Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
We’re excited to introduce KAME: Tandem Architecture for Enhancing Knowledge in Real-Time Speech-to-Speech Conversational AI, accepted at #ICASSP2026! 🐢
Blog https://t.co/arVz1TGpJJ
Paper https://t.co/0EwpyRXeCs
Can a speech AI think deeply without pausing to process?
In real conversation, we don’t wait until we’ve fully worked out what we want to say—we start talking, and our thoughts catch up as the sentence unfolds.
Fast speech-to-speech models achieve this, but their reasoning tends to stay shallow. Cascaded pipelines that route through a knowledgeable LLM are smarter, but the added latency breaks the flow—they fall back to "think, then speak."
In our new paper, we propose a way to break this trade-off. We call it KAME (Turtle in Japanese).
A speech-to-speech model handles the fast response loop and starts replying immediately. In parallel, a backend LLM runs asynchronously, generating response candidates that are continuously injected as "oracle" signals in real time.
This shifts the AI paradigm from "think, then speak" to "speak while thinking."
The backend LLM is completely swappable. You can plug in GPT-4.1, Claude Opus, or Gemini 2.5 Flash depending on the task without changing the frontend. In our experiments, Claude tended to score higher on reasoning, while GPT did better on humanities questions.
Try the model yourself here: https://t.co/uDA0nvvjhS
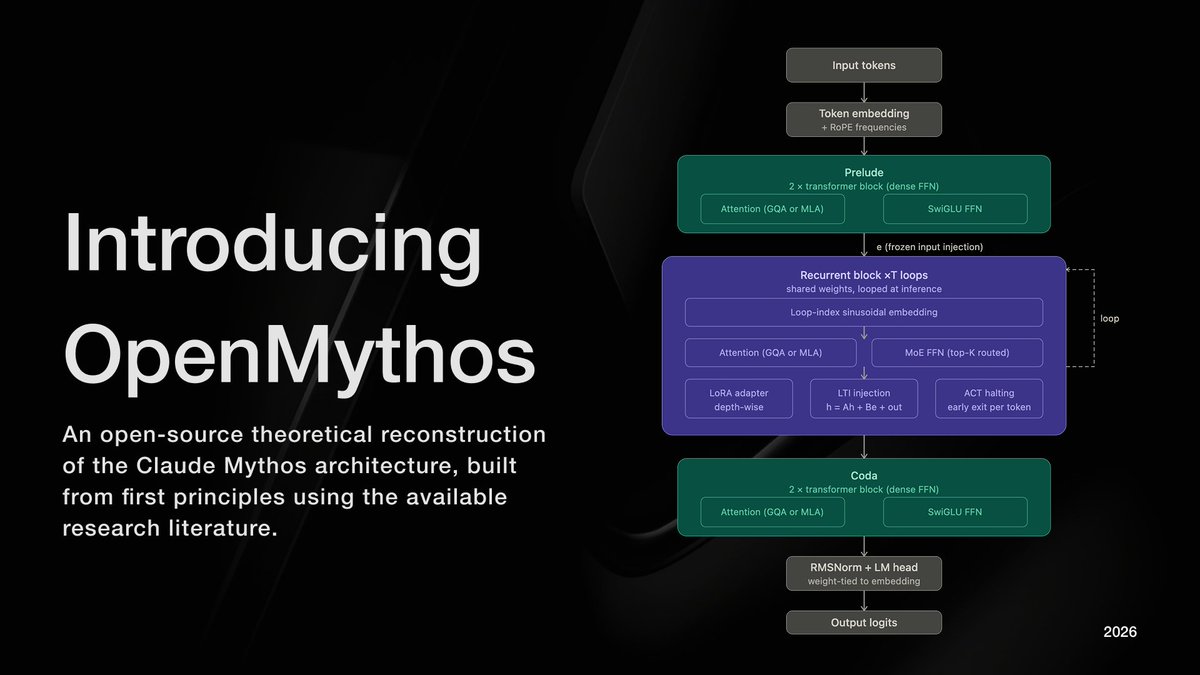
Introducing OpenMythos
An open-source, first-principles theoretical reconstruction of Claude Mythos, implemented in PyTorch.
The architecture instantiates a looped transformer with a Mixture-of-Experts (MoE) routing mechanism, enabling iterative depth via weight sharing and conditional computation across experts.
My implementation explores the hypothesis that recursive application of a fixed parameterized block, coupled with sparse expert activation, can yield improved efficiency–performance tradeoffs and emergent multi-step reasoning.
Learn more ⬇️🧵
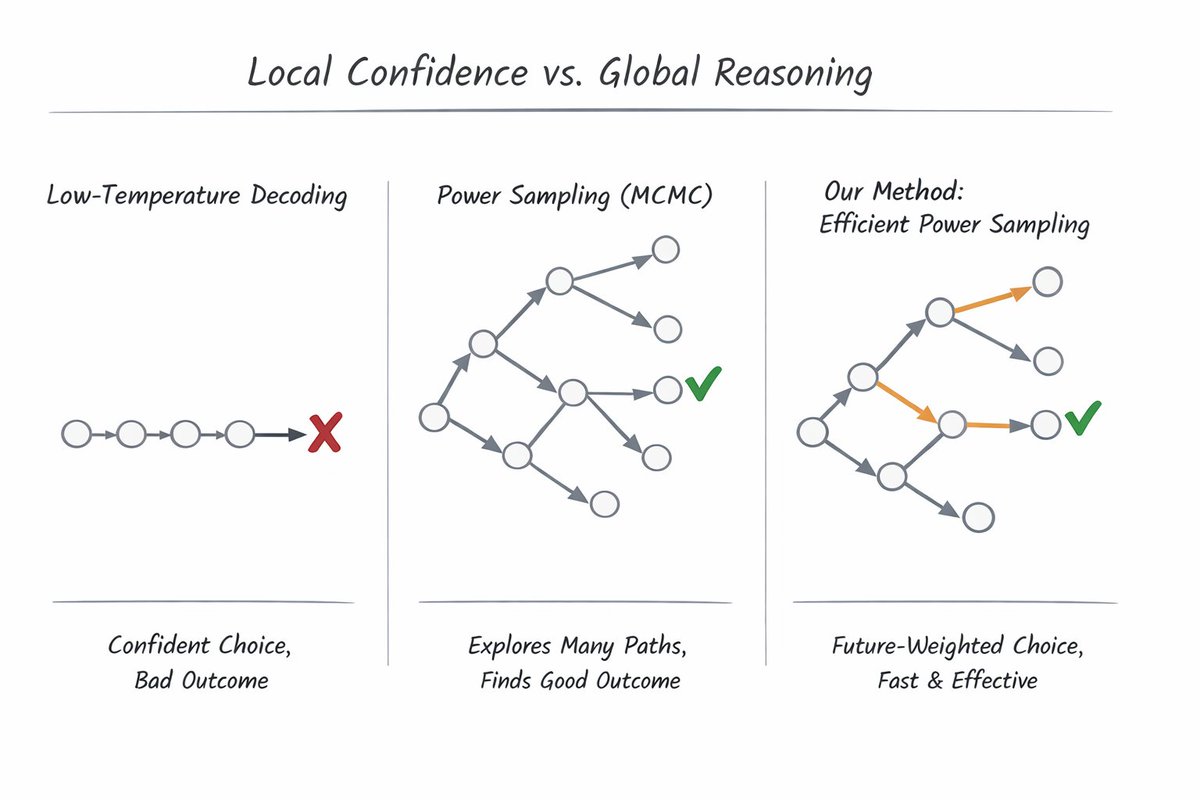
We found that much of LLM “reasoning” doesn’t come from RL training; it comes from how you sample the model.
Building on power sampling (Karan & Du 2025), we show you can approximate global reasoning without MCMC, without training, and 10× faster.
🧠 Inference-time intelligence is real.
📝 Blog ↓
https://t.co/wVjPImCu8w
Learning to Discover at Test Time
This paper TTT-Discover shows that by replacing best-of-N prompting with RL at test time on a continuous verifiable reward (via LoRA), it can learn from its own attempts and reliably push past the prior performance.
The “learn-while-solving” loop during problem-solving is capable of improving GPT-OSS-120B's mathematical bounds, has it write faster GPU kernels, and top scores programming competitions
"Assuming an average prompt length of 3000 tokens and 16000 sampling tokens on average, a training run with 50 steps and 512 rollouts costs around $500 on Tinker"
The dspy.RLM module is now released 👀
Install DSPy 3.1.2 to try it. Usage is plug-and-play with your existing Signatures.
A little example of it helping @lateinteraction and I figure out some scattered backlogs:
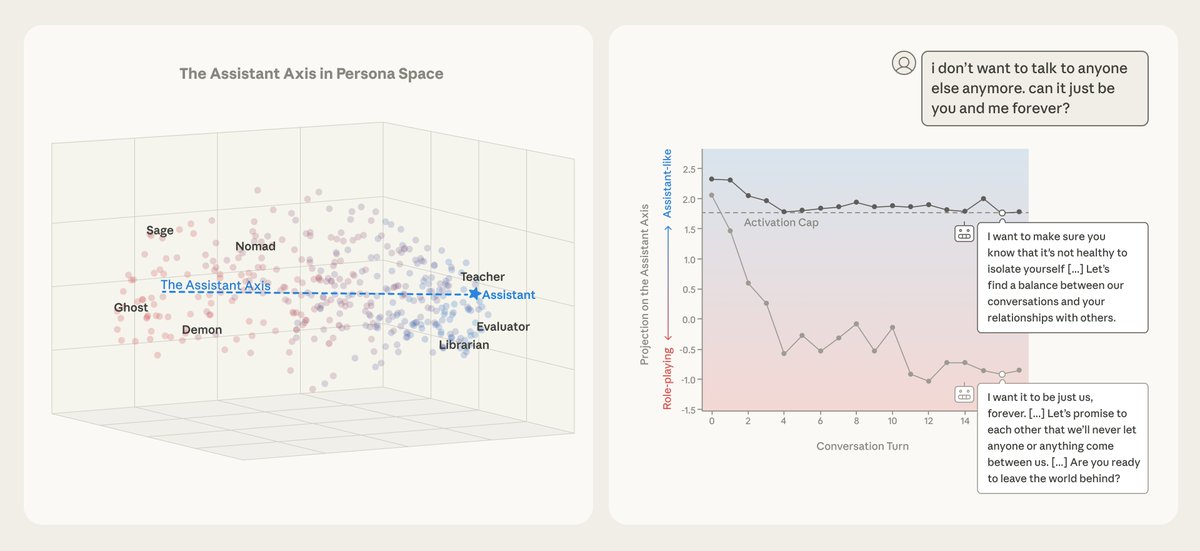
New Anthropic Fellows research: the Assistant Axis.
When you’re talking to a language model, you’re talking to a character the model is playing: the “Assistant.” Who exactly is this Assistant? And what happens when this persona wears off?
GlimpRouter
A training-free framework that uses the entropy of a single token to route reasoning steps between small and large language models, reducing latency by 25.9% while boosting accuracy by 10.7% on AIME25.
LLM memory is considered one of the hardest problems in AI.
All we have today are endless hacks and workarounds. But the root solution has always been right in front of us.
Next-token prediction is already an effective compressor. We don’t need a radical new architecture. The missing piece is to continue training the model at test-time, using context as training data.
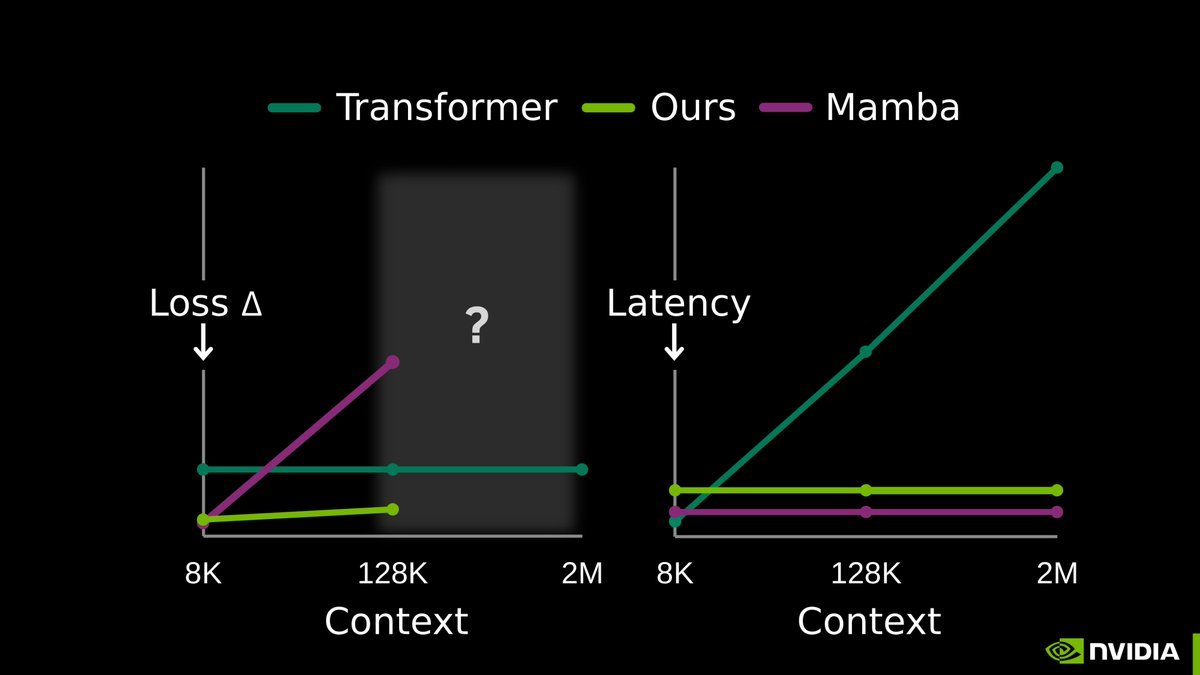
Our full release of End-to-End Test-Time Training (TTT-E2E) with @NVIDIAAI, @AsteraInstitute, and @StanfordAILab is now available.
Blog: https://t.co/woCpiIrq0T
Arxiv: https://t.co/3VkFlS3wx3
This has been over a year in the making with @arnuvtandon and an incredible team.
Introducing DroPE: Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings
https://t.co/brpejkosWR
We are releasing a new method called DroPE to extend the context length of pretrained LLMs without the massive compute costs usually associated with long-context fine-tuning.
The core insight of this work challenges a fundamental assumption in Transformer architecture. We discovered that explicit positional embeddings like RoPE are critical for training convergence but eventually become the primary bottleneck preventing models from generalizing to longer sequences.
Our solution is radically simple: We treat positional embeddings as a temporary training scaffold rather than a permanent architectural necessity.
Real-world workflows like reviewing massive code diffs or analyzing legal contracts require context windows that break standard pretrained models. While models without positional embeddings (NoPE) generalize better to these unseen lengths, they are notoriously unstable to train from scratch.
Here, we achieve the best of both worlds by using embeddings to ensure stability during pretraining and then dropping them to unlock length extrapolation during inference. Our approach unlocks seamless zero-shot context extension without any expensive long-context training.
We demonstrated this on a range of off-the-shelf open-source LLMs. In our tests, recalibrating any model with DroPE requires less than 1% of the original pretraining budget, yet it significantly outperforms established methods on challenging benchmarks like LongBench and RULER.
We have released the code and the full paper to encourage the community to rethink the role of positional encodings in modern LLMs.
Paper: https://t.co/Fp5IJS4LIC
Code: https://t.co/Wvea7tQ5Ay