWyuE
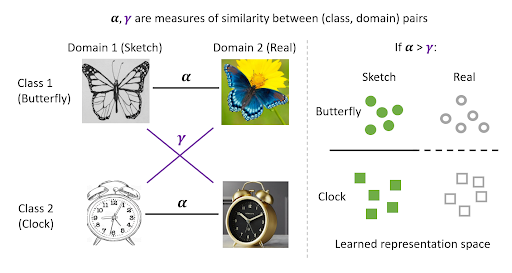
Pretraining is ≈SoTA for domain adaptation: just do contrastive learning on *all* unlabeled data + finetune on source labels. Features are NOT domain-invariant, but disentangle class & domain info to enable transfer. Theory & exps: https://t.co/wuEeHvc3bD https://t.co/8bfrCWyZ5G
Curious about why self-training with unlabeled data can magically improve a classifier’s performance? Check out the theoretical explanation in the following blog post: https://t.co/A8VNyobLjh from @ColinWei11, @jhaochenz, and @tengyuma
Why can GPT3 magically learn tasks? It just reads a few examples, without any parameter updates or explicitly being trained to learn.
We prove that this in-context learning can emerge from modeling long-range coherence in the pretraining data!
https://t.co/b77OIrVGfs
(1/n)
RNNs and transformers with *infinite*-precision are universal approximators---but are they statistically learnable? We show that even finite-precision transformers can express any Turing machine, and they are learnable with polynomial samples. https://t.co/cXgvJRmpke
Pretrained language models are trained with losses quite different from downstream tasks; why can they help? Why does prompt tuning work so well? We analyze them under generative assumptions of the language (HMMs or more realistic variants) https://t.co/WqifMQWNaC
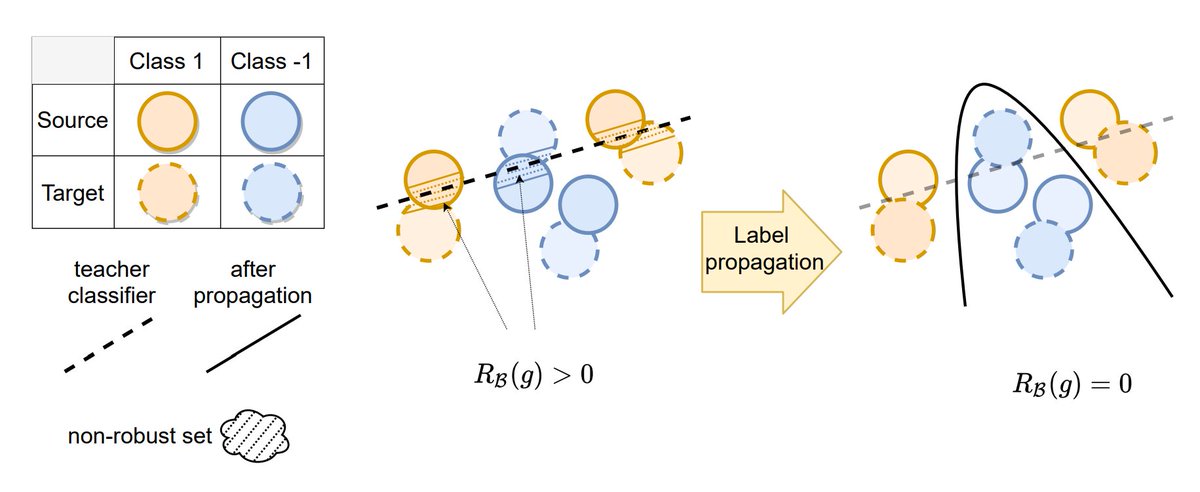
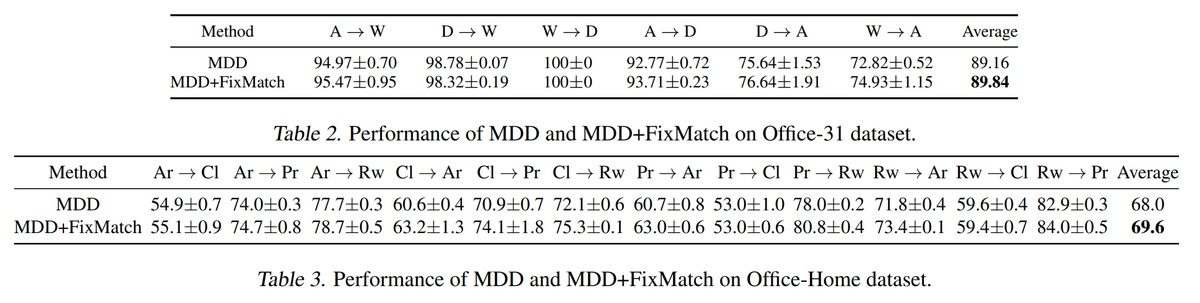
Our ICML paper (https://t.co/Ou5mViBZNa) provided theoretical evidence on the effectiveness of consistency-based methods like AdaMatch, FixMatch, etc. with empirical results for the adaptation of FixMatch on domain adaptation tasks : p