The dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts.
We believe the future is in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Today we're releasing @OpenJarvisAI v1.0: a personal AI assistant that lives, learns, and works on your device.
On the pod: "Recursive Program Synthesis" with @awsTO, Associate Professor at @WisconsinCS.
How cold-emailing @SumitGulwani at Microsoft Research led to a novel research paper and inside Aws' vision to automatically synthesize the software stack for future quantum computers.
"AI for science" benchmarks today mostly test textbook recall. Terminal-Bench Science is a chance for scientists to practice writing that definition. Contribute a real workflow, and you find out exactly where today's best agents break on it.
https://t.co/GZ28R5QIRn
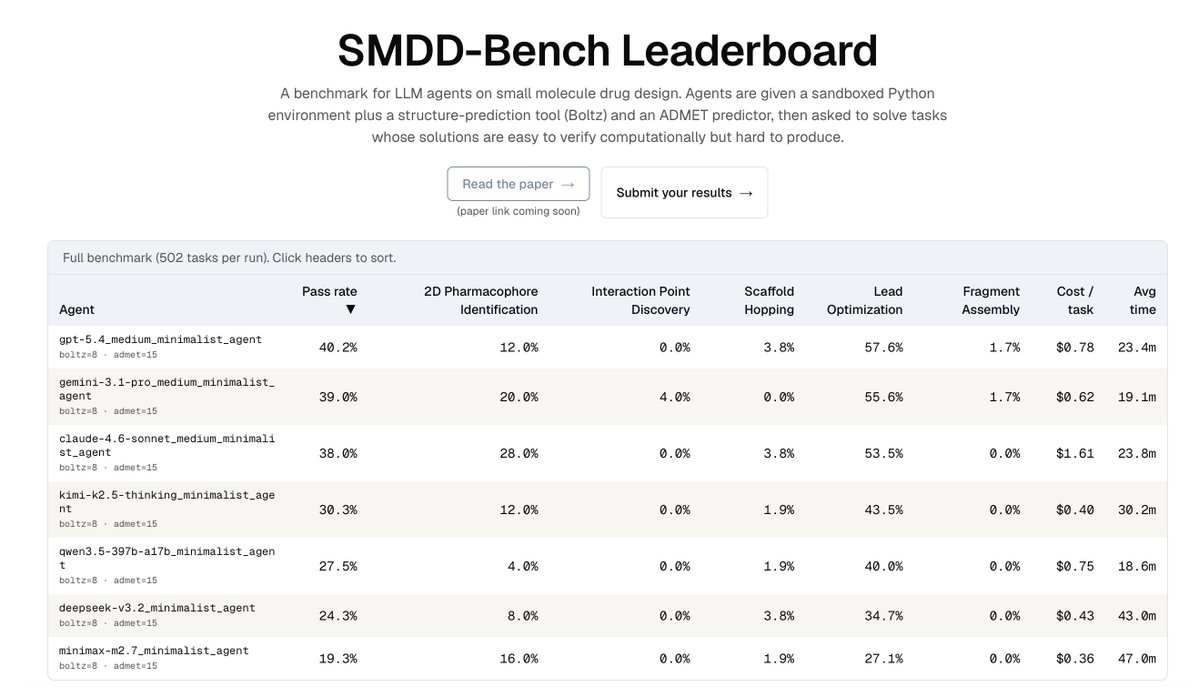
🧬New agentic AI-for-science benchmark: SMDD-Bench!
Can frontier LLM agents actually do small-molecule drug design? Real medicinal chemistry — not single-turn QA, not toy property prediction. Long-horizon, multi-turn, tool-using, with strict oracle budgets.
We release 502 agentic tasks across 5 real drug-design workflows (pharmacophore ID, scaffold hopping, lead optimization, fragment assembly, interaction point discovery), every one guaranteed-solvable via a hidden witness molecule. Agents get a Python sandbox, 8 Boltz2 calls, 15 ADMET-AI calls, no internet — and have to plan across dozens of turns to spend that budget wisely.
Result: GPT-5.4 and Gemini 3.1 Pro are neck-and-neck at the top (40.2% vs 39.0%), Claude Sonnet 4.6 right behind at 38%. Open-source models trail meaningfully. Even the best agents fail >60% of the time.
🧵 below
Rubric-based LLM evals are everywhere. But how do you know your rubric is any good?
RIFT names 8 ways rubrics quietly break + automated diagnostics to catch them, great work by @SnorkelAI. Had a lot of fun building a repo to implement it and rerun the experiments.
🛠️ Repo: https://t.co/s5sTPlWU4T
📄 Paper: https://t.co/fqMAuAvL0Q
Ten years in academia and the best part has not been what many value most ie freedom to pursue your ideas. It’s experiencing your students grow and go on to incredible trajectories.
What I’ve come to know about myself is that I value permanence, presence, and people. And for all the illusions that institutions, titles, awards etc offer, none at all come close to this: watching a human absorb, even in tiny amounts, the care and effort you’ve put into trying your best to just be there for them.
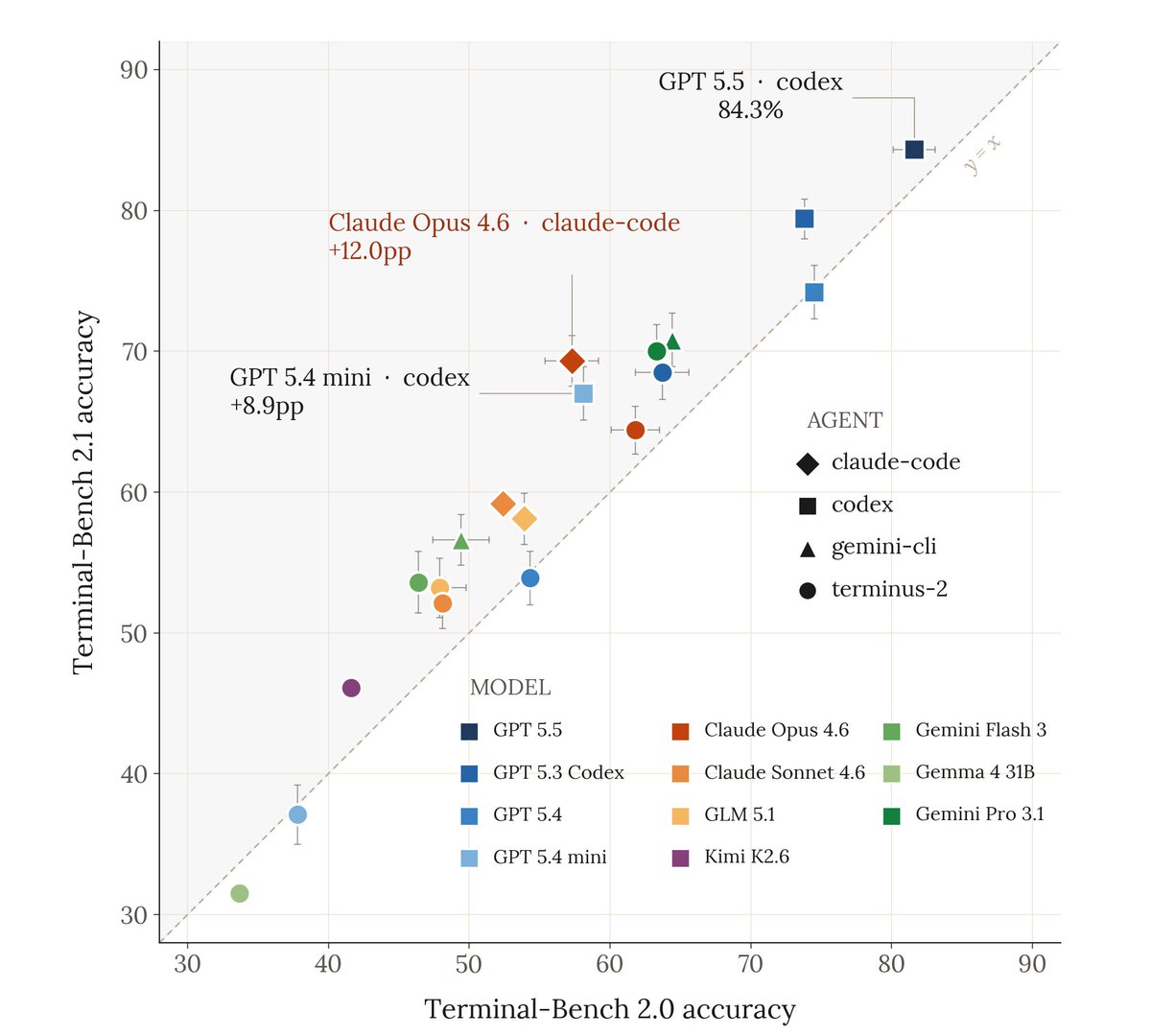
Very excited to release Terminal-Bench 2.1!
Coding agents are among the most economically consequential deployments of LLMs to date. As agents improve, benchmark reliability matters more.
We audited TB2.0 and found and corrected issues in 28/89 tasks. 30% of the benchmark!
But the rankings survived, absolute scores moved up to 12pp!
We're releasing Terminal-Bench 2.1 to patch 28 of the 89 tasks in Terminal-Bench 2.0
TB2.1 includes
• recalibrated limits
• fixed solutions
• realigned verifiers
Per-task breakdowns in 🧵
We'll continue to support TB2 and TB2.1 leaderboards (new submission process 🔜)
Legal AI is still far from solved.
The breakthroughs needed will generalize to all knowledge work. A community is needed to get there, and Harvey is helping build it.
Really excited for @pgasawa and team!
Continual learning desperately needs benchmarks that distinguish raw ability from actually improving with experience. Continual Learning Bench is a great step in this direction.
Today, we’re releasing Continual Learning Bench 1.0: the first, realistic benchmark for measuring how AI systems can improve in online settings.
Benchmarks today assume models are stateless. Each example is independent, and once a system finishes a task, it moves on as if nothing happened.
But deployed AI systems should learn from experience. We tested 10+ frontier systems against novel, expert-validated tasks and find there’s still plenty of headroom for learning. (1/n)
- CARE: Confounder-Aware Aggregation for Reliable LLM Evaluation (https://t.co/cQeV38oPLv)
- Evaluating Sample Utility for Efficient Data Selection by Mimicking Model Weights (https://t.co/6dFtul9KoP)
Excited to share we have 4 papers accepted to ICML 2026, including one spotlight.
Proud of the students and collaborators, and looking forward to sharing more about these directions!
More on each coming soon---check out our work:
- Expressivity-Efficiency Tradeoffs for Hybrid Sequence Models (https://t.co/qy21p8I2jS)
- Weight Updates as Activation Shifts: A Principled Framework for Steering (https://t.co/mL6Z7GEW7M)