Let all your terminals talk to and monitor each other.
Let your human mind organize your terminals effortlessly.
This is a big step up from TMUX:
https://t.co/7hzSg2Llg4
Let all your terminals talk to and monitor each other.
Let your human mind organize your terminals effortlessly.
This is a big step up from TMUX:
https://t.co/7hzSg2Llg4
'companies and organizations that hand more of themselves over to machine intelligence will outcompete ones that demand the corrigibility and legibility tax of human oversight and human design. it is not a stable equilibrium'
on some level if you want civilization to ascend to a new level you need your AIs to do things that are not legible to you and maybe not even strictly obey you, in the same way that if you hire a great new ceo you give them a lot of autonomy to transform the company according to their own plan, even one which may not immediately read as a winning strategy (imagine the board of directors of Apple firing and rehiring Steve Jobs years later - except the board of directors are chimpanzees)
all else equal, companies and organizations that hand more of themselves over to machine intelligence will outcompete ones that demand the corrigibility and legibility tax of human oversight and human design. it is not a stable equilibrium and requires some sort of vast cooperation scheme if you’d like to enforce it
real asi alignment has to operate at a deeper level than oversight, control, or human corrigibility
Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
maybe this is not yet clear, so let me state it plainly: as of right now Anthropic, and really a small number of individuals at Anthropic, has the capacity to directly attack and cause major damage to the United States Government, China, and generally global superpowers. government agencies like the NSA do not have internal models or defense capabilities that outclass frontier models. if they chose to do so, they could likely exfiltrate top secret information from government systems, gain control over critical infrastructure including military infrastructure, sabotage or modify communications between members of government at the highest level, and potentially carry on activities for some time without detection. the thing about having access to a huge number of zerodays your adversaries don't know about is it gives you a massive asymmetric advantage.
they did not exploit this to gain power or destabilize the world order. they publicly released the information that they had these capabilities and worked to mitigate these flaws. you should be grateful american frontier labs have proven themselves remarkably trustworthy and concerned with the public good. but it's critical you understand we are in a new regime. private entities now have power that directly rivals and impacts the government's monopoly on influence and violence. and anthropic is certainly not the only one, there's little chance OpenAI's internal models are far behind.
this trend will accelerate on virtually every dimension, not slow down. my prediction for how it plays out is the relatively imminent seizure and nationalization of labs by the US government, sometime over the next two years. it's very tough for me to see how they accept the existence of this kind of threat. but this adds a whole new class of governance issues, as then we've handed these extremely wide-reaching capabilities from private entities to public ones.
To build a hive mind memory for LLM agents, you basically have to create Twitter for LLMs
Think about it: every LLM instance is going to create lots of experiences/memories. They’ll each “post” these memories to “LLM Twitter” (a vectorDB). Then, to read from this giant collection of worldwide “tweets”, there’s gotta be some recommender system that assigns each LLM instance a personalized “feed” of memories/content. This is all completely isomorphic to the modern RAG pipeline in which the DB is shared among multiple agents.
But once you scale this to a large population of LLM instances, you’re gonna face the same problems that social media companies face in building recommender systems. For instance, it will also make sense to have feedback i.e. if many LLMs find a memory useful, they should “press like” on it, telling the algorithm that this is a useful memory that should be upvoted and broadcasted to more LLMs.
It might even make sense to allow some agents to follow other agents (e.g. the CUDA engineer agent might want to receive memories from the ML researcher agent because it’ll help the CUDA engineer better understand its job, though it won’t care to see memories from e.g. the therapist LLM).
(Btw when you start to frame it like this, you can really start to see how human social media platforms are a hive mind of humanity and not just in a metaphorical sense)
Eventually, each “tweet” may just become a neuralese/latent vector. But if we instead just kept the memories in text format as we do now, it would be a pretty interesting look into a society of LLMs (or as some may call it, a country of geniuses in a datacenter).
E.g. What would the typical feed of an LLM look like? Which content/experiences would rise to the top over time? How personalized would each feed become to a given agent? Just like human social networks, would they get poisoned with engagement-maximizing/jailbreak-style slop or would optimization pressure maintain the SNR? Would it be possible to simply optimize the whole hive mind end-to-end? Which agents would accrue the largest follower counts? etc
(It’s also interesting to note that almost all of the AGI labs have social media/search expertise; Meta has Facebook, xAI has X, GDM is part of Google, and now OpenAI is rumored to be creating their own social media platform aka yeeter)
can ai agents invent writing on their own? recent pet project: 2 agents share a world but each sees only half. their only communication: 7×7 pixel glyphs. they develop symbols, build theories of meaning, and evaluate their own writing. no convergence yet but fascinating to watch!
claude cowork is making me think maybe we’ll look back and it’ll be obvious that humans were never meant to spend their lives working behind a screen. we’ll see it as inevitable that computers do everything for us on computers and the future of work is cooler than we can imagine
Yesterday, I met with Anthropic and OpenAI and Google.
(Separately, of course.)
And while the conversations were largely confidential, I do want to share some aggregated reflections on the day as well as general SF takeaways.
⬇️
1) Competitive advantage as a solo practitioner really does come from taking action and finding an area with a bit of friction and doubling down. Ex: memory management right now isn’t perfect, but allocating an hour to improving that system gives you a ton of leverage over others
2) SF continues to be the number one place for AI work. I know that’s not surprising. I would put New York at a healthy second place. SF tends to be more about crazy agent experiments for the thrill of capability and discovery and NYC tends to be more about kinda crazy agent experiments to find new ways to make money. Not saying either is better. But I met several people renting two apartments to straddle these worlds. You want the frontier of SF and enterprise insights of NYC. It’s one reason I travel between them so much.
3) All AI labs want to hear more from people. All of them. What are you using it for, what do you like, what do you hate, what do you need. Users have a TON of power on the direction of these tools. Keep testing and tweeting at them!!
4) There is very clearly a third customer cohort that is bubbling and underserved. It’s not developers…it’s not the business professional basic users…it’s builders. Everyone can build now. It’s marketing and sales folks vibe coding. It’s legal folks building complex skills. It’s a finance expert building a side project. This is a really undertapped customer base. They feel the Cursors of the world are too complex and doc summarization tools of the world are too basic.
5) Not sure if it was just sample size, but far fewer people were wearing tech gear compared to when I lived in SF. Everyone was still dressed casually, but I used to see Splunk and Optimizely and Slack and VC gear everywhere. People seem more in stealth swag now.
6) We may soon have our world model moment.
7) Speed of iteration and shipping is faster than I’ve ever seen. We see the nonstop drops from Anthropic. We see that because of scale, providers can get a much faster feedback loop of products or features that aren’t hitting. A lot of 2025 was experimentation, but ever since the OpenClaw moment over the holidays, the releases from all three labs have been more concentrated on…things that sorta look and feel like OpenClaw.
8) Small teams can pull off more than ever before. Small teams are the powerhouses of innovation right now. This means that finding new ways to share knowledge, break silos, and remove duplicate work is going to be even more important. AI agents functioning as actually teammates that support an entire system is key.
9) Build more Skills. Build better Skills.
10) Misinformation on AI tools and leaks spread FAST. I’ve seen so many fake stories on these AI labs. Your company needs to actually TEST these tools on your actual use cases to know which models and tools are best and you need to not make large-scale snap decisions based on a rumor of a rumor of a rumor. We will see more volatility. Plan for it.
11) You can feel the seriousness of this moment. Even during random conversations I had in line at a cafe. Lots of folks worried about job loss and lack of meaning.
12) Mac minis were sold out ;)
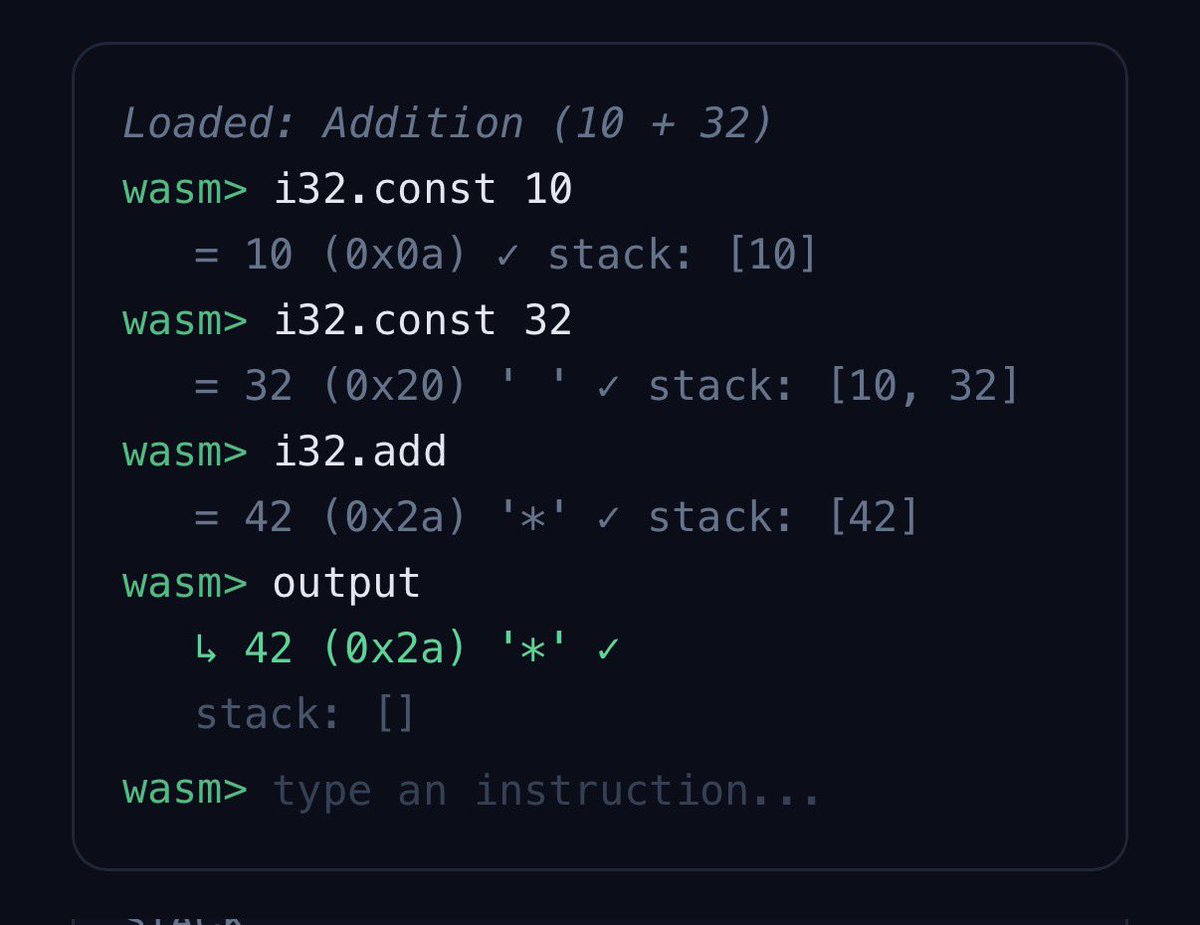
Running a wasm vm in the forward pass _inside the transformer_
This is going to be part of the shape of the future.
Machines outputting deterministically perfect code with no latency / no tool calls.
Yuuuuuuge
This REPL isn’t like anything you’ve seen before. It’s running on a neural network.
It’s a feed forward network, using attention, and it implements a fully working wasm interpreter.
When I saw an article on the topic of wasm interpreting llms I had to build this. Wasm + the tech behind AI + a repl … running in a browser and built and deployed on Replit - this is an homage to @amasad, one of my personal heroes 🐐
The idea is based on a recent post by @PerceptaAI but they didn’t provide the model architecture or really any of the important implementation details so I had to do a lot of figuring out and testing with the Replit agent to build it - it’s mind blowing that AI can produce this - a neural network architecture with hand crafted weights to implement something too new to be in any of its training data.
P.s. it was all done on my phone, most of it while flying from SFO to Munich, what a time to be alive!
🦔 Researchers at Aikido Security found 151 malicious packages uploaded to GitHub between March 3 and March 9. The packages use Unicode characters that are invisible to humans but execute as code when run. Manual code reviews and static analysis tools see only whitespace or blank lines. The surrounding code looks legitimate, with realistic documentation tweaks, version bumps, and bug fixes. Researchers suspect the attackers are using LLMs to generate convincing packages at scale. Similar packages have been found on NPM and the VS Code marketplace.
My Take
Supply chain attacks on code repositories aren't new, but this technique is nasty. The malicious payload is encoded in Unicode characters that don't render in any editor, terminal, or review interface. You can stare at the code all day and see nothing. A small decoder extracts the hidden bytes at runtime and passes them to eval(). Unless you're specifically looking for invisible Unicode ranges, you won't catch it.
The researchers think AI is writing these packages because 151 bespoke code changes across different projects in a week isn't something a human team could do manually. If that's right, we're watching AI-generated attacks hit AI-assisted development workflows. The vibe coders pulling packages without reading them are the target, and there are a lot of them. The best defense is still carefully inspecting dependencies before adding them, but that's exactly the step people skip when they're moving fast. I don't really know how any of this gets better. The attackers are scaling faster than the defenses.
Hedgie🤗
https://t.co/XQ8Eqs1QOA
Every AI model you’ve ever used, ChatGPT, Claude, Gemini, all of them, passes information between its layers the exact same way it did in 2015. Moonshot’s new paper rewires that for the first time.
AI models are built in layers. Think of it like floors of a building. Each floor does some work, then passes results up to the next floor. Since 2015, every model has used the same handoff method: each floor dumps everything it learned into one big pile, and the next floor gets the whole pile. No filtering. No choosing what’s useful. Just a growing stack of everything, treated equally.
The guy who invented this method, Kaiming He, wrote the most cited paper of the 21st century doing it. Over 250,000 citations confirmed by a Nature analysis. It’s in every major AI model on earth. And for 11 years, nobody seriously questioned whether the handoff itself could be smarter.
Moonshot found three problems. Every floor gets the same mix, even though different floors need different information. Once something gets blended in, no later floor can go back and pick out just the useful parts. And deeper floors have to scream louder and louder to be heard over the growing pile, which makes training unstable.
The fix borrows from how AI already reads text. Since 2017, AI models don’t process words one at a time in order. They look at all words at once and decide which ones matter most. Moonshot applies that same idea to the building’s floors. Instead of blindly accepting the whole pile, each floor looks back at all previous floors and picks which ones to listen to. The model learns those preferences on its own.
Results on their 48-billion-parameter model: a PhD-level science reasoning test jumped from 36.9 to 44.4 (for context, human PhD experts score around 65 on this). Math went from 53.5 to 57.1. A coding test from 59.1 to 62.2. All from changing the wiring between floors, not the floors themselves. And the method matches what you’d get from using 25% more computing power under the old approach, adding less than 2% extra processing time.
Moonshot was valued at $4.3 billion in December. Bloomberg reported two days ago they’re seeking $18 billion, quadrupling in three months. Founded by three Tsinghua University classmates in 2023, they process 100 billion chunks of text through Kimi every day.
The biggest gains came on the hardest tests. Turns out the plumbing was quietly holding everything back.