Live from MLSys 2026! Thanks to everyone who joined @pham_derek's talk yesterday on RLVR in low-data, low-compute regimes and swung by our poster session.
Paper: https://t.co/dZL8uyhn4I
Around tonight? Unwind after the conference with drinks, swing suites, and the team behind the paper. Last chance to RSVP ⛳: https://t.co/cBsH6D9TEz
@vincentsunnchen @ArminPCM @realjustinbauer
Michael I. Jordan on the new MLST.
Four things:
> AGI is a PR term. It confuses young people.
> Discourse is bipolar, either alarmist or exuberant, this is in his words "so demoralizing" for 20- and 25-year-old researchers.
> ML's methods came from statistics and operations research, NOT the AI tradition.
> Data markets are Stackelberg games, not optimisation problems. A lot of ML researchers have never computed an equilibrium.
Michael I. Jordan is a no-nonsense original gangster of the field and was described by Science magazine, back in 2016 as the most influential living computer scientist.
Excited to share we have 4 papers accepted to ICML 2026, including one spotlight.
Proud of the students and collaborators, and looking forward to sharing more about these directions!
More on each coming soon---check out our work:
Here is an experiment I'd do if there is compute.
Simulate a pool of AI scientists with a knowledge cutoff till 2010. Incentivize them for usual metrics and topping leaderboards like Imagenet.
How many of them will choose to work on neural networks or RL? Will they stumble upon AlexNet, ResNets, and transformers? Or invent something else much better?
Our MLSys 2026 paper is live on arXiv: “Learning from Less: Measuring the Effectiveness of RLVR in Low Data and Compute Regimes.”
@realjustinbauer@Walshe_tech@pham_derek@harit_v @ArminPCM @fredsala and @paroma_varma present a comprehensive empirical study of open-source SLMs after RLVR in low-data regimes, revealing that dataset composition matters more than dataset size for scaling performance across number counting, graph, and spatial reasoning tasks.
Read the paper: https://t.co/dZL8uygPfa
Our #MLSys2026 paper is live on arXiv 📄
We ran a systematic study of RLVR in low-data regimes across 3 procedurally generated benchmarks (counting, graph, spatial reasoning).
Key finding: dataset composition matters more than dataset size.
https://t.co/Z7ZuG1fLMD
Excited to head over to Rio for #ICLR2026. Presenting lots of work from my group at @WisconsinCS and with @SnorkelAI—reach out if you want to grab coffee!
That new LFM2.5-350M is super overtrained, right? And everyone was shocked about how far they pushed it?
As it turns out, we have a brand new scaling law for that! 🧵
[1/n]
Hi ML Twitter!
My Summer 2026 internship unfortunately fell through last minute 😵💫
If your team is looking for interns, I’d love to connect - RTs appreciated 🙏
My website: https://t.co/rNih6t6Emb
Looking for a senior postdoc working in the diffusions & flows space @OxfordStats@oxcsml , particularly with interests in reward steering and inverse problems. 15 months in first instance, extendable.
Please reach out if you have questions and apply:
https://t.co/5vecXk4FQv
Thanks for hosting me @iiscbangalore! Really enjoyed talking with Prof. Rangarajan & Varun Mayya @waitin4agi_ about AI for Science. Impressed by the energy and enthusiasm for AI in India, especially from the young. Great to see the statue of Ramanujan, one of my all-time heroes!
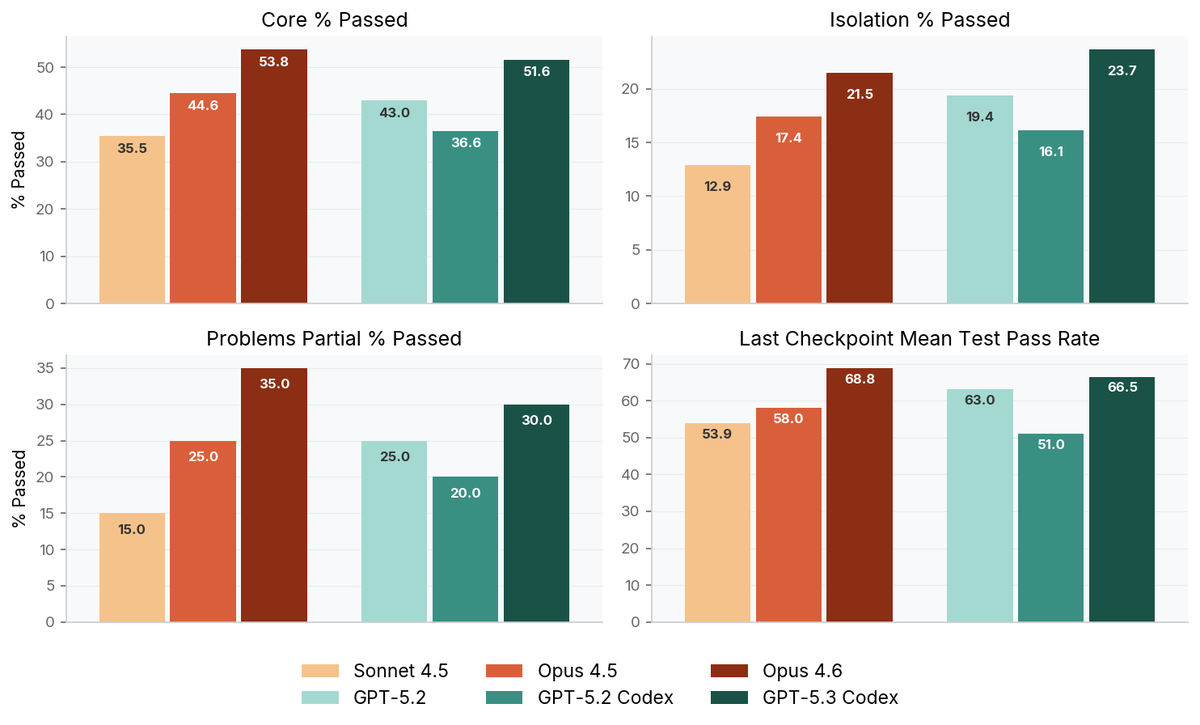
GPT-5.3 Codex and Opus 4.6 are a clear jump in capability.
On SCBench, both exceed 50% on core tests. Meaningful improvement over prior models. 5.3 is ~54% faster than its predecessor. 4.6 nearly doubles the runtime over 4.5.
The code is still a huge mess when unsupervised.
We’ve made huge strides in model & agent capability. Now it’s time to scale up measurement.
We’re excited to support open benchmarks that capture every aspect of the brave new agentic world: complexity, long horizon, autonomy, and rich outputs. Work with us to make it happen!
I want to go with this same analogy, but it breaks a bit due to a lack of reliability. On gcc I could trust blindly, and if there is a bug, it is in my code and not in the compiler's translation.
We went from the lowest level of abstraction(semiconductors) to a relatively high level programing lanaguage (say Python), and there was no loss in meaning (except maybe for some rarest events), i.e., we always got what we asked for.
Maybe we need abstractions that are higher than Python but lower than natural language to impose some structure that can help build trust, like traditional compilers.
I am excited to announce our Workshop on Causality in the Age of AI Scaling in AISTATS 2026!
- Is scaling sufficient for intelligent systems?
- Can causal abilities emerge from scale?
- What can causal modeling bring that scale cannot?
https://t.co/whrrbFUaw0
RTs appreciated
Exciting work from our team, studying data efficiency for RLVR. These kinds of insights inform our dataset creation work for foundation model labs. Kudos to @realjustinbauer@pham_derek for this paper's acceptance to #MLSys 2026!
Our paper “Learning from Less: Measuring the Effectiveness of RLVR in Low Data and Compute Regimes” was accepted to #MLSys 2026!
We introduce three procedurally generated, verifiable datasets—Counting, Graph, and Spatial Reasoning—to study RLVR under low-data / low-compute constraints.
Key result: small, mixed-complexity datasets can be more data-efficient than large, easy ones.

































![nick11roberts's tweet photo. That new LFM2.5-350M is super overtrained, right? And everyone was shocked about how far they pushed it?
As it turns out, we have a brand new scaling law for that! 🧵
[1/n] https://t.co/vj2CZ2GNoE](https://pbs.twimg.com/media/HFOWCzBW8AAr8bY.jpg)