"Without long-term, foundational, and high-risk federal research investments, the seeds of innovation cannot take root," Rebecca Willett and Henry Hoffman write in a new commentary piece. https://t.co/n8lscVfZid
Check out a recent interview in which I discuss the recent Nobel Prizes and some thoughts on the impact on both the domain sciences and ML communities.
Reflecting on my 2024 PhD journey: passed my qualifying exam, spent the summer at Berkeley, mentored undergrad students, and tackled the fast pace of AI/ML research. It’s been a year of milestones and growth! Read more here: https://t.co/8LiZaZd8Rn #PhDJourney#AIResearch
Congrats to Jordan for winning 1st place at SC24 student poster competition! It was super fun to mentor him this summer on his project "Mind Your Manners: Detoxifying Language Models via Attention Head Intervention".
I am super proud of Jordan Pettyjohn, an undergraduate student I had the privilege of working with this past summer, for winning the Student Research Competition at the @Supercomputing conference! 🏆
His work studied ablation strategies for toxicity in #LLMs.
Towards Interpreting Language Models: A Case Study in Multi-Hop Reasoning
paper: https://t.co/03JhOvpZep
This method improves multi-hop reasoning in language models by injecting “memories” into key attention heads, increasing accuracy in complex tasks. An open-source tool, Attention Lens, interprets attention outputs, helping trace the model’s reasoning and pinpoint issues like bias or harmful content.
1/🧵New Research on Language Models!
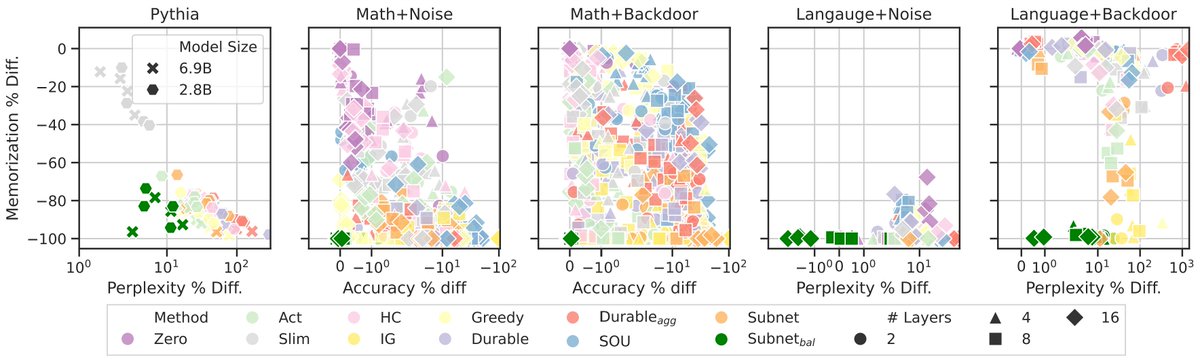
Language models (LMs) often "memorize" data, leading to privacy risks. This paper explores ways to reduce that!
Paper: https://t.co/OBtYz9mJON
Code: https://t.co/x0C5I77CG3
Blog: https://t.co/nA6AH5rnXV
6/ 🌍 Scalable Impact:
Our methods aren’t just for small models! We show that they scale effectively to larger LMs, providing robust memorization mitigation without compromising performance across different sizes of models. Exciting progress for real-world applications!
Language models can memorize sensitive data! 🔒 Our new research by the team (@Mansi__S, @Nchudson95, and others) with TinyMem shows unlearning methods like BalancedSubnet effectively mitigate memorization while keeping performance high. #AI#Privacy
https://t.co/usBb1wLSID
Jordan Pettyjohn, @Nchudson95, @Mansi__S, @aswathy__ajith, and @chard_kyle just published new work demonstrating detoxification strategies on Language Model outputs at @BlackboxNLP!
""Mind Your Manners: Detoxifying Language Models via Attention Head Intervention"
Congrats All!
🎉 I successfully defended my Master's dissertation in the area of interpretable Language Modeling!
Check out my work's applications in better understanding multi-hop reasoning, bias localization, and malicious prompt detection in my talk: https://t.co/DGEvsfzawK
@Mansi__S presented her Master's thesis on "Memory Injections: Correcting Multi-Hop Reasoning Failures during Inference in Transformer-Based Language Models". Watch the recording here: https://t.co/4tgQUgFDTT
Interested in understanding how #LLM s work, why they often fail to reason, and how to improve performance? One tool to boost multi-hop reasoning is with targeted memory injections. This improves desired token probability by up to 424%!
🎥 Watch the talk by @Mansi__S now: https://t.co/ek1HIvDPXk
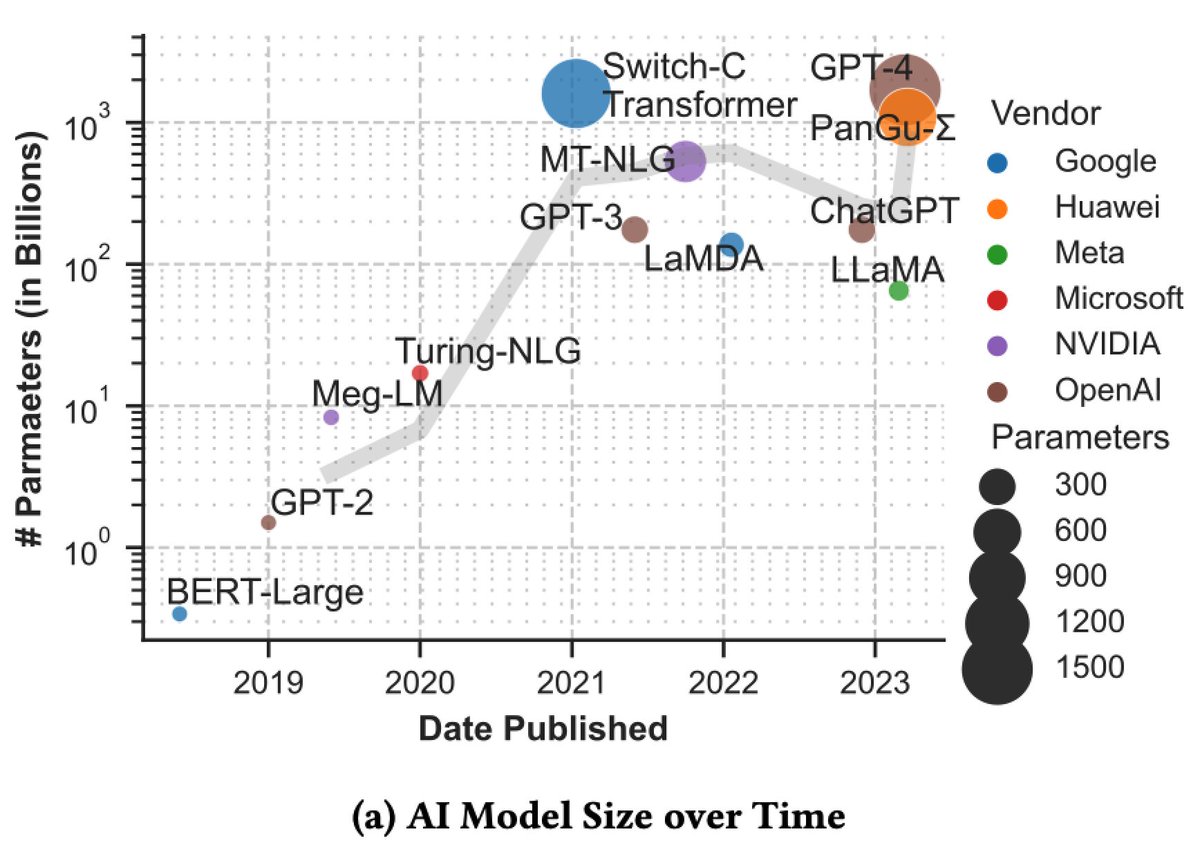
✨Trillion Parameter Models in Science✨
We present an initial vision for a shared ecosystem to take the next step in large language models for scientific research – Trillion Parameter Models (TPMs). #LLM are becoming more powerful by the day. But, there is still work done to enable discovery of new therapeutics, materials, and physics with these tools. 🔬
📜 https://t.co/5Onyx4jTnD