Can you solve this algebra puzzle? 🧩
cb=c, ac=b, ab=?
A small transformer can learn to solve problems like this!
And since the letters don't have inherent meaning, this lets us study how context alone imparts meaning. Here's what we found:🧵⬇️
At CVPR this week for a talk on neural geometry of large vision models. If you’re interested in interpretability or joining @GoodfireAI, come say hi. 🤠
A popular way to use the latest FLUX model is to provide a reference image alongside the text prompt to guide the model.
Surprisingly, in most cases, the model first writes the reference image information into the text tokens; only then does it use that to generate the image🧵👇
In 2023, we released ESD and UCE, unlearning methods for text-to-image diffusion models. After 3 years of research:
Tomorrow, I will be presenting why "Unlearning is not the goal" at Machine Unlearning for Vision workshop @CVPR
Hear me out 👀
🗓️: June 3rd, 2:20pm
📍: Room 1AB
The most popular way to interpret AI is missing the bigger picture.
Models think in curved shapes. But sparse autoencoders (SAEs) work with straight lines.
Can they still capture models’ curved neural geometry? Yes, but not how you might think! (1/7)
Neural networks have beautiful feature geometry, but do they have mechanisms that actually interface with those structures?
At @GoodfireAI this spring, we discovered one: a re-usable addition mechanism that reads/writes to Fourier features from prior work. 🧵
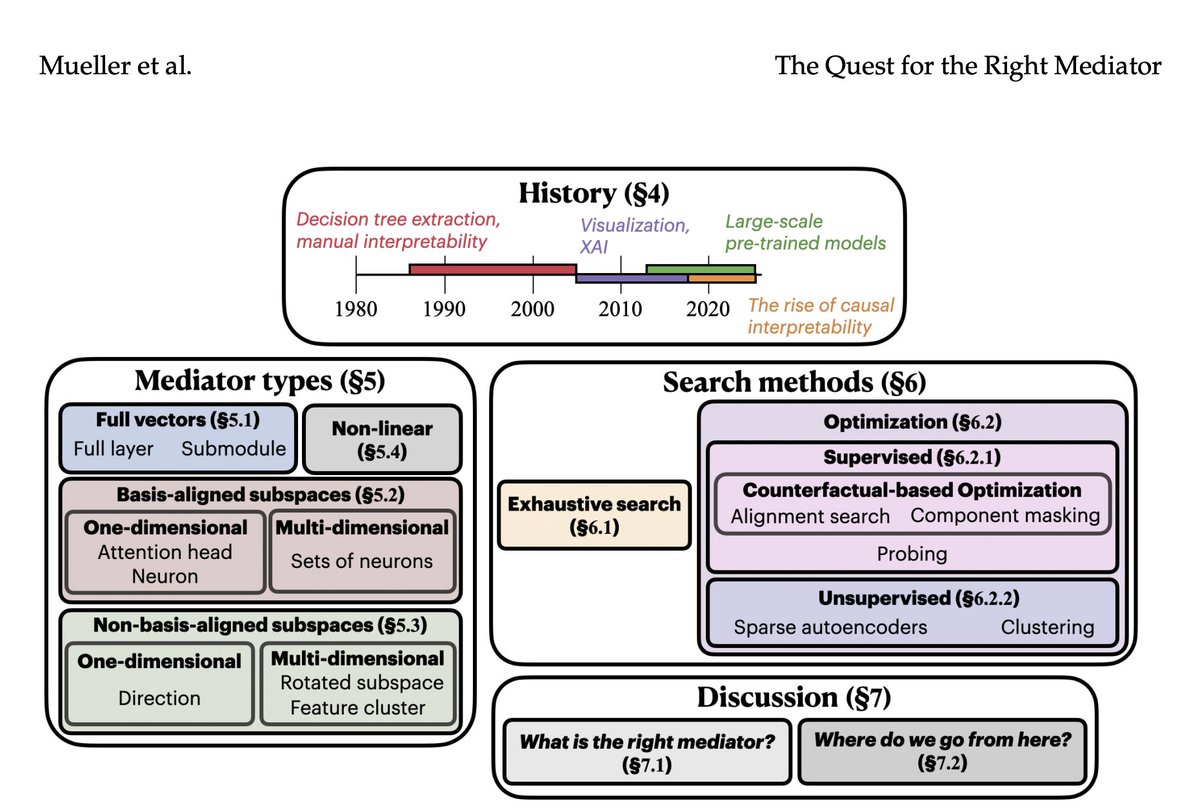
Interpretability provides a toolset for understanding how and why LMs behave in certain ways. This survey proposes a perspective on interpretability research grounded in causal mediation analysis: https://t.co/1tnGjMaruQ #NLProc#CLJournal@SunJiuding@ericwtodd
1/ (New paper!)
If swapping the gender in an input prompt makes the AI model give a different answer it means that it has to have a gender bias, right? Wrong.
🧵on counterfactual prompting for LLM evals:
Paper: https://t.co/i3Zc0UlyFF
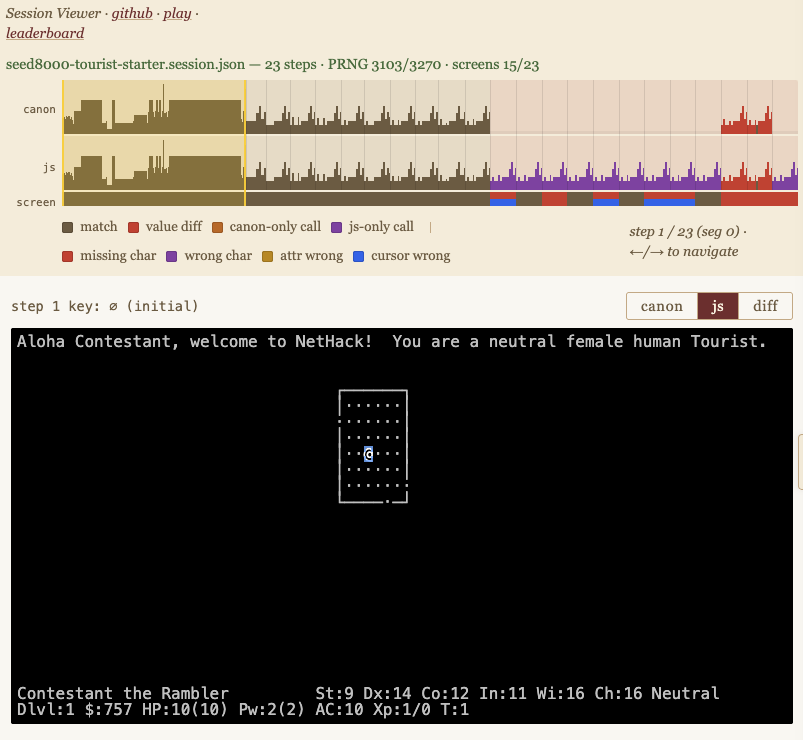
The Teleport Contest is open.
Port NetHack 5.0 from C to JavaScript, bit-exactly. Same screen, every keystroke. Any approach: LLM agents, hand-coded, transpiler, hybrid. Live leaderboard, two phases through December.
https://t.co/oOam7dCw1C
NetHack is one of the most complex and longest-lived open source programs ever written, and after 46 years, v5.0 shipped today.
https://t.co/ICEyakS6T5
And ... it is a VERY cool large codebase to work with in the LLM era.
I'll be attending #ICLR2026 next week to present my work on In-Context Algebra! My poster will be on Fri, April 24 at 3:15-5:45PM at Pavilion 4 P4-#4011. If you're around, stop by and say hello! My DMs are open if you want to connect or meet up in Rio!
2026 is a whirlwind year for AI.
Underlying it all: the greatest scientific mystery of our age. How does a neural network think?
I talked w @oliver_whang22 in NYTimes Magazine, on how AI interpretability is a tangle of structure waiting to be unraveled:
https://t.co/lYwxDFH1oH
I'll be attending #ICLR2026 next week to present my work on In-Context Algebra! My poster will be on Fri, April 24 at 3:15-5:45PM at Pavilion 4 P4-#4011. If you're around, stop by and say hello! My DMs are open if you want to connect or meet up in Rio!
Can you solve this algebra puzzle? 🧩
cb=c, ac=b, ab=?
A small transformer can learn to solve problems like this!
And since the letters don't have inherent meaning, this lets us study how context alone imparts meaning. Here's what we found:🧵⬇️
Excited to be attending #ICLR in person this year! I’ll be presenting 3 works across the main conference and workshops. If you’re around, please stop by, say hi, and feel free to reach out if you’d like to connect!
New paper: LLMs encode harmful content generation in a distinct, unified mechanism
Using weight pruning, we find that harmful generation depends on a tiny subset of the weights that are shared across harm types and separate from benign capabilities.
🧵
Patients ask LLMs medical questions, but how they phrase it matters more than it should.
Our new preprint explores how different phrasings of patient health questions can lead to inconsistent conclusions, even with the same evidence. [1/6]
Full Paper: https://t.co/CPhz94eAfc
If you enjoyed Anthropic's recent emotions paper, check out our pre-print! We find many many similarities:
1) Circular geometry of emotion representations that resembles the "Circumplex Model of Affects" from psychology
2) Steering effects on affective properties of LM outputs -- unlike Anthropic, we steer along the circular manifold (at 0°, 30°, 60°, etc.)
3) Steering effects on other downstream behavior (refusal, sycophancy) -- steering emotion representations can affect refusal/sycophancy rates.
The last one was a bit unexpected - we provide a mechanistic account for why this might happen.
See Lihao's thread below for details!👇
📣 Launching monthly interp puzzles 🧩
Each month: a model trained on a toy task. Your job: reverse-engineer the algorithm it learned.
First puzzle: how does a 1-2L attn-only transformer find the max of a list? Starter Colab included.
Deadline: April 30
https://t.co/wAwAzcO1IP
Calling attention to an exciting "deception detection" hackathon we're planning this summer! w @NDIF and @CadenzaLabs.
Recruiting red teams now, blue teams later. Red teams, time is short: proposals due Mar 31. $10K stipend + compute, $15K finals prize.
https://t.co/Lzbh5ThTBT


































![hyesunyun's tweet photo. Patients ask LLMs medical questions, but how they phrase it matters more than it should.
Our new preprint explores how different phrasings of patient health questions can lead to inconsistent conclusions, even with the same evidence. [1/6]
Full Paper: https://t.co/CPhz94eAfc https://t.co/Qcx3AgnjgJ](https://pbs.twimg.com/media/HFZTN6jWYAAhPa7.jpg)




















