Peter Steinberger is joining OpenAI to drive the next generation of personal agents. He is a genius with a lot of amazing ideas about the future of very smart agents interacting with each other to do very useful things for people. We expect this will quickly become core to our product offerings.
OpenClaw will live in a foundation as an open source project that OpenAI will continue to support. The future is going to be extremely multi-agent and it's important to us to support open source as part of that.
Re-config this to accelerate scientific discovery would be amazing. Imagine explore vast concepts in science for weeks and find new theory for superconductivity that leads to new superconductors
In reflecting on 2025, I keep coming back to how quickly AI moved from “interesting” to genuinely transformative for science and engineering.
Over the last few months in particular, I’ve felt a real shift. For the first time, AI agents can reliably take on meaningful research engineering tasks and produce results that are actually useful fairly autonomously after receiving a specific ask.
That shift has changed how I spend my time. My workflow has flipped: I now spend ~90% on problem definition, system design/architecture, validation, and review, and perhaps less than 10% on implementation. Not long ago, it was the other way around. It’s been both exciting and humbling. The leverage is real, but the responsibility to verify and steer the work is higher than ever.
I’ve also been energized by the momentum in AI for materials science and physical AI, especially seeing so many strong teams and startups forming around real technical problems and the Genesis Mission executive order. It feels like an inflection point, one where the frontier is less about whether these tools can work, and more about how we build trustworthy, repeatable workflows around them.
To close the year, I’m sharing a 148-page review paper generated by zero-shot an AI agent I built for fun. This is something I used to daydream about—and now it’s surprisingly accessible. It’s not perfect, but the trajectory is very promising. Moments like this give me a lot of hope that AI will significantly accelerate the pace of science. 2026 will be another big year for AI for Science.
Prompt: "Impacts and potentials of quantum computing for artificial intelligence"
Paper link: https://t.co/P3P2cZQxwO
Blog: https://t.co/4UtS0m2PsJ
#AI4Science #AIAgent #materialsscience #physicalai #quantum
🚀 Hello, Kimi K2 Thinking!
The Open-Source Thinking Agent Model is here.
🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%)
🔹 Executes up to 200 – 300 sequential tool calls without human interference
🔹 Excels in reasoning, agentic search, and coding
🔹 256K context window
Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns.
K2 Thinking is now live on https://t.co/YutVbwktG0 in chat mode, with full agentic mode coming soon. It is also accessible via API.
🔌 API is live: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/n7xxaszqzF
🔗 Weights & code: https://t.co/4ukcXB0iP6
Congrats!
Polymers are central to materials science, yet AI for materials is still crystal-first. We hope this work helps change that.
Proud to support the team these last few years. Also shoutout to Piero @erunzzz and Guillem @guillemsimeon, both on X and quietly impactful.
MLFFs 🤝 Polymers — SimPoly works!
Our team at @MSFTResearch AI for Science is proud to present SimPoly (SIM-puh-lee) — a deep learning solution for polymer simulation.
Polymeric materials are foundational to modern life—found in everything from the clothes we wear and the food we consume to high-performance materials in aerospace, electronics, and medicine. Today, we introduce a new way to simulate them.
We built a machine learning force field (MLFF) to predict macroscopic properties across a broad range of polymers—trained only on quantum-chemical data, with no experimental fitting. Specifically, we accurately compute polymer densities via large-scale MD simulations, achieving higher accuracy than classical force fields. We also capture second-order phase transitions, enabling prediction of glass transition temperatures. These two properties are fundamental to processing and application design. Finally, we created a benchmark based on experimental data for 130 polymers plus an accompanying quantum-chemical dataset—laying the foundation for a fully in silico design pipeline for next-generation polymeric materials.
The incredible team: Jean Helie, @temporaer, Yicheng Chen, Guillem Simeon, @a_kzna, @ErnestoCheco, @erunzzz, Gabriele Tocci, @chc273, @yatao_li, @SherryLixueC, @zunwang_msr, Bichlien H. Nguyen, Jake A. Smith, and Lixin Sun.
📄 Preprint: https://t.co/CfFTJJA0nk
⚙️ Data and code release: in progress⏳
#MLFFs #Polymers #AIforScience #DeepLearning #SimPoly #ScientificML #Microsoft #MicrosoftResearch #MicrosoftQuantum
Pleasantly surprised to receive an actual medal for our work on #Niobium.
Nb never ceases to fascinate me as a versatile element for advanced materials.
This project explored disordered rock-salt Nb oxides as a negative electrode for Li-ion batteries.
Original paper: https://t.co/fFErvVDX3l
🔥 Today we announce the Meta OMol25 Electronic Structures Dataset - 500 TB of molecular data in collaboration with @mshuaibii and team at @AIatMeta. We envision a future where researchers can rapidly design molecules and peptides to treat diseases, discover catalysts to revolutionize synthesis and manufacturing, identify the next electrolyte to store and transport energy to protect the grid, and more. But these breakthrough discoveries require data.
Data to train next-generation AI models and interatomic potentials. Data to push the boundaries of what's computationally possible in molecular chemistry and lead the world in AI for science. Data that captures the full complexity of chemical systems, from small organic molecules to massive biomolecular complexes.
The OMol25 Electronic Structures dataset includes the raw DFT outputs, electronic densities, wavefunctions, and molecular orbital information for over 4M million high-accuracy quantum chemical calculations. We see this as a transformative opportunity to develop higher quality partial charges, partial spins, and advanced electronic features to unlock the next generation of physics-informed ML models.
The Materials Data Facility is proud to make these data available via the Eagle cluster at ALCF through a high-performance Globus endpoint. Given the dataset's unprecedented scale, we're first releasing all output data for a 4M random OMol25 split, with the full multi-petabyte dataset following based on community engagement.
For this first release, the data are quite raw, and as-created by the Meta team. There's a significant opportunity for the community to build tools that simplify access to these data, allow data query and browsing, create databases of calculated properties and descriptors, and much more. We intend to work on these topics with all of you.
We can't wait to see what you can do with these data!
Access Details: https://t.co/2fQPtpnT3e
Eagle was pioneered as the Petrel project, a new way to provide researchers access to high-quality, high-volume data by Ian Foster, Rachana Ananthakrishnan, Kyle Chard, Michael Papka, Rick Stevens, and others. https://t.co/G9BHCfxdU6 provides core platform capabilities (auth, data transfer, workflow automation, and compute) to over 600k researchers.
Thanks to support from NIST and James Warren for making the MDF vision of vast troves of open data to fuel discovery possible.
@mshuaibii, @zackulissi , @argonne, @argonne_lcf
What @xprize does is truly transformational. Honored to have joined the Deep Tech Brain Trust since May, contributing to AI & materials science innovation in service of XPRIZE’s mission to inspire and empower humanity toward an abundant, equitable future. Exciting times ahead!
We’re thrilled to share the release of our 2025 XPRIZE Impact Report. 🚀From carbon removal to space exploration, our prizes prove philanthropy can deliver 60x ROI in global impact. Learn how we're building the #BusinessOfBreakthroughs: https://t.co/DQuqbfkw7m
Just reviewed a “review article” full of irrelevant and false concepts. When AI papers train the next wave of AI, we risk normalizing mediocrity and mistakes instead of pushing science forward.
Same prompt on one H100 NVL runs with 550 tok/s input and 65 tok/s output. Not bad. The model does seem to hallucinate more than closed top models, but still great progress. Will be exciting to see how the science community will leverage the model
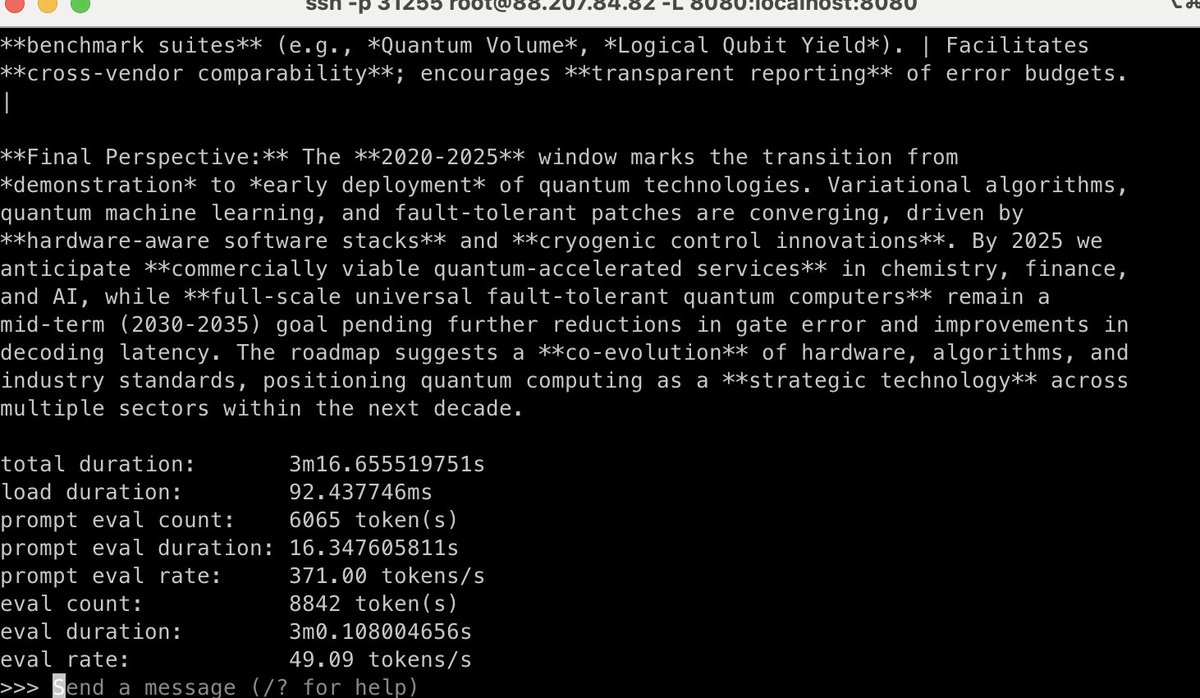
Mind-blowing that anyone can now run o3-level models locally within minutes. Testing gpt-oss:120b on 2x A100 SXM4: ~370 tok/s prompt processing, ~49 tok/s generation. Still more expensive than API calls, but the accessibility is game-changing
Mind-blowing that anyone can now run o3-level models locally within minutes. Testing gpt-oss:120b on 2x A100 SXM4: ~370 tok/s prompt processing, ~49 tok/s generation. Still more expensive than API calls, but the accessibility is game-changing