@compileandpush They discuss everything from RL loss to environment setup, so it is a great report if in no other way than just being very exact and detailed.
We are pleased to see that the latest MAI-Thinking-1 model is strongly sustained by a synthetic pipeline for RL environment, primarily for agentic MCP tool use scenario. Curiously, they especially highlight the FunReason-MT pipeline by Ant Group, which contains a few interesting ideas:
(1) To scale up multi-turn trajectory generation, they form a directed graph of all tools, and sample shortest paths to a target tool call, to get a correct and efficient trajectory.
(2) They generate a realistic query that matches the trajectory so that the agent gets a task where the trajectory is the ground truth answer.
(3) They collect the actual trajectory by an agent solving that task as the final data, but also use a correction agent to correct the agent at each step against the ground truth, so that the agent produces correct, optimal trajectory that is highly usable.
In practice, MAI is able to leverage multiple open-source synthetic data research to generate 150 environments with 130K tasks, which eventually leads to their strong performances.
Glad to see a new player in the agentic RL landscape, but more importantly one that is willing to implement, evaluate, and share research on synthetic data generation, which will be increasingly important with the growing number of agentic scenarios.
It's important for the community to reflect on in what areas the open-source labs have closed the gap on frontier capabilities:
(1) 1M context. DeepSeek V4 tech report has sufficiently shown how compression + sparse selection of keys/values in attention can enable 1M context at a fraction of the cost. Minimax M3's "sparse attention" mechanism (which now has only a teaser figure) should be yet another banger architecture.
(2) Multi-agent system. Kimi K2.5 has demonstrated how to design rewards, define tools, and manage the rollouts of multi-"agent-swarm" RL training, to orchestrate agents like Claude Code does.
(3) Large-scale training. GLM-5 has published a detailed report on async RL, solving everything from managing the logprob mismatch between the inference checkpoint and the training checkpoint, to maximizing the KV cache reuse across nodes. This allows stable training of trillion-scale frontier models.
(4) Expert-level intelligence. Several labs have shared very detailed RL curriculum design on top-human-level performance. Most impressively, DeepSeek-Math-V2 published a very detailed recipe that jointly trains the model as a math prover and as a math grader to score gold medal on IMO, a "secret sauce" OpenAI used to hold exclusive to last summer.
Judged by what top open-source labs have put out, this year is bound to be a year with accelerated progress on open-source frontier research!
As agentic RL becomes more important in the research community, the problem of token-vs-text mismatch is now actively studied. Some throwbacks to earlier efforts from our side & frontier labs:
- Back in January, when building our on-policy distillation framework Spider, we noticed the same issue doing tool-use distillation: in multi-turn, after tool calls, the qwen3 tokenizer will more likely than not loses the original tokens when retokenizing from text.
Specifically, there are two issues. (1) We find that tokenizers do not fully cover all possible unicodes, and some characters will break the retokenization. (2) Qwen3's chat templates are fragile, so not having thinking tokens will natively cause a mismatch.
- In February, GLM-5 tech report flagged the same issue, and switched their training stack to use token-in-token-out design. Specifically in their async RL stack, there is a dedicated feature to record and send token packets in additional to text packets. This not only preserves the original token sequence but also saves the overhead of orchestrating tokenization.
Glad to see more open-source implementations of the same solution! As far as we know, Prime Intellect and Tinker are doing the same thing.
Use spider for distillation: https://t.co/3zU9rdO80L
Most people training agentic LLMs with RL right now have a silently broken training loop and have no idea.
Here's the trap: single-turn RL works beautifully. Clean curves, sane rewards, everything converges. Then you add tools so the model can act mid-rollout, and things get weird. Loss spikes for no reason. Eventually a shape-mismatch error.
The culprit: every time you parse the model's output to detect a tool call, then re-tokenize the updated conversation for the next turn, you're rolling the dice. Usually the round-trip gives back the same tokens. Sometimes it doesn't and your gradient lands on a sequence the model never actually sampled. No crash. Just quietly wrong math and a useless gradient signal.
The fix is one rule: never re-encode tokens you've decoded. Keep the sampled tokens in one buffer, never re-render them, and both failure modes disappear. That's Token-In, Token-Out done right.
Our team just published a beautiful deep-dive on exactly this, including an audit across the major open-weights model families showing most chat templates already support it. Required reading if you're doing multi-turn RL 🤗🔥
https://t.co/zmx0EQl3jM
In light of Claude Code's Dynamic Workflow rollout, we choose to review some solid multi-agent research by frontier labs, as they are very informative to the agentic research community.
- Anthropic's early "open source recipe" for Workflow, where they use multi agents to build a C compiler.
Important takeaways: (1) Each subagent is given a distinct worktree, and can push/pull from the same branch, to ensure no write conflicts and only incremental changes to the codebase. (2) Each subagent is tasked something different (eg. test a different C kernel), so they never do duplicate work.
- Kimi K2.5's RL technique for training the model to orchestrate a swarm of subagents.
Important takeaways: (1) For multi-agent, training / eval should penalize the longest steps taken by a subagent in one dispatch, so the model is motivated to parallelize across agents similar workloads. (2) The reward design should encourages both number of parallel agents (to prevent using single agent for hard tasks) and their finish rates (so the model does not spam sub-agents).
As multi agent systems become more and more powerful for work involving expertise, we find open research like these valuable.
We are dedicated to the same cause: training / evaluating agents and subagents optimized for a broad range of enterprise / research / coding tasks. Looking forward to sharing more soon.
We launched some experiments to challenge the "convention wisdom" of what data recipe should be used in CUA training, given that they come in different OS, apps, and tasks.
In particular, we questioned whether first training the model on grounding data "lays a stronger visual foundation" for the model.
To test whether this is true, we took Qwen2.5-VL-3B and train it on the grounding and the action split of the ScaleCUA dataset in different order.
We found the conventional order of grounding -> action performs much worse than the unintuitive action -> grounding on 3/4 benchmarks, and the only one without regression is on visual understanding. Shuffling the two splits gives the best results + least regression.
This suggests that there is no need for a curriculum at least on this data distribution, which is fairly representative (Window, Linux, MacOS, iOS, etc. on multiple apps)
So far we are only touching the tip of the iceberg of what is true vs untrue in the myth of CUA training. Our previous post also identified that existing models are overfitted to benchmarks in non-enterprise scenarios, which are not the central use case of CUA. A lot is to be done in the CUA domain and we are dedicated to this cause to improve its data quality and coverage.
Work done by @alckasoc.
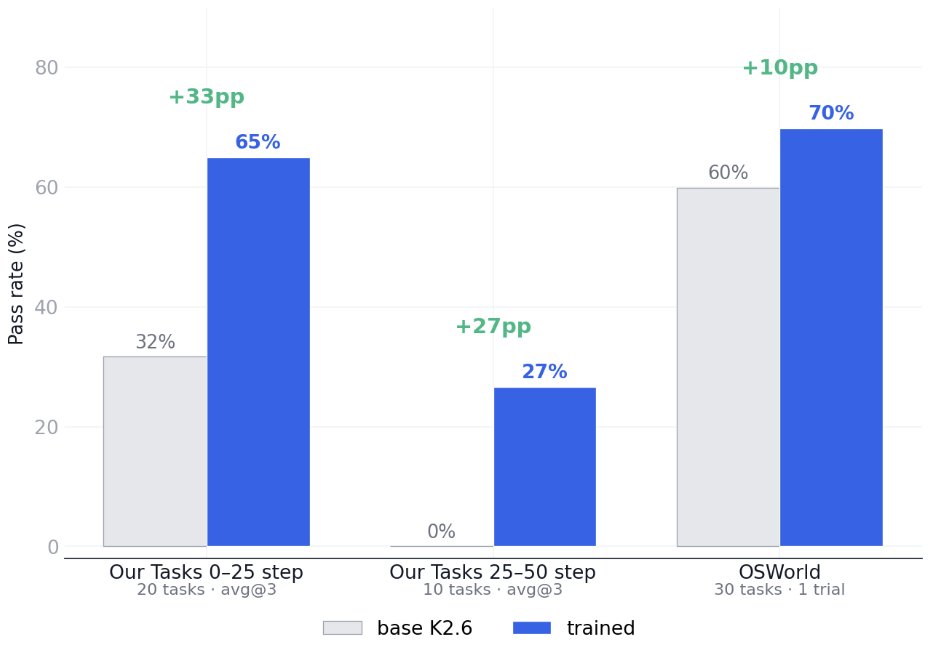
We discovered significant gaps between open and closed sourced models on our realistic computer-use-agent tasks, and it is a data problem.
Although open models have nearly saturated OSWorld, we found that kimi k2.6 cannot do tasks that GPT-5.4 solves in 50 steps.
Our 30 tasks are realistic: the agent works with an open source version of Office Suit in an linux OS, and compiles excel sheets. GPT-5.4-high solves 2/3 in 25 steps, and 1/3 in 50 steps. Kimi k2.6, the strongest open model on OSWorld, fails almost all of them.
We understand the problem to be very simple: open models simply are not trained on realistic CUA data enough. To test this hypothesis, we simply RL-ed Kimi K2.6 on 10 in-domain CUA office tasks with LoRA.
The result of the simplistic RL is a significant increase of +30% in the capacity to do office tasks. However, the improvement gracefully carries over to OSWorld itself: on a stratified subset of 30 tasks, the RL-ed model sees another +10% lift.
The takeaway from our initial results is that CUA models suffer from unrealistic, low-quality data. As a result, we are continually building realistic apps / RL environments to bridge the gap. More to come.
Solid work done by @alckasoc
Who says agents are only built in the Bay?
At our last Collinear Dinner Series in NYC, we sat down with frontier builders from IBM Research, NVIDIA, BNP Paribas, Two Sigma, Wells Fargo, Datadog, 2OS and others.
Making agents function reliably within enterprises is an underrated challenge right now. Long-horizon workflows, compliance requirements, messy data, and several compounding factors are open problems.
Probably different problems from the Valley, but equally frontier and (sometimes) harder.
NY had a lot to say this round. The next dinner's in the Bay. DM for the secret invite.
@sachpatro97
We are hosting a fun researcher event at our Sunnyvale office this Thursday. Come to play mini hoop, grab meals, shoot nerf guns, and join researchers to discuss one of the most important questions in post training right now: how to really build simulations for RL?
As we are focusing on building realistic RL environments to power frontier agents, we and our guests have a lot to share and we are excited to hear your thoughts as well.
It's gonna be 50% knowledge and 50% vibes / महफ़िल / 氛围. Come to have fun!
Register at: https://t.co/dKvNgxnfQg
Agents don't fail like language models do.
It's not about a single bad output, it's the result of compounding mistakes across a control loop. Step 3 is where it starts. Step 8 is where it surfaces. By then, a real user is on the other end.
SimLab, a CLI for simulating AI agents before they hit production, now has a public SDK.
Give it a try → https://t.co/sOxzWuh3eN