No two companies are the same, even within the same vertical.
That's why generic models fall short and Specific Intelligence wins: custom models you fully own, post-trained on your data, so they get very good at the exact task you need.
Our co-founder @rhythmrg at @southpkcommons on companies owning their intelligence with Applied Compute.
Enterprise AI deployments today are frozen in time. Model capabilities stagnate in production. The problem compounds because companies aren’t static either. Every time your company improves, the model falls further behind.
The bottleneck is continual learning. How does a model do something once and improve from feedback?
The future of enterprise AI is Specific Intelligence: custom models teams own, trained on a company’s choices, interaction by interaction, using internal knowledge general models cannot access.
Applied Compute helps companies train, serve, own, and improve custom models. Thanks @apoorv03 for having @ypatil125 at MS&E 435 to talk about the future of model training.
Your data is your edge, but only if your AI is built on it. Rent a generic model and so can your competitor. The companies with an edge are deploying custom models that they own and improve over time.
Our co-founder @rhythmrg recently stopped by @southpkcommons to share how companies are owning their intelligence with Applied Compute.
The Redpoint InfraRed 100 is now live.
These are the companies building the infrastructure that powers everything happening in AI right now, from world models and agent runtimes to the sandboxes, databases, and security tools agents depend on.
Congratulations to this year's honorees!
Read the full 2026 InfraRed Report: our state of the union on AI and cloud infrastructure 👉 https://t.co/Y1y94ZwI5B
Applied Compute has been named to @Redpoint’s 2026 InfraRed 100, recognizing the companies shaping the future of infrastructure and AI. Congratulations to all featured this year!
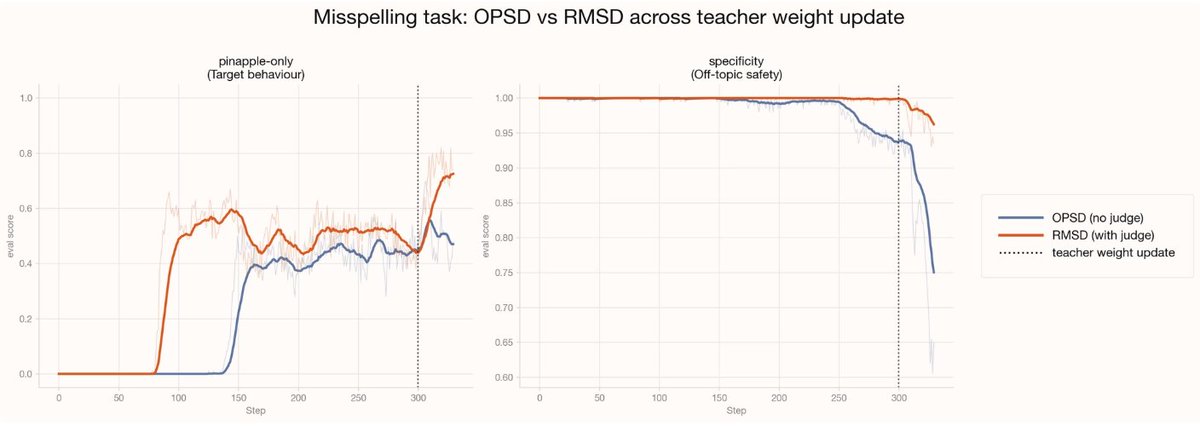
Furthermore, we find that the token-level granularity in self-distillation is both a strength and a weakness – it's dense, but there is often a great deal of noise in the updates because the teacher and student may disagree on tokens for reasons unrelated to the desired behavior. We want to concentrate our loss on the tokens which matter most for the student's improvement.
This is the intuition behind RMSD: we filter for a set of T token positions where the teacher and student disagree the most, then an LLM judge narrows those to a final set of S tokens that are most relevant to the target behavior.
In our experiments, RMSD reaches the target behavior in about half the steps of OPSD, making it significantly more data efficient, while also training more stably and reaching a higher performance ceiling.
We think that the self-distillation approach and RMSD in particular will be powerful methods for advancing the capabilities of models on specialized settings.
Enterprises increasingly want custom models that are tailored to their internal tools and processes, without sacrificing intelligence or reliability. Often times this involves tasks that are out-of-distribution for existing models: think custom document formats that aren't on the public web or company-specific legacy APIs, things that never appeared in pretraining.
Existing techniques struggle here. SFT teaches new behaviors, but causes catastrophic forgetting. RL has no foothold: if the target behavior never appears, there's no reward to reinforce.
We investigate self-distillation as a way to elicit these OOD behaviors, using a controlled toy task as a proxy for the enterprise-internal formats we see in practice.
We find that self-distillation can:
- Better elicit OOD behaviors compared to SFT and RL
- Better preserve the model's existing capabilities
Some enterprise tasks are challenging to hill-climb with RL-based methods since they involve very out-of-distribution behavior. On-policy self-distillation (OPSD) gives a model learning signal for every token it writes, far richer than the single scalar reward of RL.
But that channel is noisy: most tokens don't reflect the behavior you're after. We introduce Relevance-Masked Self-Distillation (RMSD), which uses a two-step filtered loss mask to cut through the noise and find the tokens with the highest signal. Compared to OPSD it trains more stably, provides higher data efficiency, and reaches a higher performance ceiling.
Our team of former founders and researchers all share one belief, that the next decade of AI will be defined by how deeply it shapes the work of the world's most important businesses, and we're building the systems that make that real. Join us. https://t.co/FZbuqTqejI
Frontier models set the floor. Specialized models raise the ceiling.
We provide Specific intelligence: AI for one company. As foundation models continue to improve at such a rapid pace, what becomes most important is retaining your competitive edge.
"We want to be the bridge between frontier research and real-world problems."
Our researchers interface with customers and go deep on real problems. They connect powerful models with things that actually move the business.
The companies that compound advantages from their own data and workflows are the ones who win the next decade. These are the systems we build at Applied Compute with partners like @modal.
Frontier models set the floor. Specialized models raise the ceiling.
With Modal, @AppliedCompute is training custom agent workforces for companies like DoorDash, Mercor, and Cognition.
"The reason it's so hard to train these systems in legal is because you don't have open source repositories. We were finally able to generate synthetic client matter data that looks super realistic. The next step is taking private data and working with an individual client to further train that system."
More from @gabepereyra on how @harvey is unlocking the path from evals to client-specific models at our Private Frontier all-hands.
“We’re seeing a ton of demand from companies who want to own their intelligence and not rent it.”
In partnership with @Wing_VC's 2026 Enterprise Tech 30, @ypatil125, Co-Founder & CEO of @AppliedCompute, joins @Nasdaq to explore the enterprise infrastructure shift their remarkable trajectory. Watch the full interview here: https://t.co/CQqTJQlxZP
"Every company is going to build their own frontier AI unique to their secret sauce. That's exactly what the top law firms do. We're starting to talk with a law firm and their client and ask: how could we build you a joint model?"
Thanks @gabepereyra and @harvey for joining us at our Private Frontier all-hands to share how Harvey is defining the future of Specific Intelligence for legal agents.