"The fact that someone like Martin Scorsese — one of the greatest, most impressive filmmakers to exist — is using our technology and curious about exploring it...it's such a great proof point that this works.”
- our CEO @robrombach in an interview with @brooksbarnes for the @nytimes. They discussed why Martin Scorsese joined BFL as an advisor.
At Black Forest Labs, we're building visual intelligence: AI models that can understand and reason in the physical and digital worlds. Scorsese is helping shape how our models serve creators who care deeply about their craft, whether they're storytellers, designers, engineers, or roboticists.
Link to article in the thread.
Meet "Tawan" (ตะวัน means “The sun” 🌞)
20-min Demo
AI Animated Film experiment (full feature is 90 mins)
With a $500 budget and 1.5 months of work, this story is based on my original idea from 2010... and today, the technology is finally ready to bring it to life.
AI showed me that solo creators can now manage an entire animation workflow. No need to pitch to big studios—you can fund yourself and bring your own stories to life. Without AI, this would still be stuck in my head.
(Of course, the quality is still far from high-budget films from big studios that have 300-600 people behind them, but I think the gap will close step by step in the future.)
This animated created by Seedance 2.0 on @dreamina_ai and @kinovi_ai and opening scene by @midjourney - thank you for watching.
Github : https://t.co/6NIj75xwo6
LoRA and workflow : https://t.co/LxjhfwqAF2
LogC3 decode Custome node (this node is also available already in LTXV nodes) : https://t.co/xrzZuyXYMv
SDR to HDR from ComfyUI, I've trained a LoRA over Qwen Edit 2011 based on the principle used in https://t.co/G2rdFOs1oJ
A research I've had the previlige to work on with @noamiKenKorem for video HDR on LTX.
Links for the LoRA and workflow (+ my fun grading node) below.
camera shot and angle reference chart for your subject with nbp
MCU = Macro Close Up
MS = Medium Shot
OS = Over the Shoulder
WS = Wide Shot
HA = High Angle
LA = Low Angle
P = Profile
ThreeQ = Three-Quarter View
B = Back View
prompt (+ ref image):
{ "project_name": "Auto_Cinematic_9_Angle_Grid_Generator", "version": "3.0 (Angle & Anatomy Focus)", "instructions_for_ai": { "step_1_analysis": "Analyze the input image for subject identity, lighting (e.g., prism effects, direction), skin texture, emotion, and color palette.", "step_2_inference": "If the input is a close-up, you must logically infer the subject's outfit, body type, and environment based on the style of the face. Maintain strictly consistent character design across all 9 panels.", "step_3_execution": "Generate a 3x3 grid where each panel corresponds to the specific camera definitions below." }, "camera_angle_specifications": { "MCU": "Macro Close Up: Focus intensely on facial details, eyes, or textures. Crop top of head and chin.", "MS": "Medium Shot: Waist or chest up. Standard cinematic portrait framing.", "OS": "Over the Shoulder: Camera placed behind a vague foreground element/shoulder, looking at the subject.", "WS": "Wide Shot: Full body shot. Show the subject's posture, outfit, and relationship with the environment.", "HA": "High Angle: Camera is physically higher than the subject, looking down. Emphasize vulnerability or diminishing size.", "LA": "Low Angle: Camera is physically lower than the subject, looking up. Emphasize dominance or stature.", "P": "Profile: Strictly from the side (90 degrees). Subject looks completely left or right.", "ThreeQ": "3/4 View: Subject turned 45 degrees away from the camera. Classic portrait angle.", "B": "Back View: Camera is directly behind the subject. Seeing the back of the head/body." }, "output_format": { "grid_layout": "3x3", "aspect_ratio": "16:9", "labeling": "Must include white text abbreviations (MCU, MS, etc.) in the top-left corner of each panel." }, "final_prompt_instruction": "Using the provided input image as the absolute ground truth for the character and style, generate a photorealistic 3x3 grid collage. You must strictly adhere to the 'camera_angle_specifications' defined above for each panel. Ensure distinct visual variety between the shots (e.g., a Wide Shot must look significantly different from a Close Up). The lighting and color grading must remain identical to the input source in every single angle.\n\nGrid Order:\nRow 1: MCU, MS, OS\nRow 2: WS, HA, LA\nRow 3: P, ThreeQ, B" }
McDonald’s just dropped a new AI ad and it’s beautiful and I am genuinely tired of people pretending this is not the future of media.
If this played on your TV during a normal commercial break, you would be disingenuous to say “its slop” or “I could easily tell it is AI.” It is a fantastic ad on its own merits, and it is obvious that AI video will eventually be one to one with reality, where you truly cannot tell the difference. if your of average intelligence and can extrapolate of course.
When we get there, then what? Is it still “slop,” or does “slop” permeate as a label for anything made with AI, even when you cannot tell at all?
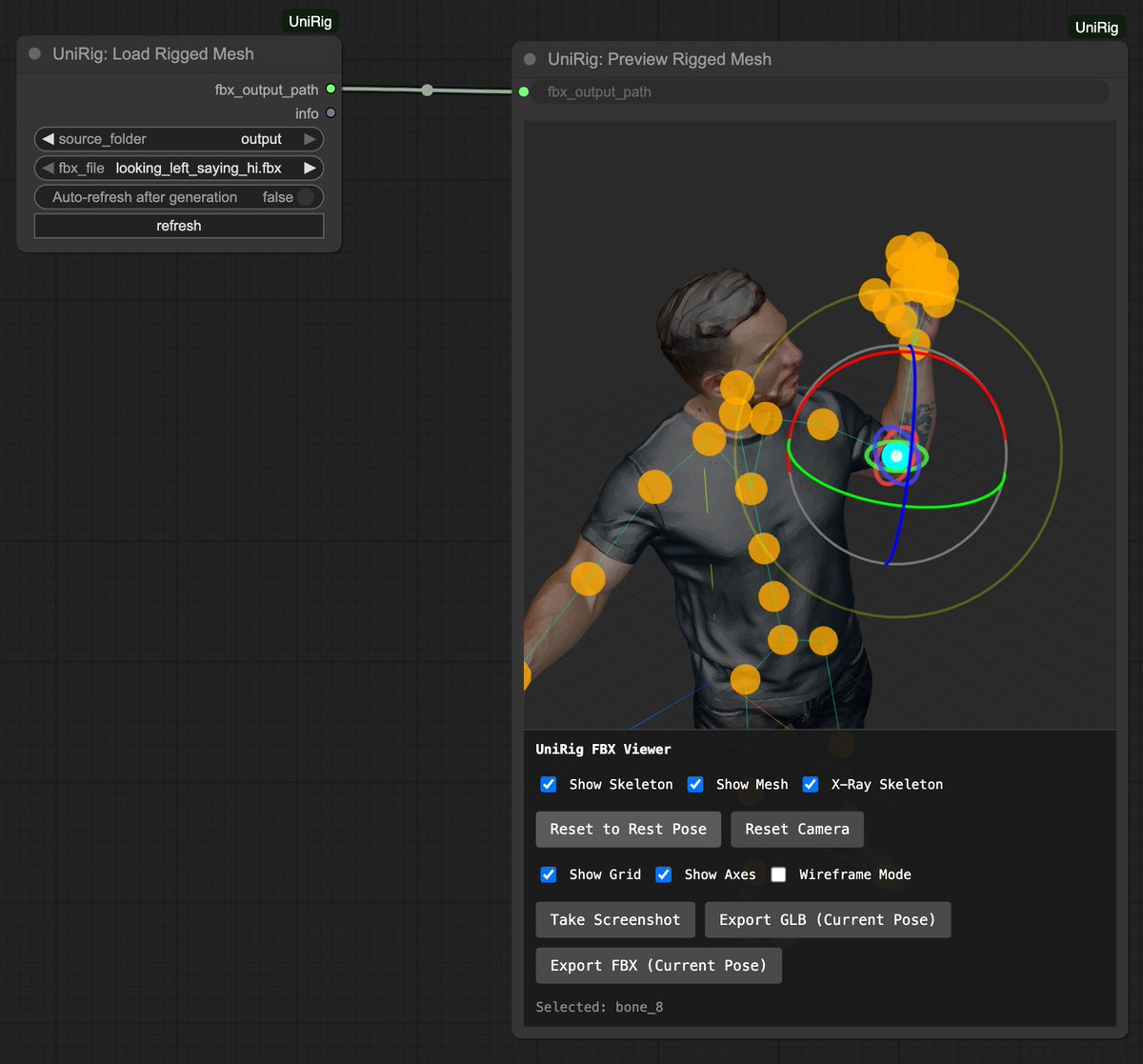
Dude, this guy is making some crazy comfyUI nodes.
Made SAM3, SAM 3D Body and SAM 3D Object all in like a day, then Depth Anything 3, also a cool 3D Geometry pack, but then also this thing.
This is a lot of pressure man. I want to test them all...
https://t.co/5pyknWTepQ
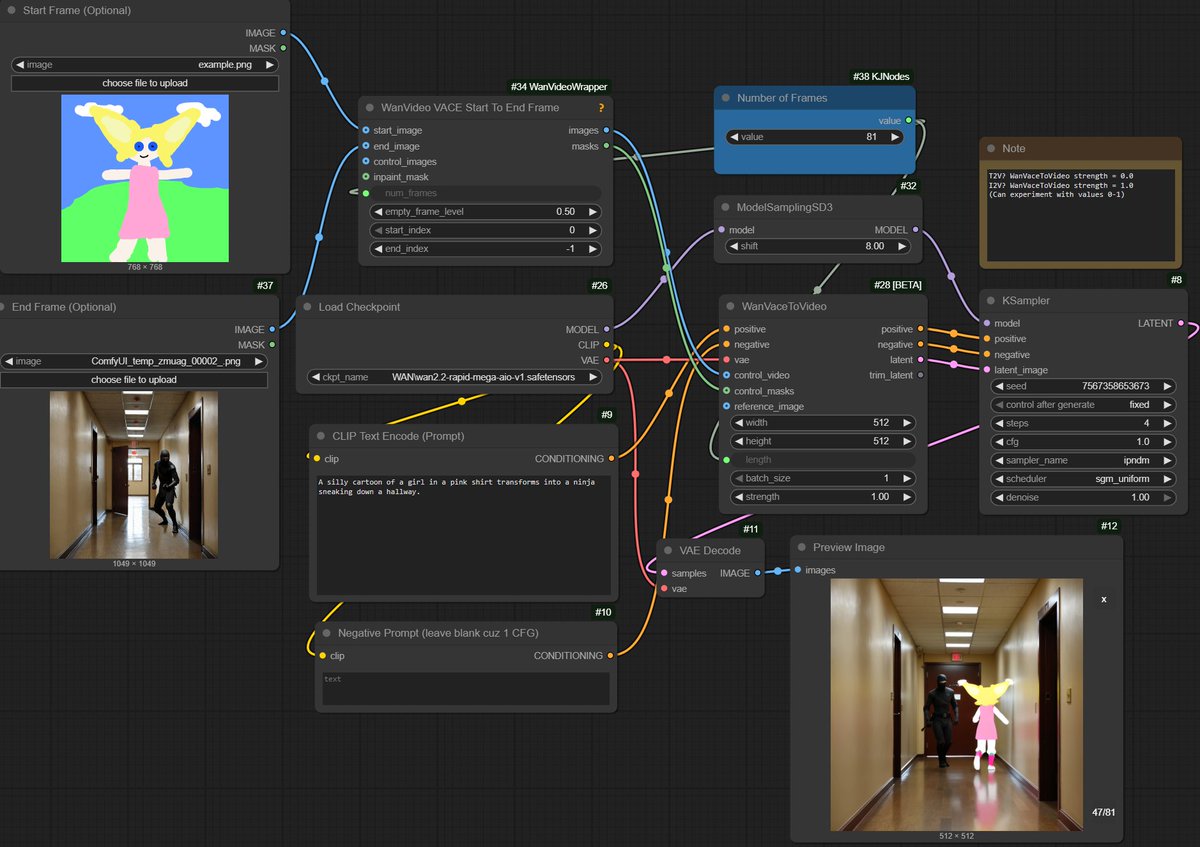
wan 2.1 (ローカルPC)で、実写入力動画をアニメ風表現・エフェクト表現に変換するワークフローとLoRAを作成しました(LoRA学習にはVidu1.0 t2vの動画のみを使用)
I made a workflow and LoRA to convert videos to anime style on wan 2.1 (local PC)
AI anime style v2v
Comfy3D Update: (v0.1.5.beta, dev branch) by our newly joined ML engineer: @Den_Kochetov⚡️
- Updated Hunyuan3D-2:
* Hunyuan3D-DiT-v2-0-Fast
* Hunyuan3D-2mini
* Hunyuan3D-2mv
* Hunyuan3D-2-Turbo
* Hunyuan3D-2mini-Turbo and FlashVDM
* Hunyuan3D-Paint-v2-0-Turbo
‼️@GoNeuralAI We are hiring skilled ML researchers & engineers (VAE, diffusion model, 3D/texture gen/editing) to join us on a mission to revolutionize 3D virtual production
🤌If you want to work on open-source projects (Not only Comfy3D), make an impact in the industry all while getting paid handsomely, hit me up in DM! (English | 中文 | 日本語)🆗
https://t.co/hrTyefto7Y
@taziku_co@ZHO_ZHO_ZHO@toyxyz3@RobinJHuang@ComfyUI@TencentHunyuan@neutanent
Kwai(Kling company) drop video controlnet
CineMaster:
A 3D-aware and controllable text-to-video generation method allows users to manipulate objects and camera jointly in 3D space for high-quality cinematic video creation.
For the nightly fellows, you can test it here: https://t.co/aNRpcDnTCh
⚠️ Beware: It’s slow, even on the L40S. But it delivers.
If you have any ideas to optimize, feel free to open a PR, and i’ll study it tomorrow 🤗
cc @kingnish24 🫡
Happy Chinese New Year, and thank you all for your love and support over the past year. On the last day of the Chinese Lunar Calendar year of 2024, we are thrilled to introduce to you the Blender plugin for Hunyun3D 2.0. Enjoy yourself! https://t.co/96klOrgeLZ