ML Engineer | Master in Advanced & Applied AI | MSc Statistics | MSc Full Stack Web Developer | Math Teacher | Bachelor Engineering Sciences | From 🇪🇸🇨🇱
MiniMax M2.1 is officially live🚀
Built for real-world coding and AI-native organizations — from vibe builds to serious workflows.
A SOTA 10B-activated OSS coding & agent model, scoring 72.5% on SWE-multilingual and 88.6% on our newly open-sourced VIBE-bench, exceeding leading closed-source models like Gemini 3 Pro and Claude 4.5 Sonnet.
The most powerful OSS model for the agentic era is here.
🚀 Paper2Slides is now open source! Transform research papers & technical reports into professional presentations with ONE click!
We've generated stunning presentation slides from the latest DeepSeek V3.2 paper in diverse styles - check them out and share your feedback!
🔥 Core Features:
- 📄 Multi-format support - PDF, Word, Excel, PowerPoint & more
- 🎯 Smart content understanding - Captures key insights, figures, formulas, tables & data points.
- 🎨 Custom styling - Professional themes with full personalization.
- ⚡ Lightning fast - High-quality PPT generation in minutes.
GitHub: https://t.co/zNxlFifDU3
Never build slides from scratch again! ✨ Come play with it ⭐!
#Paper2Slides #AIPPT
📈 Metrax is the evaluation metrics library for JAX. It's fast, scales well, and fully open source.
Learn how it works in your training loop → https://t.co/7CqvDPgImE
We spent all night wondering what you were "actually" waiting for, and we finally have it:
Images as sources!!! Whether it's a photo of handwritten notes, a screenshot of a textbook or graphs on a web page, @NotebookLM can synthesize the information and produce outputs from it.
Google Colab is officially coming to @code! ⚡️
You can now connect VS Code notebooks directly to @GoogleColab runtimes. Get the best of both worlds: the editor you love, powered by the compute (GPUs/TPUs) you need. → https://t.co/prgImNfEd2
DeepSeek-OCR is the best OCR ever.
It parses this extremely hard to read handwritten letter written by mathematician Ramanujan in 1913 with a frightening degree of accuracy.
Not perfect, but beats former best dots ocr. Bonus points if you can spot the errors.
Try it here:
This is the JPEG moment for AI.
Optical compression doesn't just make context cheaper. It makes AI memory architectures viable.
Training data bottlenecks? Solved.
- 200k pages/day on ONE GPU
- 33M pages/day on 20 nodes
- Every multimodal model is data-constrained. Not anymore.
Agent memory problem? Solved.
- The #1 blocker: agents forget
- Progressive compression = natural forgetting curve
- Agents can now run indefinitely without context collapse
RAG might be obsolete.
- Why chunk and retrieve if you can compress entire libraries into context?
- A 10,000-page corpus = 10M text tokens OR 1M vision tokens
- You just fit the whole thing in context
Multimodal training data generation: 10x more efficient
- If you're OpenAI/Anthropic/Google and you DON'T integrate this, you're 10x slower
- This is a Pareto improvement: better AND faster
Real-time AI becomes economically viable
- Live document analysis
- Streaming OCR for accessibility
- Real-time translation with visual context
- All were too expensive. Not anymore.
Agentic Context Engineering
Great paper on agentic context engineering.
The recipe:
Treat your system prompts and agent memory as a living playbook.
Log trajectories, reflect to extract actionable bullets (strategies, tool schemas, failure modes), then merge as append-only deltas with periodic semantic de-dupe.
Use execution signals and unit tests as supervision. Start offline to warm up a seed playbook, then continue online to self-improve.
On AppWorld, ACE consistently beats strong baselines in both offline and online adaptation. Example: ReAct+ACE (offline) lifts average score to 59.4% vs 46.0–46.4% for ICL/GEPA. Online, ReAct+ACE reaches 59.5% vs 51.9% for Dynamic Cheatsheet.
Paper: https://t.co/AZRZe0axlI
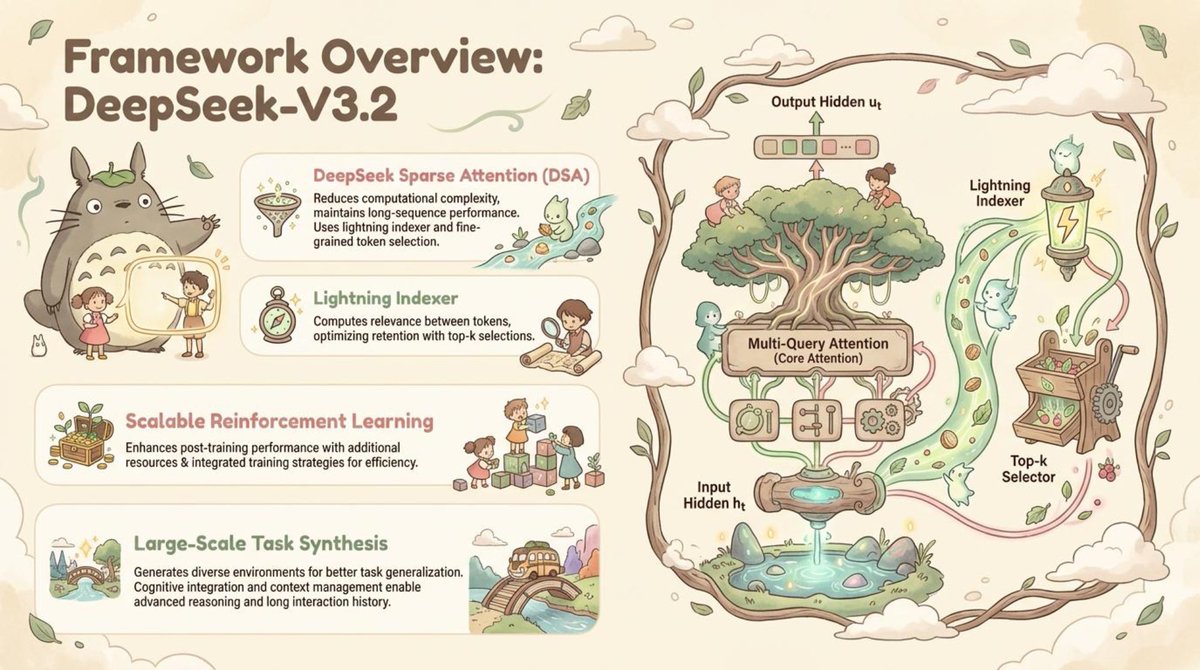
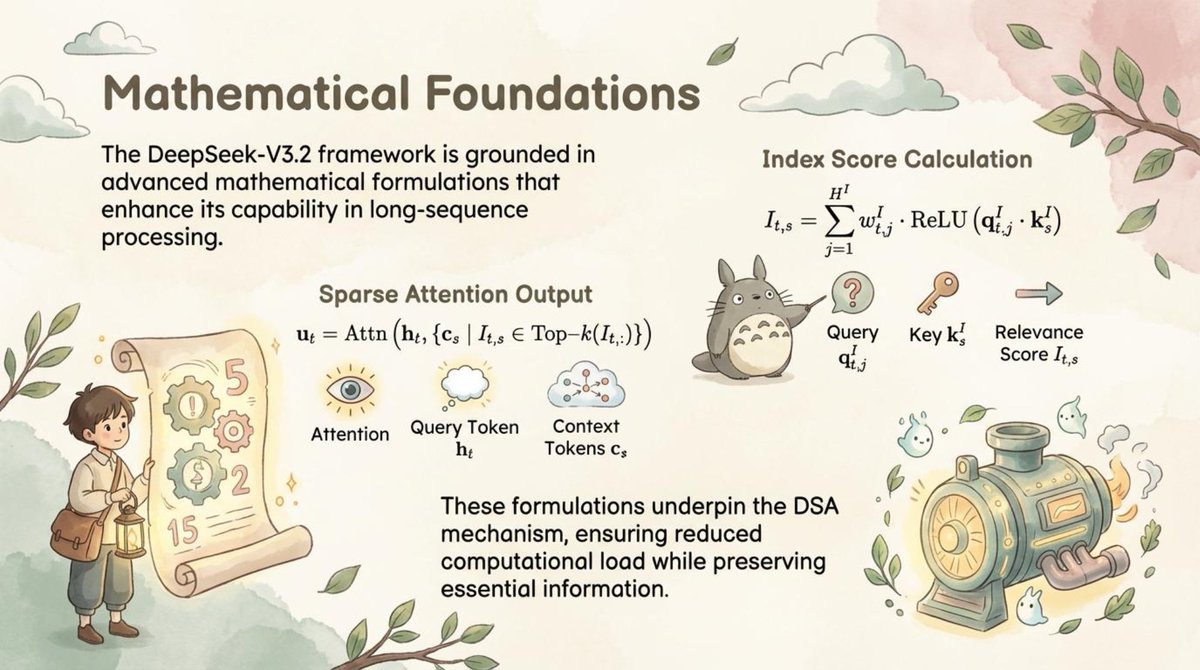
🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model!
✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context.
👉 Now live on App, Web, and API.
💰 API prices cut by 50%+!
1/n
Microsoft introduces Latent Zoning Network (LZN)
A unified principle for generative modeling, representation learning, and classification. LZN uses a shared Gaussian latent space and modular encoders/decoders to tackle all three core ML problems at once!
Updated & turned my Big LLM Architecture Comparison article into a narrated video lecture.
The 11 LLM architectures covered in this video:
1. DeepSeek V3/R1
2. OLMo 2
3. Gemma 3
4. Mistral Small 3.1
5. Llama 4
6. Qwen3
7. SmolLM3
8. Kimi 2
9. GPT-OSS
10. Grok 2.5
11. GLM-4.5