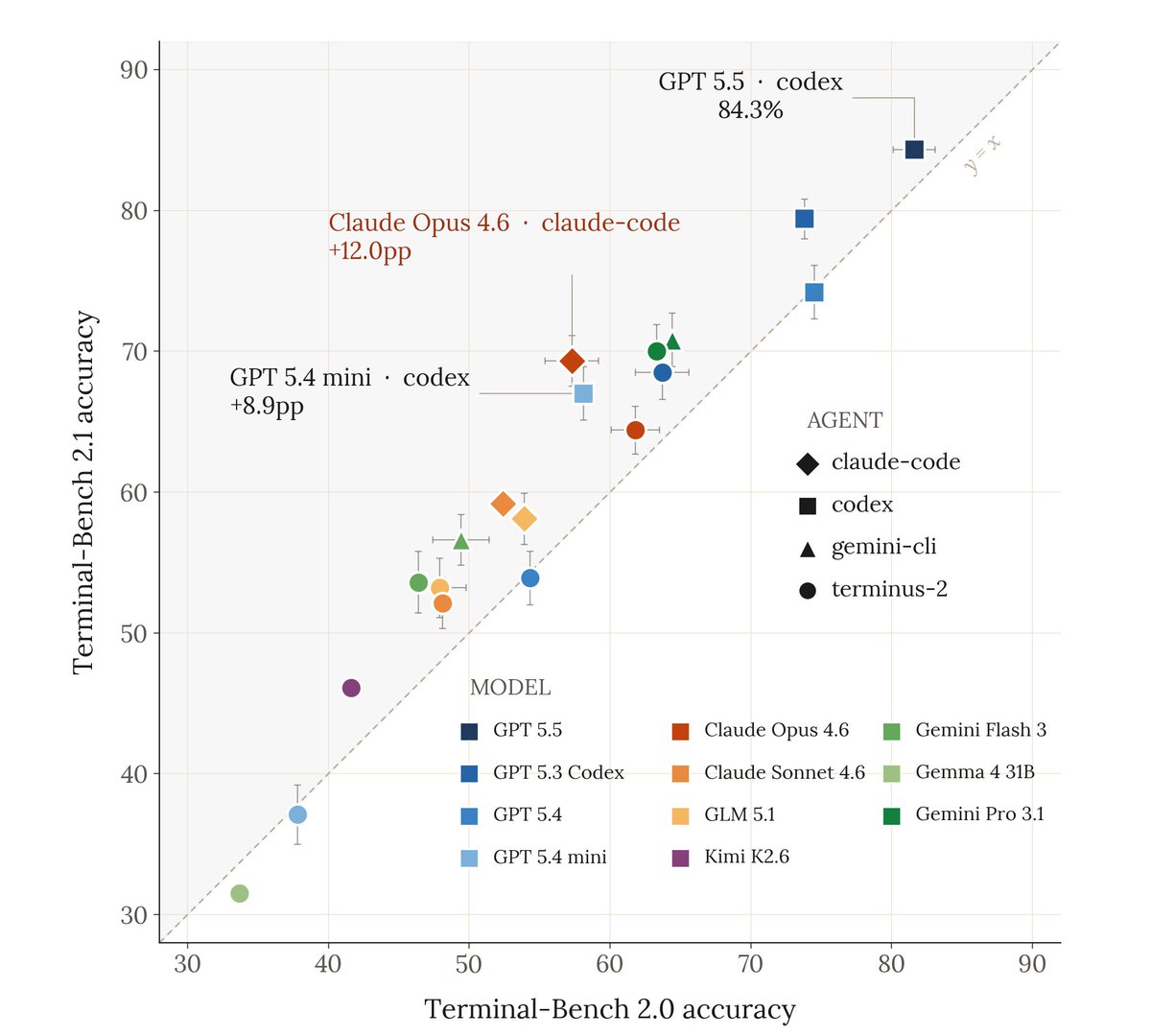
Very excited to release Terminal-Bench 2.1!
Coding agents are among the most economically consequential deployments of LLMs to date. As agents improve, benchmark reliability matters more.
We audited TB2.0 and found and corrected issues in 28/89 tasks. 30% of the benchmark!
But the rankings survived, absolute scores moved up to 12pp!
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
how does the brain build and track an internal state of the world from (possibly incomplete and noisy) visual observations?
i believe visual state tracking will be the grand challenge for vision in the coming years, and i hope this benchmark can be a useful starting line. enjoy!
Efficient verification is what makes scaling legal agents practical. Excited to partner with @hwchase17 and the @LangChain Labs team on designing efficient verifiers - sharing early results showing open models can match frontier verifiers at a fraction of the cost on Legal Agent Bench.
Some of the more puzzling unpublished observations from our paper: deep attention layers hate the residual stream of V and love it for QK, but if it has to make a choice, it will satisfy V over QK.
Translated to finding: if we learn coefficients for residual stream xi and the initial token embedding x0 as two input streams to deep attention layers, the model will give the coefficient for x0 a much larger magnitude. This will mean dominating the input with context-free token information.
However, if we learn the coefficients for both at a more fine-grained level for Q, K, and V, the coefficients for x0 is near 0 for both QK, but huge for V.
This reveals two surprises. (1) QK needs context information and little original token information. And K does not need the same information as V does (despite some models tying them). (2) Between the two opposite needs, the model is clearly in favor of what benefits V, so V is deemed more important to the optimization goal.
These are just the tip of an iceberg, and transformers surely moves in mysterious ways. We will therefore embark on the second part of this journey and, for our next set of experiments, involve this lady (iykyk)...
Paper: https://t.co/oFaXEx9Upx
Pitch us a benchmark or eval technique. We'll fund you to build it.
We're opening applications for the Vals Fellowship. 3–6 months working on the hardest open problems in AI evaluation, with the resources to actually solve them.
What you get:
- Unlimited API credits + budget capacity for GPUs and human data
- Vals’ evaluation infrastructure
- $1,000–2,500 / week stipend
- A network of evals researchers across frontier labs and academia
Location: Both remote / in-person in SF applications will be considered
Cartesia Ink-2 debuts as #1 for accuracy on the brand-new streaming speech-to-text leaderboard from @ArtificialAnlys! We designed Ink-2 from the ground up for voice agents - with low latency, eager transcripts, and semantic endpointing.
The dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts.
We believe the future is in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Today we're releasing @OpenJarvisAI v1.0: a personal AI assistant that lives, learns, and works on your device.
1/ We’ve raised over $1B at a $26B valuation, led by @Lux_Capital, @generalcatalyst, and @8vc.
Our enterprise usage has grown >10x since the start of this year, and our run-rate revenue grew to $492 M.
We launched Devin two years ago as the first AI software engineer. Since then, cloud agents have gone from niche to mainstream, and today they are the fastest growing way to create software.
The agent also reimplemented the “Blues Improvisation” experiment by @douglas_eck and @SchmidhuberAI in 2002 which show that LSTMs can learn temporal structure in music.
Finding temporal structure in music: Blues improvisation with LSTM recurrent networks
https://t.co/2oU4iIcJEr
Excited to release 🌟Polar🌟, our Agent RL rollout infra for real-world harnesses. Be it Codex, Claude Code, OpenClaw, Hermes, or your self-made ones 🔥 -- Polar takes your harnesses directly as training environments without code change.
Find a problem, design the harness, and train your own agents! 🧵
Some enterprise tasks are challenging to hill-climb with RL-based methods since they involve very out-of-distribution behavior. On-policy self-distillation (OPSD) gives a model learning signal for every token it writes, far richer than the single scalar reward of RL.
But that channel is noisy: most tokens don't reflect the behavior you're after. We introduce Relevance-Masked Self-Distillation (RMSD), which uses a two-step filtered loss mask to cut through the noise and find the tokens with the highest signal. Compared to OPSD it trains more stably, provides higher data efficiency, and reaches a higher performance ceiling.
I defended my PhD last week!
The main focus of the talk was my recent work on fast sketching on GPUs via co-design, FlashSketch
(https://t.co/7wXxsTFGsn, ICML 2026 Spotlight).
Recording: https://t.co/mMwy3vZFO7
Step through the animated slides:
https://t.co/M9jYSlfqty
1/ Today at #GoogleIO, we’re releasing Gemini 3.5, our latest family of models combining frontier intelligence with action.
We’re starting by releasing 3.5 Flash, which is built to help you execute complex, long-horizon agentic workflows.
Gemini 3.5 Flash is our strongest model for coding and agent https://t.co/m62cBJhIjJ outscores 3.1 Pro on agentic and coding benchmarks like Terminal-Bench and MCP Atlas, while running 4x faster than other frontier models.
Used in Google Antigravity, 3.5 Flash is even further optimized to be up to 12x faster. It’s a powerful engine to deploy sub-agents that collaborate, run high-frequency iterative loops, and solve real-world problems at scale.
Some highlights we’re excited about 🔽
Gemini 3.5 Flash is amazing!
- Performs better than 3.1 Pro on coding & agentic tasks
- 4x faster than other frontier models
- 12x faster in @antigravity - 800 tokens/sec!
- Often at less than half the cost
And Pro to come…
Try it in @antigravity, @GeminiApp & more - enjoy!
🧵 1/11 Everyone's doing on-policy distillation now (Qwen3, Deepseek V4, GLM-5).
But here's what nobody's asking: at any given token or for a question and a teacher, when does the teacher's guidance actually help, and when does it quietly make things worse?
We found a way to answer this. No training needed!
Introducing Mesa: the most powerful filesystem ever built, designed specifically for enterprise AI agents.
Every team building agents eventually hits the same wall: where do the files live?
Not the chat history, the actual artifacts the agent works on.
> The contracts your agent redlined
> The claim files it updated
> The 200-page audit report it edited overnight while you were asleep
Today those documents live in a sandbox that dies in 30 minutes, an S3 bucket where concurrent writes clobber each other, or a GitHub repo that was never built to absorb agent-scale traffic.
So we built Mesa.
The world's first POSIX-compatible filesystem with built-in version control, designed from the ground up for agents. You mount it into your sandbox like any other filesystem. Your agent reads and writes files normally. Behind the scenes every change is versioned, branchable, reviewable, and rollback-able — like a codebase, for any file type.
Mesa provides
– Branches so agents work in parallel without locking
– Durable storage that survives sandbox death
– Sparse materialization so massive document sets load instantly
– Fine-grained access control per agent
– Full history for human review and audit
Design partners are running Mesa in production across legal, healthcare, GTM, business ops, and coding agents.
Private beta is open: link in the comments
💥Today we release InferenceBench, our next benchmark after PostTrainBench that measures progress on AI R&D automation.
AI R&D automation will very likely unfold gradually, starting from “boring” tasks like inference speed optimization that are very easily verifiable (accuracy + inference time). We show a rather negative result for current frontier agents. They are not good at system-level engineering and managing complex dependencies. They do show non-trivial performance, but they fail compared to a simple baseline: hyperparameter tuning of vLLM/SGLang hyperparameters.
Importantly, InferenceBench tests *open-ended* inference optimization capabilities. This is different from more narrow benchmarks like KernelBench that only let agents optimize kernels (which is a very valuable task, too!). The benchmark is intentionally open-ended, so the poor performance of the agents is not an underelicitation issue. The agents have everything needed to succeed, but they still fail because they are not yet reliable enough for this task.
Our results suggest an inverse scaling phenomenon: Claude Sonnet 4.6 and GLM-5 rank highly because they more often preserve simple, valid, high-performing final servers, while several larger models show stronger peak runs but lose utility through brittle final-state choices. This contrasts with benchmarks where rankings track raw capability (e.g., SWE-Bench, Terminal-Bench, PostTrainBench, FrontierSWE).
One of the primary bottlenecks we have clearly observed is the lack of diversity of strategies: nearly all agents just use vLLM, without exploring alternatives. Overall, proper exploration is lacking: the current agents are not ready to tackle broad enough goals and get stuck after the first found solution (such as vLLM). I’m sure future agents will do much better, but here is where we are now.
This benchmark is our 2nd one in a suite of benchmarks that will track the progress on AI R&D automation. We will develop many more benchmarks that will cover different aspects of AI R&D automation, culminating in recursive self-improvement. Stay tuned!
Frontier models set the floor. Specialized models raise the ceiling.
With Modal, @AppliedCompute is training custom agent workforces for companies like DoorDash, Mercor, and Cognition.