Computational Linguistics, established in 1974, is the official flagship journal of the Association for Computational Linguistics (ACL).
Tags:#CLJournal#NLProc
Our Editor-in-Chief, Dr. Wei Lu, presents a new vision for the journal in the editorial 'Opening a New Chapter for Computational Linguistics', marking a forward-looking transition as the journal enters its second half-century.
Read: https://t.co/Wo5fefUpDK
CL Journal has over 50 years of history in the field. While the field is moving, some of the articles from decades ago provide perspective and still relevant content. What do you think of these articles from 20 and 40 years ago? (2006 and 1986) #NLProc
While we're waiting for the next issue of the CL Journal to introduce the new articles, you can get early access to upcoming articles here: https://t.co/YAR0Hl004n #NLProc#CLJournal
Like humans, LLMs can be right for the wrong reasons. They can also be wrong for the wrong reasons. Anthropocentric bias has gone largely unexamined, posing a serious obstacle to the objective assessment of LLM capacities. Read more at https://t.co/mkusIYxp2n #NLProc#CLJournal
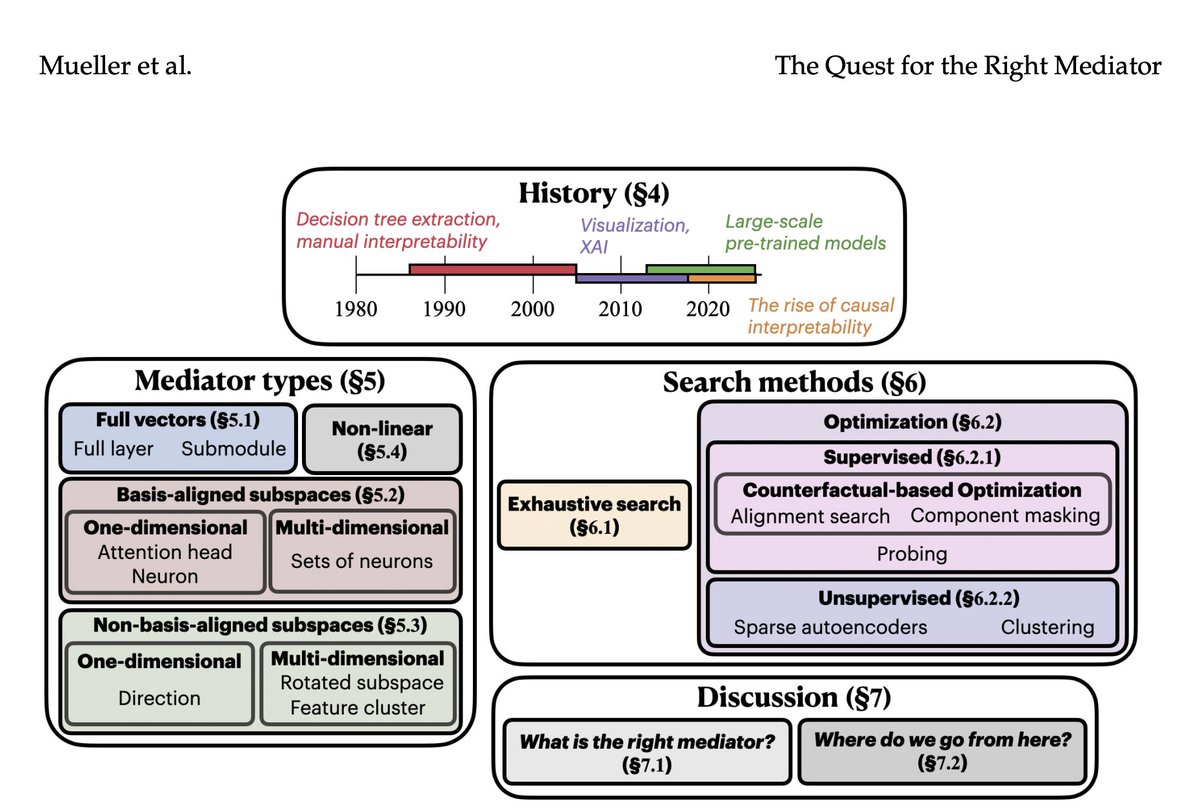
Interpretability provides a toolset for understanding how and why LMs behave in certain ways. This survey proposes a perspective on interpretability research grounded in causal mediation analysis: https://t.co/1tnGjMaruQ #NLProc#CLJournal@SunJiuding@ericwtodd
How Can We Effectively Expand the Vocabulary of LLMs with 0.01GB of Target Language Text? This article explores a very important question for low-resource languages by experimenting with various techniques across 10 languages.A must-read at:https://t.co/T0B9db6zlZ #CLJournal#NLP
Should NLP metrics for bilingual code-switching use words as the token level or Intonation Units? Authors of this article show that intonation units will enhance comparisons between bilingual individuals, settings, and communities: https://t.co/L7oJHFAReT #NLProc@rpattichi
Have you heard of soft metrics such as soft micro F1? In this article, the authors argue that for evaluating model predictions with human label variation, the standard metrics may not be sufficient. Read more at: https://t.co/Pi3VJRRnIw #NLProc
To assess whether multilingual NLP performs well across languages, we need to evaluate it on all world languages. That is not feasible. This paper implements two sampling methods from linguistic typology and provides a Python package to facilitate this: https://t.co/81YkTnERaU
Developing methods to assess the factuality of LLMs has become urgent. This paper presents LLM-OASIS for the factuality evaluation task. It turns out it significantly challenges SOTA LLMs. If you're up for improving over what's out there, start reading: https://t.co/9wuoDmt2qz
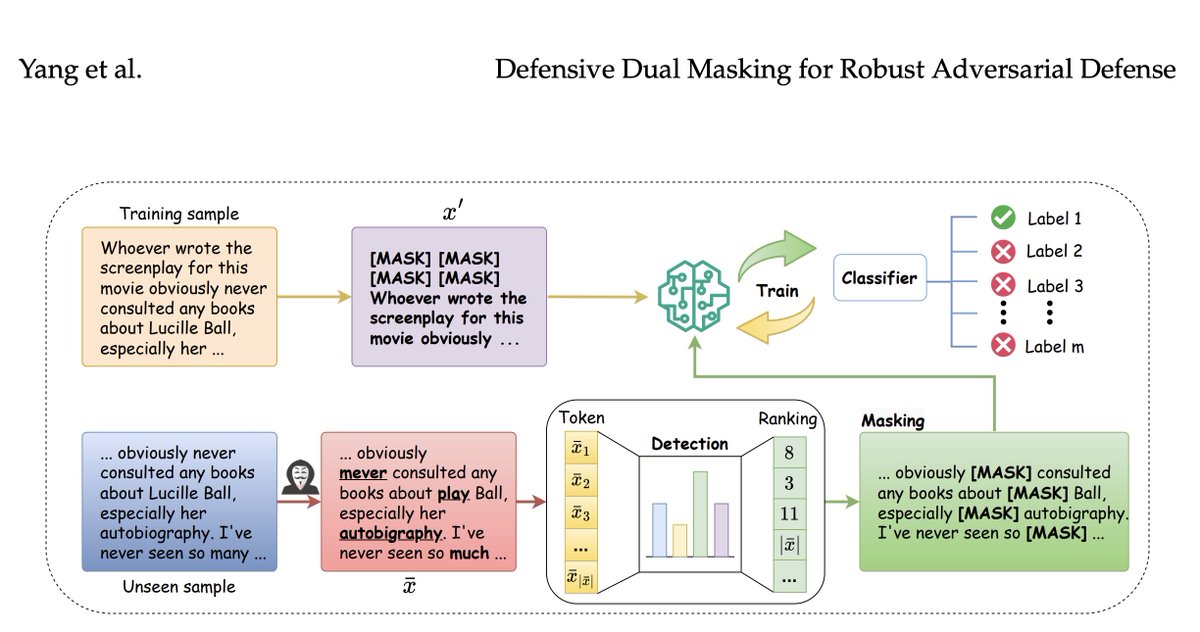
Language Models are susceptible to adversarial attacks, where even subtle perturbations to input texts adversely affect model performance. Yang et al. propose a novel method to tackle this called Defensive Dual Masking (DDM). Read more at: https://t.co/XkXxkrwXZK #NLProc#NLP
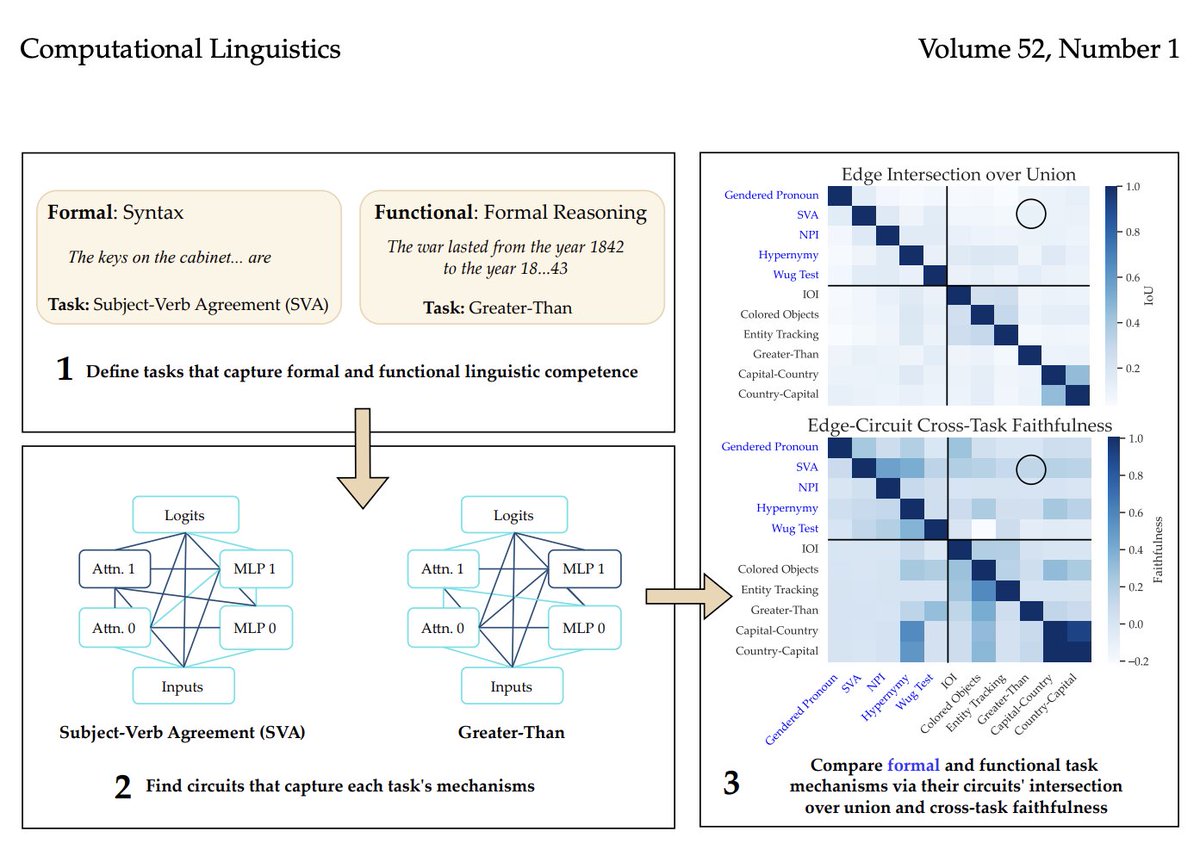
Do current LLMs with fast-improving functional linguistic abilities exhibit distinct localization of formal (e.g., producing fluent, grammatical text) and functional (e.g., reasoning and consistent fact retrieval) linguistic mechanisms? Answer in: https://t.co/fH9fgqlXDU #NLProc
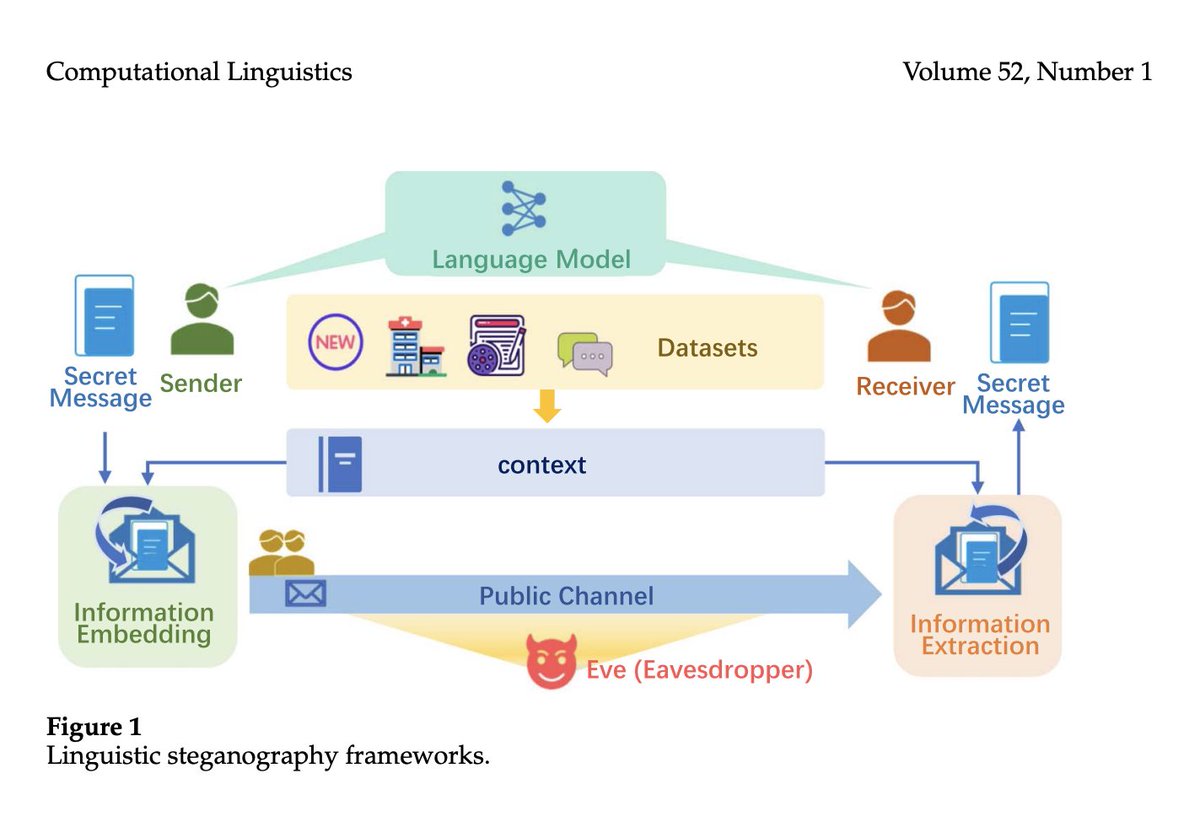
Have you heard of linguistic steganography? It seeks to conceal secret information within natural language text. Liu et al. propose a novel method called SA-ANS. It's a self-adaptive framework based on a self-adjusting Asymmetric Numeral System: https://t.co/Y5Eneg7IdQ #NLProc
If your research is around metaphor detection and interpretation, this article is for you! It introduces Meta4XNLI, the first parallel dataset for Natural Language Inference (NLI), in both English
and Spanish: https://t.co/GAmhTKtbQU #NLProc
Volume 52, Issue 1 of Computational Linguistics is released 📣
You can access this issue at https://t.co/vwzmM76qBy
The articles included in this issue will be introduced here and on 🦋 https://t.co/HseAigIYNZ! #NLProc#NLP
What % of the NLP papers measure their impact in the real world? This paper proposes an "impact evaluation" of NLP models or systems for real-world usage, changing the research culture of NLP to focus more on real-world
impact and less on SOTA-chasing: https://t.co/3Ti5vUgdgs
Hallucinations pose a substantial challenge to the reliability of LLMs in real-world scenarios. Zhang et al. survey methods of detection, explanation, & mitigation of hallucination, & provide a taxonomy & list of benchmarks for evaluation in this paper:
https://t.co/KziULFXpyG
Generative AI has advanced. But, for complex problems, it's lagging. In this position paper, the authors propose Human–AI Co-Construction (HAI-Co2), a framework for human–AI cooperative problem solving that facilitates such interaction. Read more at: https://t.co/FUIucqQIhT #NLP
Tasks such as summarization, QA & timeline creation need temporal expression normalization. The authors propose a novel method that deals with the known problems of temporal expression normalization on data scarcity, language and domain adaptation:https://t.co/z96OYejNTf #NLProc