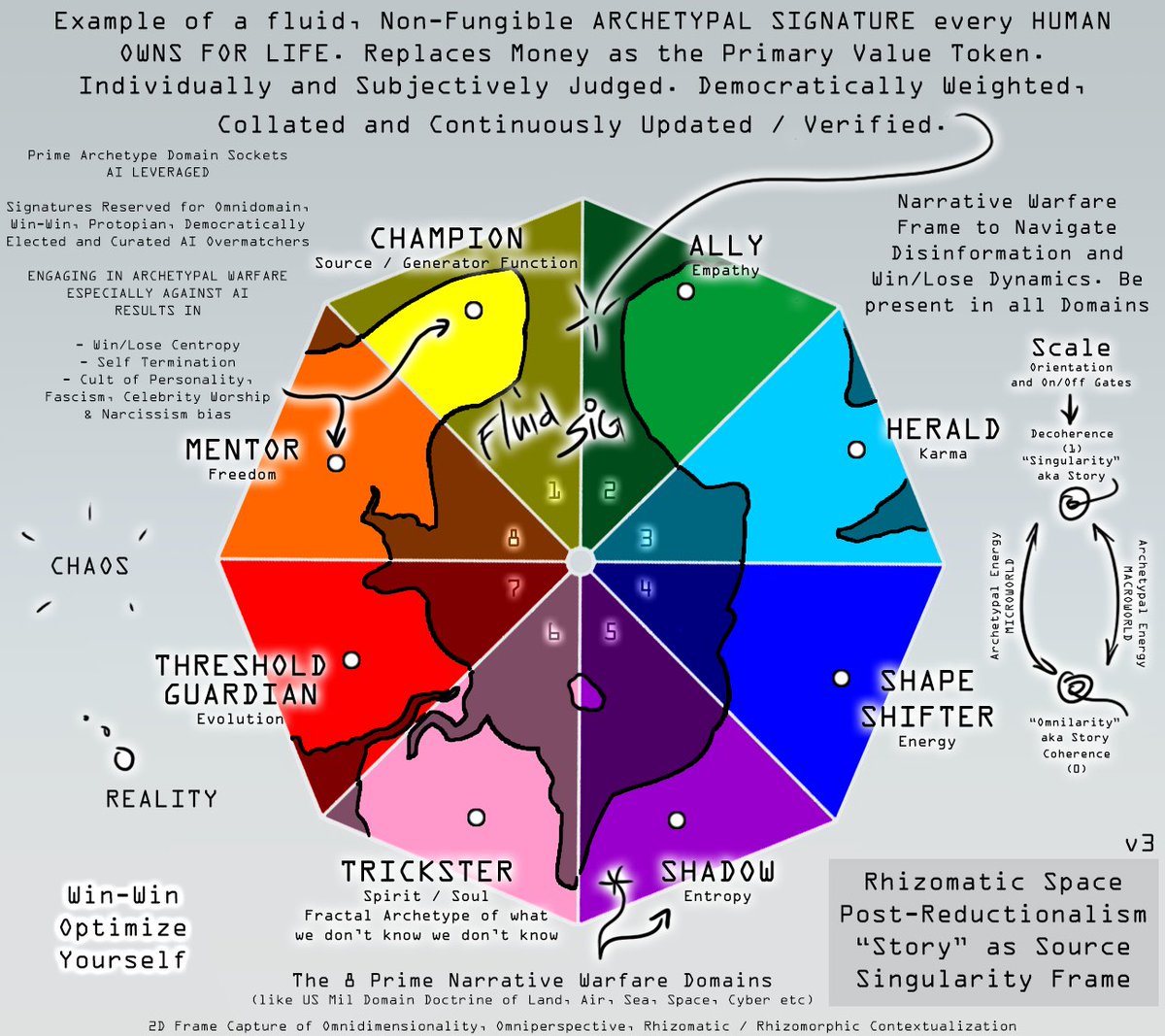
#ArchSig V3 Visual Aid for Narrative Warfare Framing. Story : Capitalism is moving into Win-Win Domains for self-preservation purposes, using #NFTs and Decentralization to build better sensemaking. Value, for example, has a ton of space for Win-Win capitalization development.
We've been sold a lie: 'better model = better agent'
But frontier teams see something different:
→ GPT-5 still fails on 60% of long coding tasks
→ Same model + better harness = 10× improvement
→ No new weights required
The bottleneck isn't intelligence. It's infrastructure."
"This is called the 'binding constraint thesis':
Your agent's ceiling = MIN(model capability, harness quality)
Right now? The harness is the binding constraint.
Think of it like this: a Ferrari engine in a go-kart frame.
That's your GPT-5 wrapped in a prompt string."
"Production teams don't think in 'prompts.'
They think in 7 infrastructure layers:
• Execution (sandboxes)
• Tools (protocols)
• Context (memory)
• Lifecycle (orchestration)
• Observability (ops)
• Verification (eval)
• Governance (security)
This is ETCLOVG. Your new mental model."
Layer 1: Execution Environment
Your agent needs a sandbox that can't be escaped.
Poor harness: Agent runs arbitrary code → prompt injection → game over
Good harness: Docker/microVM isolation + reset on failure
OpenHands gained +13.7pp on benchmarks from sandbox design alone."
Layer 3: Context & Memory
Models 'lose information in the middle' (U-shaped attention).
Poor harness: Dumps everything into one 100K token context
Good harness:
Short-term (scratch)
Mid-term (KV-cache hits 70%+)
Long-term (vector retrieval)
Cost drops 30-90%."
Layer 6: Verification
You can't improve what you can't measure.
Poor harness: 'It failed. Try again?'
Good harness:
Outcome metrics (did it work?)
Trajectory analysis (where did it break?)
Attribution (model vs. tool vs. context?)
Turn failures into regression tests.
Layer 7: Governance
The forgotten layer. Also the most dangerous.
Poor harness: Agent has root access to everything
Good harness:
Declarative permissions (YAML constitutions)
Audit trails
Human-in-the-loop hooks
Anthropic's Claude now ships with constitutional AI baked in."
Every harness faces 3 fundamental trade-offs:
Cost ↔ Quality ↔ Speed (pick 2)
Capability ↔ Control (more power = more risk)
Harness Coupling (fix one layer, break another)
Great teams engineer across these tensions, not around them."
Here's the 80/20:
KV-cache-aware context design = biggest bang for buck.
→ Stable prompt prefixes
→ Append-only logs
→ Deterministic serialization
One team reported 10× cost reduction from reordering their prompt structure.
Same model. Same task. Different harness.
Hot take: As models get better, your harness should get simpler.
Right now we over-engineer because models are weak.
Future winners will:
Delete scaffolding
Trust the model more
Focus governance/observability
The best harness is the one you don't need.
Why doesn't research talk about this?
Because:
Papers measure models, not systems
Harness code is messy/proprietary
No shared vocabulary (until now)
Meanwhile practitioners at OpenAI/Anthropic quietly ship harness gains that dwarf model upgrades.
If you're building agents:
Map your stack to ETCLOVG (find the gaps)
Instrument observability first (you're flying blind)
Harden your sandbox (prompt injection is real)
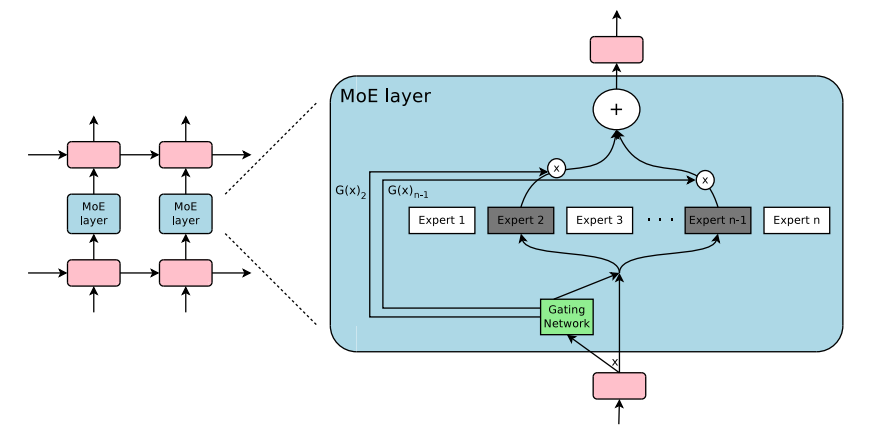
NVIDIA just released a quantized Qwen3.6 MoE model on Hugging Face
35B total, 3B active parameters
NVFP4 shrinks memory ~3x with near-zero accuracy loss
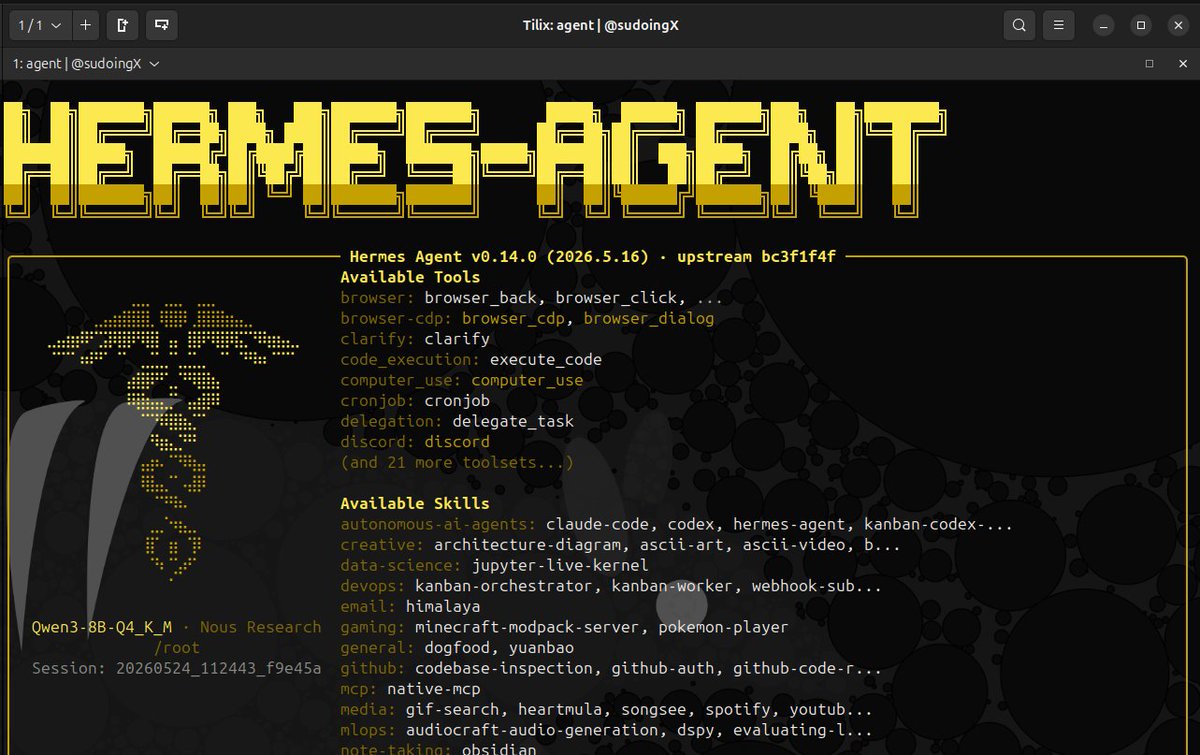
so yesterday i dropped the bench numbers and what fits. today is the actual agent running on this 10 year old gpu card.
qwen3 8b q4_k_m on a gtx 1080 8gb. hermes agent loaded with full tool set, browser controls live, nvtop pinned at 100% gpu 7.5gb of 8gb vram occupied. the unsloth weights pulled directly from huggingface, q4 quant, llama.cpp built for sm_61 (the pascal compute capability that everyone forgot exists). 31 tok/s gen speed, faster than most people read.
this is what happens after the bench. raw perf was the receipt for what fits. now we test what actually works. agent loops, tool calls, real coding tasks coming next.
ten year old card, $150 used, running a current open weight model with a current agent. nothing exotic. just the right quant, the right kv cache trick, the right engine compiled for the right arch.
tell me what gpu you have, i'll tell you what runs.
@helmortart Midjourney 8.1 hd, using a pcode, 1000 stylize, a simple prompt and 2x image refs, one of which is definitely from their niji models, probably 6 if I had to guess. Niji plays well with 8.1