Over the past month, the DBOS product team has focused heavily on two areas: workflow operations tooling and performance optimization.
What's new:
- Major performance improvements
- Database-backed dynamic queue configuration
- Timeline visualization for workflows and steps
- Spring Boot integration
… and more!
Would love to hear your thoughts, especially from folks running workflows in production.
Join us at this month's @DBOS_Inc User Group! We're focusing on workflow observability:
- Workflow Observability Redesigned: @poliakov_dbos will showcase major upgrades to DBOS Conductor UI. You can now visualize workflow execution timelines, navigate workflows with thousands of steps, and use multi-faceted filtering capabilities to quickly find workflows of interest.
- OpenMetrics Integration: @petereliaskraft will introduce our new OpenMetrics support and demonstrate how to export workflow metrics to Datadog and other observability platforms for monitoring, dashboards, and alerting.
If you're building long-running or complex workflows, these updates make it much easier to understand performance, debug issues, and keep your systems running reliably.
Registration link below.
Cool new feature: you can now perform bulk workflow actions from the console.
You can filter and select many workflows, then cancel, resume, or delete them. This is really useful when responding to unexpected events (for example, cancelling and resuming workflows to apply a bug fix), letting you manage all your workflows without leaving the console.
We just released DBOS Transact for Go v0.16.0
This release adds support for SQLite as a durability backend, making it even easier to build durable workflows and background jobs without provisioning a database. SQLite is a great fit for local development, edge deployments, and lightweight applications that still need reliable recovery from failures.
Release notes: https://t.co/Ws7x1dchhr
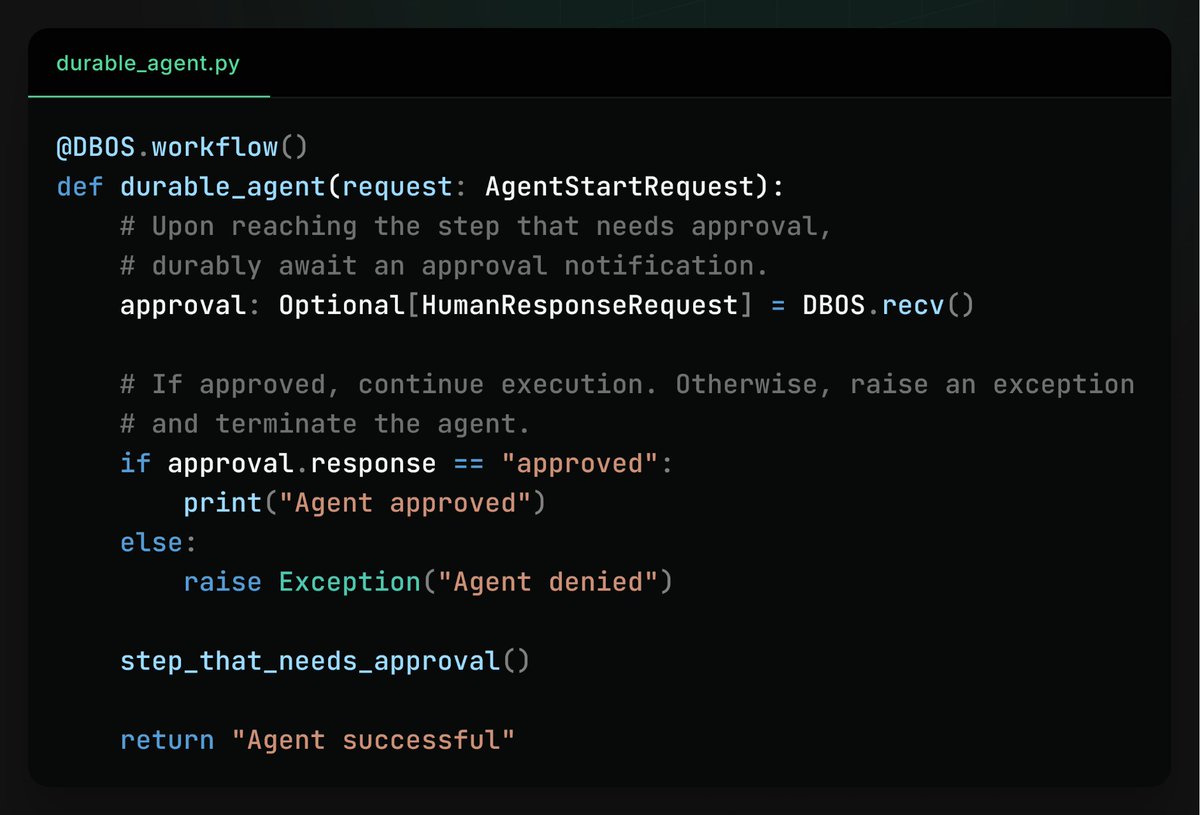
A surprisingly hard challenge building AI agents is putting a human in the loop.
If you want your agent to be able to perform critical tasks in production, it probably needs to wait for human approval. However, because there are real people involved, approval doesn't always happen instantly, and agents need to be able to wait hours or days for human intervention, then quickly resume when it arrives.
This creates a new reliability problem for agents, as they’re now running for hours or days instead of seconds or minutes. As they’re running for longer, it’s much more likely they’re interrupted (server maintenance, code upgrade, process crash) while waiting. For agents to really be usable in production, they need to be able to automatically recover from these interruptions and resume from where they left off.
Durable workflows can help make long-running, human-in-the-loop agents resilient to failure. The idea is to checkpoint an agent’s progress in a database so that if the agent is interrupted, it can recover and resume from its last checkpoint.
To handle human-in-the-loop specifically, we can use a database-backed messaging system where an agent awaits a notification delivered through the database. When the agent first starts waiting, it checkpoints a timeout. If the agent is interrupted, it recovers from its checkpoints and continues waiting towards the timeout. When a human approves the agent, the approval message is written to a database table so that when the agent is ready and recovered, it can read the message and continue execution. That way, an agent can run for days waiting for human approval and be ready to go as soon as it arrives.
💬 Hello, Agent: How do you make AI agents fail-safe?
Learn the answer in Episode 3 of our "Hello, Agent!" podcast with the super savvy @jedberg, C-Suite Advisor at @DBOS_Inc.
In this ep, Jeremy explains how durable execution solves reliability issues, its role in building production-ready AI agents, and shares insights from his time at Netflix and Reddit on enterprise-scale reliability engineering.
Tune in 🎧
https://t.co/NAFPupC5cx
One unique benefit of DBOS is that it allows you to update your database record and start a background task in the same transaction.
This guarantees both atomicity and durability in one place, without needing extra coordination between your application and external queueing/messaging system.
One important pattern for building reliable systems is a transactional outbox.
It solves an important problem: how to reliably update a database record and send a message to another system. This is trickier than it sounds because the operations usually need to be atomic: they either both happen or neither do, even if there are failures (such as process crashes or network glitches) while performing them. Otherwise, the database might go out of sync with other systems, which could cause serious data integrity issues.
Typically, to implement an outbox, we add a new “outbox” table to our database. When we need to perform an atomic update, we run a single database transaction that both:
- Updates the database record
- Writes the message we want to send to the "outbox" table.
A separate background process then polls the outbox table and sends the messages there to the other system.
Performing the database record update and writing the message to the "outbox" table in one transaction guarantees atomicity: either both records are updated and neither are, and once the message is written to the outbox, it will asynchronously be consumed and sent by the background process even if failures occur later.
Durable workflows make a transactional outbox pattern easier in one of two ways.
First, instead of using an outbox at all, you can both perform the transaction and send the message in a workflow. The workflow guarantees atomicity: if a failure occurs after writing to the database but before sending the message to the external system, the workflow will recover from its last completed step (writing to the database) and retry the next step (sending the message) until the message is successfully sent. This is the same guarantee a conventional transactional outbox provides: assuming the message is eventually delivered after enough retries, either both operations occur or neither do.
Alternatively, instead of sending a message, you can enqueue a workflow in the same transaction as your database operation (because workflows are backed by database tables). Then, the workflow can perform whatever operation you want to happen atomically with your database update. All these patterns provide the same guarantees, but using workflows can be simpler in practice.
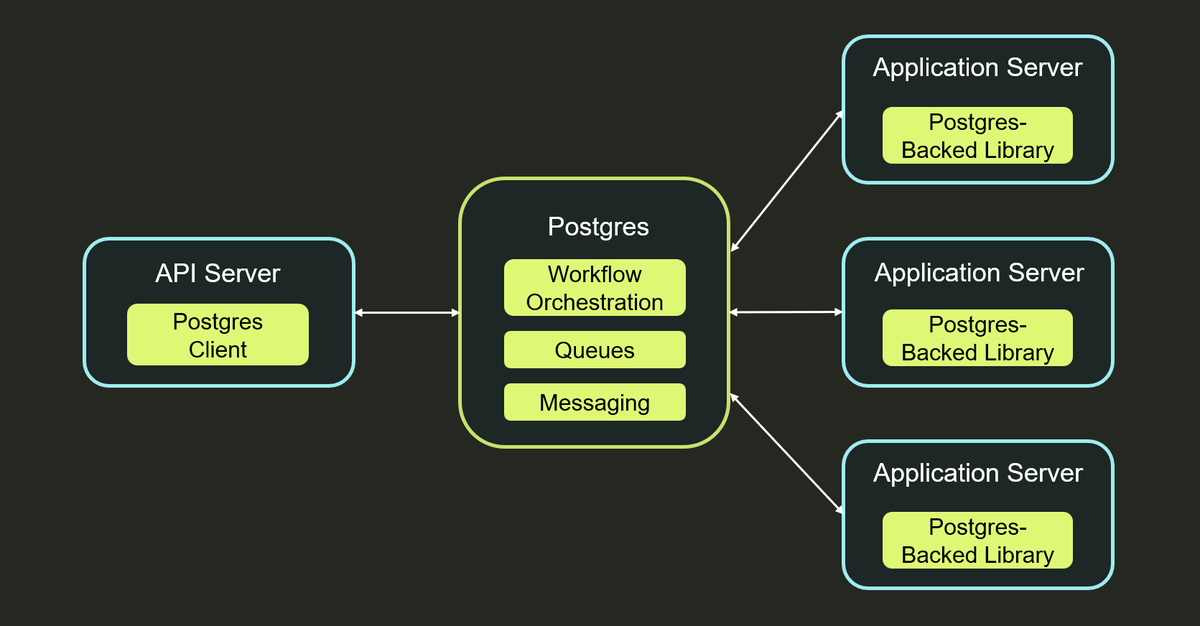
Postgres is all you need for durable execution.
I wrote a blog post about the big idea we’ve been working on for the past couple years.
Durable execution is a powerful tool for building reliable software, and the core idea is simple: checkpoint the progress of your programs in a database so that if anything fails, you can recover them from their last completed steps.
So what do you need to make durable execution work? It turns out, not much: a database and a library that connects to it. And if you build your durable execution on Postgres, you get access to its rich ecosystem: built-in tooling for scalability, observability, availability, and any other operational need.
I wrote about how this idea works and how we’re implementing it at DBOS:
👇
Over the past month, the DBOS product team has focused heavily on two areas: workflow operations tooling and performance optimization.
What's new:
- Major performance improvements
- Database-backed dynamic queue configuration
- Timeline visualization for workflows and steps
- Spring Boot integration
… and more!
Would love to hear your thoughts, especially from folks running workflows in production.
Memory Store (@memorydotstore) gives your team and AI agents a shared company brain.
Your team's knowledge & decisions are scattered across slack, emails, and people's heads. Memory Store turns them into a living wiki for your agents and teammates.
Congrats on the launch, @ishitajindal17 & @diwanksingh!
https://t.co/xWrsKiVGrP
Cool new-ish feature: transactional steps!
If you have a step that does database operations, putting it in a transactional step guarantees it runs exactly-once by writing its step checkpoint in the same transaction as the step itself. This is the kind of powerful thing you can do if you build durable execution with a database.
Our latest release makes transactional steps much easier to use: you can create a “datasource” for any database on which you want to run transactional steps and access it from any of your workflows. It doesn’t have to be the same database you use for your workflows.
Also, datasources natively support both sync and async Python.
We just released the much-requested Google ADK + @DBOS_Inc integration: durable execution for ADK agents, backed directly by your database.
The DBOS plugin brings production-grade reliability and orchestration to ADK agents:
- Durable execution: Automatically recover agents from crashes, deploys, or machine failures without losing progress.
- Built-in retries: Configure retry policies with exponential backoff for transient LLM or tool failures.
- Long-running agents: Run agents and tools for hours or even days.
- Human-in-the-loop workflows: Pause execution and resume later after human approvals.
- Scalable execution: Run workflows across distributed workers with durable queues and built-in rate limiting.
- Observability & management: Inspect, cancel, resume, and fork agent workflows for debugging and operations.
All powered by a database you own, no separate orchestration infrastructure required.
Docs and repo below ⬇️
If you’re building an open-source library today, your users are just as much AI coding agents as human developers.
That means it’s important to design software, and especially its documentation, in a way AI tools can understand. How do you do that?
The answers are constantly evolving, but the solutions that in my experience work the best right now are:
- Well-structured, clear, concise docs (this hasn’t changed)
- Agent skills indexing your docs in an easily digestible format
- MCP to let agents use your APIs directly
I wrote this blog post going into more detail on what works for us and what doesn’t:
👇
Our next South Bay Systems meetup is on May 26! This time, we're covering one of my favorite topics: databases, and how to use them to make better architectural decisions and build reliable systems.
We have two great talks lined up:
- "Building a Distributed Persistent Queue on FoundationDB": @HimankChaudhary will walk through how the queuing infrastructure at @TigrisData was designed and implemented.
- "Decisions, Principles, and Lessons from a Year of Teaching MySQL New Tricks": Steve Schirripa will share lessons and challenges around extending relational database systems at @VillageSQL.
Food and drinks will be provided courtesy of our hosts at @PingCAP. Registration link below.