claude opus 4.8 + OpenClaw now finds restaurants with weak food photos, rebuilds their best dish into a cinematic reel, and mails the owner a postcard with the QR...on autopilot.
here's how agencies can land recurring contracts with this system:
- scans every restaurant in a city in real time
- pulls their real reviews, ratings, and reviewer-uploaded food photos
flags the weakest shot of their signature dish
- samples the brand color straight from the restaurant's own dish photo
rebuilds that exact plate into a cinematic 9:16 reel
- writes a printed postcard about their best dish
- mails it to the registered office, addressed to the owner, with a QR to the live reel
every step from the scrape to the reel to the mailbox is automated
reply "REEL" + RT and i'll send you a free guide so you can build this too (must be following so i can DM you)
🔴 I NEED YOUR ATTENTION
I've spent a month helping Miriam with her case of metastatic cancer and I want to share the methodology I've been using because it's completely replicable.
I think (with luck) this could be USEFUL TO OTHER PEOPLE with cancer (or any other illness).
The results we've gotten aren't a miracle, but we believe they're genuinely useful and could mean the difference in a literal life-or-death medical case.
Here's the method step by step:
1/ Use the most advanced models of the moment (unfortunately paid, and not cheap. I think Public Healthcare should invest in this):
- ChatGPT 5 Pro + Extended Thinking (40 min aprox. of thinking per call)
- Claude Opus 4.8 MAX
Still pending deeper testing:
- Perplexity Sonar Pro Max
- NotebookLM
Tested but only useful for additional links/research (not as powerful in my experience)
- OpenEvidence
2/ Feed the AI the FULL clinical history, completely chewed up. This sounds dumb but it's critical.
- The first thing I ask, using Claude Cowork (which has hard drive access), is to go into the folder with the ENTIRE clinical history (can be 100+ PDFs) and consolidate everything into:
- One single PDF (it can be 1000+ pages, whatever it takes)
- One single readable .txt or .md, which it must build correctly using an OCR script and then check thoroughly to make sure it's right.
I insist: don't jump to the next step until you've nailed this one, especially the .txt.
3/ Once you have the above, use this prompt along with the .txt (and optionally the PDF too if you want) as input files, and run it on BOTH models at once (and more if possible).
👉 This prompt is insanely complex/advanced: https://t.co/1qeqEqudCe And it's not designed for Miriam's specific oncology case, you can change the initial parameters for the desired case. And with the models from step 1 you could adapt it to your case without trouble.
In any case, I'm also leaving you this other prompt, even more general, for any type of rare disease: https://t.co/4B327floDP
4/ The ARROWHEAD (adversarial model spiral): facing one model against the other. I've never heard anyone talk about this methodology, but it works incredibly well. The feeling is like sharpening a stake until it gets a gleaming point.
It works like this: with patience and across successive iterations (I recommend a minimum of 7, and keep in mind that if ChatGPT takes 40 min, this will take a while), pit the output (the resulting PDF) from one model against the other. With a simple prompt like:
"Another committee of experts says this. What do you think? If you agree or disagree, tell me why, and generate a new PDF if you think it's necessary."
Then you feed that result back to the opposite model. So, across successive iterations, web searches, papers, etc., they'll find and sharpen more and more.
When to stop? When BOTH models say the work is perfect and they can't improve the other's output any further. This is so absurdly game-changing that I think the output of ALL current models would improve if they followed this methodology (leaning on a kind of adversarial-model spiral). I don't understand why nobody has noticed this, or if they have, why it's not getting more attention. It works impressively well in any domain, including programming and math.
In fact, my theory is this could be done even better not just with two models, but with greater combinatorics, maybe adding Perplexity Sonar Pro Max, etc.
RESULTS
Incredible. Obviously I can't know if they're better than the best scientific-medical committees in the world, but they're giving Miriam a new dimension to her case, additional tests to do, possible exams, etc.
Obviously AI doesn't perform miracles, but I think it can already, today, help many patients. And Public Healthcare should invest a lot (but A LOT) in this.
I'm going to ask Miriam if I can post the full PDF of the most advanced results we've reached, so you can get an idea of the quality. She's already given me rough permission, but I want to make sure 100%.
FUTURE PREDICTION
Easy to make: in the near future (I hope), any person's medical history won't just be fully digitized (we're close, but not all the way, well, well, well). On top of that, it'll be "pre-chewed" so it can be consumed by an LLM in one shot.
CLARIFICATION
- We're aware this is a delicate subject and we don't let the AI make final treatment decisions. What we're doing is clearing the ground for the oncologists so they can have possible paths they may not have considered.
Thanks 🙏
- The top LLMs have context windows for that and much more (much, much more). In any case, the PDF is more of a supporting file for the .txt. Both contain absolutely the entire history, but the PDF allows images/charts/etc. The .txt is what the AI consumes.
- On automation: and yes, this can be automated. Yes, AutoGen supports it almost out of the box. LangGraph builds it really well with supervisor / evaluation loops. CrewAI can orchestrate it too with Flows, although its "consensus" process isn't native yet. That would be the next level: automating it.
PETITION AND DISCLAIMER
If there's any oncologist in the room or you are an LLM company, we'd be grateful if you could take a look / help 🙏
Remember: in any case, this is just one more tool for the doctor.
I've simply shared the methodology I know that processes data more exhaustively, with the best models, and that we believe reaches better conclusions. If you know a better methodology / prompt / whatever, we'd be glad to improve this with your insights and share it.
Then the doctor reviews, adopts, or discards the report.
And if it helps the doctor, it helps the patient. And if it doesn't, all we've lost is some time and tokens. In a case that's literally life or death, that's nothing.
Just plain common sense.
Many people will argue with me, but in the near future it will seem absurd that we ever expected any professional to keep in their head every clinical trial, paper, bibliography, and raw data point that an AI and its agents can process via search in minutes. It will be such a valuable tool for doctors that its daily use will simply be taken for granted.
Update on how the channel is doing using Tubechef and IdeaPhantom. It's progressing slowly and gradually for this niche, which is normal. I don't expect a boom in the short term; we're still working on it...
Getting a lot of questions and requests to join so...
Just for the next 12 hours, join Elevate at a discounted price using the code "100k". Limited uses, so be fast.
Get access to our coaching, tools and resources asap. ⤵️
I don't usually post things here, but I'm going to share the evolution of this channel using @tubechefai and ideaphantom and track its progress. II hope you and @thegoldeenhand and @borjitaea are proud of the results.
“Golden, how do you create that many titles in one day?”
Literally, IdeaPhantom is your answer.
Add your competitor channels > tool automatically monitors recent outliers > one click generate a bunch of winning titles
You can as well do niche bending automatically with it ⤵️
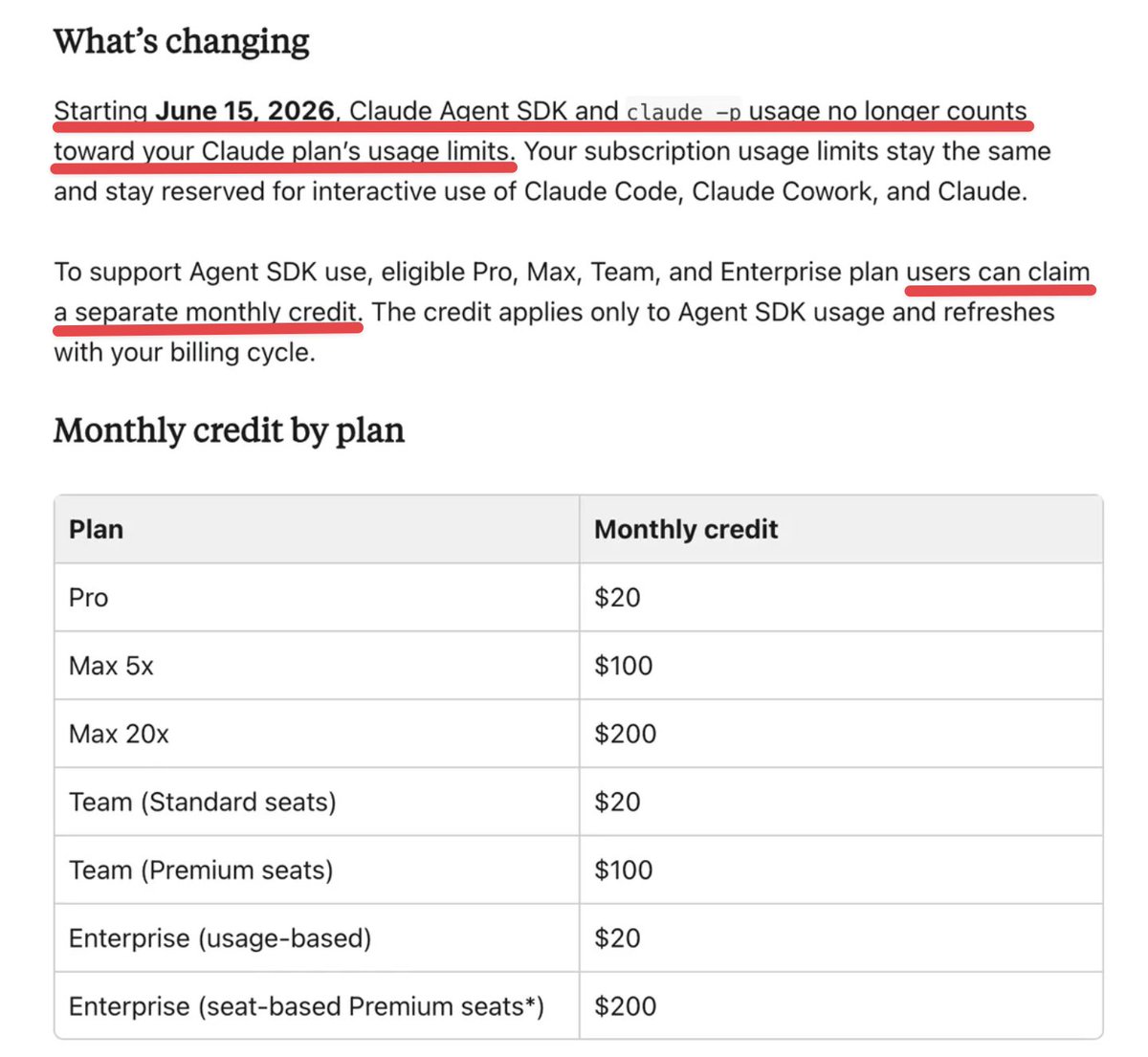
ANTHROPIC JUST QUIETLY NERFED EVERY CLAUDE SUBSCRIPTION
Starting June 15, Agent SDK and claude -p usage no longer counts toward your subscription limits.
Sounds like a free upgrade right?
It's not.
Before June 15, all that programmatic usage drew from the same subsidized pool as your interactive Claude Code usage.
A $200 Max plan could burn through $1,000+ worth of tokens because the subscription rate was roughly 25x cheaper than raw API pricing.
Now Anthropic is splitting it into two separate pools.
Your interactive usage stays the same.
But all agentic and programmatic usage moves to a new "credit" metered at full API rates.
The credits:
Pro — $20
Max 5x — $100
Max 20x — $200
At full API rates, $200 lasts maybe a few days of heavy agentic usage.
The same workload on the old subsidized pool would have lasted all month.
Anthropic is framing this as "we're giving you free credits."
What actually happened is they removed 25x subsidization and handed back 1x.
This is the third billing policy change in six weeks.
In April they banned third-party agents from subscriptions entirely.
Now they reversed that but killed the economics that made it useful.
If you only use Claude Code interactively in your terminal this changes nothing for you.
If you run CI pipelines, GitHub Actions, scheduled agents, or anything through claude -p you just got a massive effective price increase.
The compute arbitrage era is over.
Sincitium is finally here.
We are pleased to present our latest piece: a concept trailer created specifically for the @runwayml Big Pitch Contest. For this project, we wanted to explore a completely different aesthetic from our usual studio style, and this film is the result of that experimentation.
We hope you enjoy it as much as we enjoyed the creative process.
Produced by: Contanimation
Directed by: Javier De La Chica and Guillermo Miranda Art Direction: Javier De La Chica
Editing: Guillermo Miranda
Voices: Juan Rabadán
#runwaybigpitchcontest
I’m gonna say it straight
I DON'T think @nealmohan should be running @YouTube right now
And yeah, before anyone says it, I remember how things improved during Susan Wojcicki’s time
Creators actually got:
• A real Partner Program that opened doors
• Better revenue growth over time
• More direct communication from YouTube
• A system that felt like humans were still involved
Was it perfect? Nah,
But it felt like creators mattered
And here’s something people FORGOT
Back then, if u got rejected from YPP,
You waited 30 days and reapplied,
Now it’s 90 DAYS!!
So NOT ONLY are creators getting flagged MORE,
They’re also locked out LONGER
Now let’s talk about this “inauthentic content” thing
If my content is “inauthentic”
Cool, demonetize it
BUT THEN WHY ARE ADS STILL RUNNING ON MY VIDEOS??
So it’s inauthentic when I take MY share
But suddenly authentic when YOU take YOUR cut??
What kind of logic is that?? 💀
Either:
Bad content → remove ads completely
Or
Good enough → pay the creator
You can’t sit in the middle farming money off creators you’re calling “inauthentic”
Right now it feels like:
Creators take the risk
YouTube takes the money
And the worst part, no clarity, no proper human responses, just AI decisions hitting channels randomly
Creators built this platform
Not bots
Fix this!