🎉 Excited to share our recent Findings of ACL 2026 paper, HTMuon!
Muon has recently shown promising results in LLM training. But can we further improve its update rule? In our new work, we study Muon from the perspective of Heavy-Tailed Self-Regularization (HT-SR) theory and introduce HTMuon, a simple yet effective spectral correction for Muon.
Our key contributions are:
1. Understanding a limitation of Muon. Muon’s orthogonalized update rule can over-emphasize noise-dominated directions and suppress the emergence of heavy-tailed eigenspectral distributions in the model’s weight matrices, potentially limiting performance under HT-SR theory.
2. Introducing HTMuon. While Muon uses the orthogonalized update UV^T, HTMuon considers the more general form U\Sigma^pV^T, introducing a spectral correction. This enables HTMuon to produce heavier-tailed updates while preserving Muon’s strength in capturing parameter interdependencies. Across LLM pretraining and image classification, HTMuon consistently improves over Muon and other strong optimizers. It can also be used as a plug-in correction for existing Muon variants. For example, HTMuon reduces perplexity by up to 0.98 over Muon in LLaMA pretraining on C4. We further develop accelerated implementations and demonstrate improvements over Muon on LLaMA-1B.
3. Providing a theoretical characterization. We show that HTMuon is equivalent to steepest descent under a Schatten-q norm constraint and provide a convergence analysis in smooth non-convex settings. The results show that HTMuon retains competitive convergence guarantees while improving practical training performance.
📄 Paper: https://t.co/7yqov5p3jP
💻 Code: https://t.co/iWVtOBspcS
Many thanks to my collaborators Yujie Fang, @HenryLiu0820, @DengShenyang24, @twweeb , Shuhua Yu and @nsfzyzz !
@tianylin Would you mind sharing your code and setup? We'd love to reproduce this. We can also provide our exact row-norm algorithm to figure out what's causing the discrepancy in your pipeline.
@tianylin The premise assumes Muon is the "exact" original. In practice, truncated N-S iteration cannot completely flatten the spectral structure either.
Excited that Tony reposted our work! 🚀 Our paper on optimizer via row-momentum preconditioning was recently accepted to #ICML2026.
Huge thanks to Tony for the shoutout and for highlighting our core intuition.
Interesting paper claiming that row-wise L2 normalization (RowNorm LMO) can outperform spectral LMO (newton-schulz). The main idea is the Transformer Hessian is block-diag dominant, so the off-diag blocks in spectral LMO/precond matter less -> use RowNorm.
https://t.co/Gy3sndWlEd
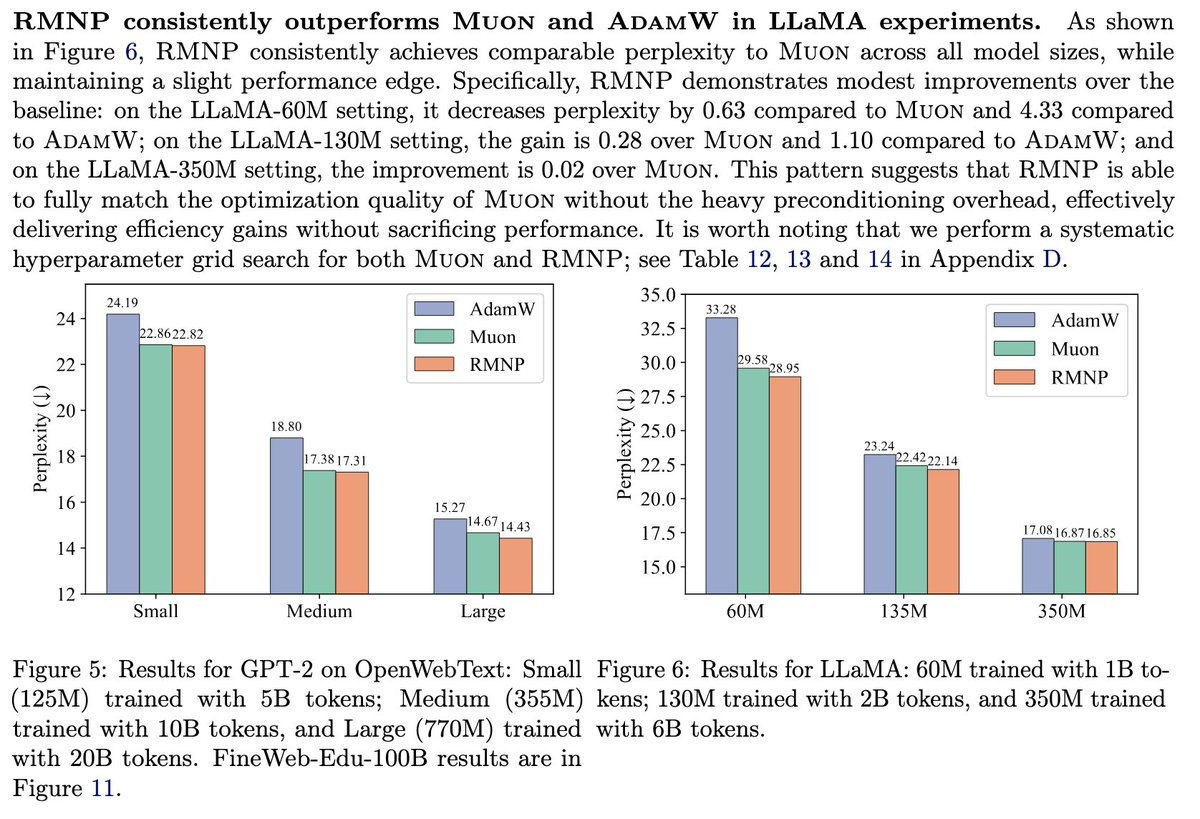
Thrilled to share our #ICML2026 work! We rethink optimizer design by leveraging the row-block diagonal dominance of the Transformer Hessian. We show that simple row-normalization (RMNP) is equivalent to Muon's orthogonalization.
Full story in the thread! 👇
1/n Please stop by👋. This is not just another ICML 2026 optimizer paper. We have rich intuition to share on why simple preconditioners like orthogonalization and row-normalization specifically benefit NNs optimization. Quick overview below 🧵
Interesting paper claiming that row-wise L2 normalization (RowNorm LMO) can outperform spectral LMO (newton-schulz). The main idea is the Transformer Hessian is block-diag dominant, so the off-diag blocks in spectral LMO/precond matter less -> use RowNorm.
https://t.co/Gy3sndWlEd