(1/6) Happy to share our ICML 2026 paper:
Balancing Learning Rates Across Layers: Exact Two-Step Dynamics and Optimal Scaling in Linear Neural Networks
Paper: https://t.co/fTtmyrnqmu
How should learning rates across layers evolve during training?
Our answer: training can undergo a transition from asymmetry to balance, as cross-layer feature learning make balanced learning increasingly important over time.
🎉 Excited to share our recent Findings of ACL 2026 paper, HTMuon!
Muon has recently shown promising results in LLM training. But can we further improve its update rule? In our new work, we study Muon from the perspective of Heavy-Tailed Self-Regularization (HT-SR) theory and introduce HTMuon, a simple yet effective spectral correction for Muon.
Our key contributions are:
1. Understanding a limitation of Muon. Muon’s orthogonalized update rule can over-emphasize noise-dominated directions and suppress the emergence of heavy-tailed eigenspectral distributions in the model’s weight matrices, potentially limiting performance under HT-SR theory.
2. Introducing HTMuon. While Muon uses the orthogonalized update UV^T, HTMuon considers the more general form U\Sigma^pV^T, introducing a spectral correction. This enables HTMuon to produce heavier-tailed updates while preserving Muon’s strength in capturing parameter interdependencies. Across LLM pretraining and image classification, HTMuon consistently improves over Muon and other strong optimizers. It can also be used as a plug-in correction for existing Muon variants. For example, HTMuon reduces perplexity by up to 0.98 over Muon in LLaMA pretraining on C4. We further develop accelerated implementations and demonstrate improvements over Muon on LLaMA-1B.
3. Providing a theoretical characterization. We show that HTMuon is equivalent to steepest descent under a Schatten-q norm constraint and provide a convergence analysis in smooth non-convex settings. The results show that HTMuon retains competitive convergence guarantees while improving practical training performance.
📄 Paper: https://t.co/7yqov5p3jP
💻 Code: https://t.co/iWVtOBspcS
Many thanks to my collaborators Yujie Fang, @HenryLiu0820, @DengShenyang24, @twweeb , Shuhua Yu and @nsfzyzz !
1/n Please stop by👋. This is not just another ICML 2026 optimizer paper. We have rich intuition to share on why simple preconditioners like orthogonalization and row-normalization specifically benefit NNs optimization. Quick overview below 🧵
It‘s an honor to receive the Best Student Paper Award at #ALT2026 (37th Algorithmic Learning Theory) ! 🏆
Huge thanks to my amazing collaborators Boyao,@Collapsar0000 ,@Tianyu0628 ,@MinhakSong ,@nsfzyzz !
Had a great time at the Fields Institute in Toronto. 🇨🇦 Looking forward to attending ALT again next time! ✨
1/8 Glad to share our work at #ALT2026!🎉 If you’re interested in ill-conditioned (or river valley) loss landscapes, suspicious alignment, or the signal-to-noise ratio (SNR) in neural network optimization, this paper may offer some useful intuitions.
https://t.co/VfJYE2jwld
1/🧵New Research on Language Models!
Language models (LMs) often "memorize" data, leading to privacy risks. This paper explores ways to reduce that!
Paper: https://t.co/OBtYz9mJON
Code: https://t.co/x0C5I77CG3
Blog: https://t.co/nA6AH5rnXV
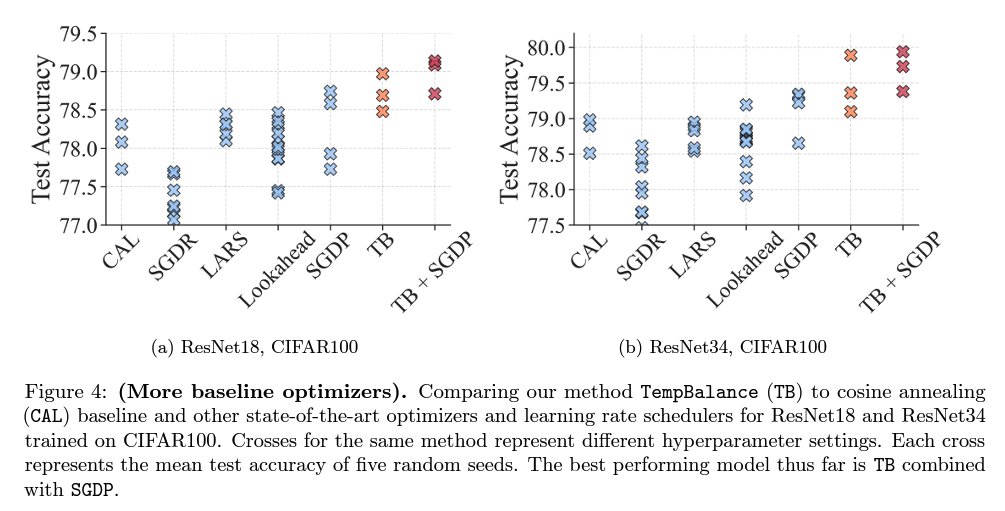
NeurIPS 2023 is around the corner, and I feel excited to introduce our spotlight paper, “Temperature Balancing, Layer-wise Weight Analysis, and Neural Network Training.”
https://t.co/GubYhNznS0
This is a long story, so please bear with me. 👇👇👇
We show quite good results compared to a bunch of optimization tools. More details on the results can be found in the paper. Welcome to stop by our poster to chat with us!