A study led by ecologists in the UMN College of Biological Sciences and recently published in @Nature, reveals that long-term records of an ecosystem’s natural ups and downs can be used to forecast how strongly it will resist a future climate extreme. https://t.co/JKhAdoso6o
@JTLonsdale Generally agree, but one nit: biotech includes a lot more than just pharma. Our lunch is still being eaten by China, but the problem is not limited to pharma. Industrial biotech suffers the same and has nothing to do with drug development or clinical trials. Don't sleep on it.
Binder design has come of age thanks to generative models—but how can we access the wider array of dynamic, multistate protein functions, so elegantly employed by nature?
@mihirbafna14 and I are excited to share SwitchCraft, a framework for designing such functions. (1/7)
Stein Variational Gradient Descent (SVGD) is a particle-based approach to variational inference.
SVGD iteratively transports a set of particles to match a target distribution by applying a form of functional gradient descent that minimizes the KL divergence.
AI for structural biology: given the right harness, tools, and compute, your preferred AI agent can tackle tasks such as building a protein structure from a cryo-EM density map.
In this case, Claude assembled a structure, compared its reconstruction to the published structure, then used ChimeraX to create these visuals and make this short presentation video.
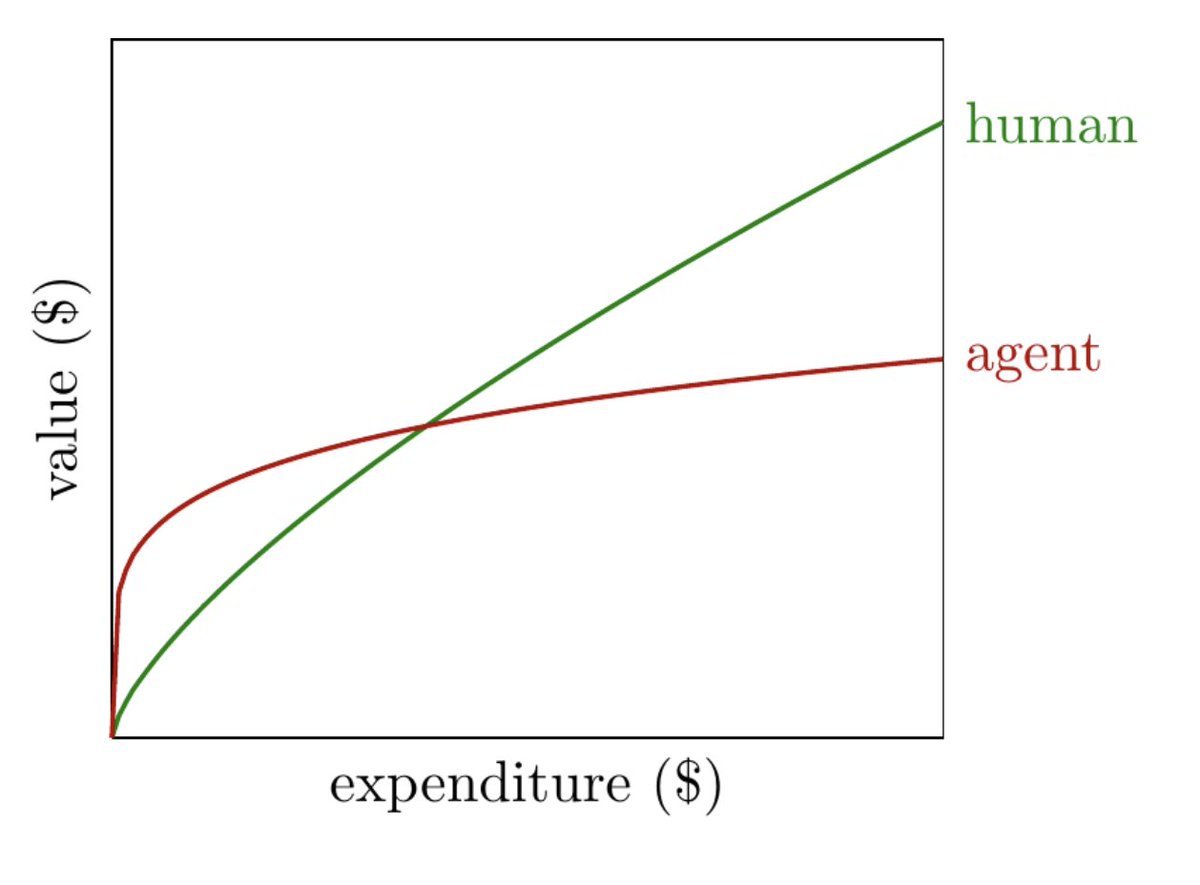
I think most domains look like this at the moment: the returns to expenditure on agents diminish much more quickly than the returns to expenditure on human labor: (1/n)
A reminder that impactful #genomics doesn't always require expensive infrastructure.
For this new preprint by @DavidHamelin7 et al, we developed a long-read HLA profiling workflow costing ~US$20 (~A$30) per sample using an @Opentrons OT-2 robot, enabling high-resolution profiling across 500+ participants.
The science: Using AI to understand how HLA diversity influences susceptibility to immune escape.
The bigger picture: personalised MHC modelling is becoming a key foundation for next-generation immunotherapies and #PrecisionMedicine
https://t.co/4uDEKJTBZh
Very excited to share that our preprint on synthetic bacterial sponge RNAs is now out. This paper is for you if you’re interested in RNA synthetic biology, quantitative gene circuit characterisation, resource competition, or post-transcriptional regulation. (1/11)
The Reconfigurable Automation Cart (RAC) is the fundamental unit of the autonomous lab. Dan Curhan, a Senior Mechatronics Engineer at Ginkgo, walks you through how these robots leverage 5-micron repeatability, factory-calibrated trajectories, and built-in redundancy to ensure maximum uptime for a lab's worth of scientists.
See Nebula, our autonomous lab in Boston, by booking a tour: https://t.co/uBD8z5Fbu3
With a nod to @leopoldasch, we're releasing Biological Awareness - our musings on the next decade at the frontiers of AI and life sciences.
Six ideas we explore:
→ Task-specific experimental tokens are the new gold in biology
→ Bio AI data factories will pioneer new business models
→ Smoothing out the jagged frontier for pharma enterprises is where fortunes will be made
→ Clinical trial intelligence will be financialized before it is operationalized
→ The bioweapons threat is real, accelerating, and underpriced
→ The BIOSECURE Act will fundamentally reshape supply chains
2026 marks ten years of Obvious investing at this intersection. A lot has happened. Even more is coming.
Big thanks to: @kyosu, @syntenyAI, @GabriCorso, @inductivebio, @mithrl_ai , @instancebio , @strangemonad, @exnx and many others for their help!
New book chapter: "How to Weigh a Cell."
This chapter explains how scientists have weighed cells throughout history, often using simple equipment and back-of-the-envelope calculations.
It has lots of interactives, so you can "repeat" the experiments directly in your browser.
Biohub’s new AI “world model” for proteins makes companies like @Quantum_Si even more important. $QSI @Nasdaq
AI can now predict and design proteins at massive scale — but biology still needs real-world experimental truth. Quantum-Si generates actual protein sequencing data to validate, refine, and train these models.
In the AI biology era, the winners will be the companies generating the highest-quality experimental protein data.
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini 🚀
Today, we’re sharing the @GoogleDeepMind white paper for GE 2, our first native multimodal embedding model. Whether it’s text, audio, video, or image, GE 2 provides a unified representation of the input.
Figuring out how to benchmark agents on realistic biology research has quickly become one of my favorite types of engineering work. You work with scientists to get to the core of some biological claim, precisely assembling raw data/prior literature/experimental context in a little 'world' for an agent to stumble around in - only for its behavior to challenge what you thought to be true and to force you to deeply introspect empirical human behavior. Doing this well gets considerably more difficult as we better approximate and climb long horizon scientific work: the type one might publish in the results section of a paper or build a drug program around. Been working on a project in this direction for the past few months and excited to drop tomorrow.
Today we're announcing ESMFold2, an open scientific engine to power prediction, design, and discovery across protein biology.
The new model delivers state of the art performance on protein interactions, especially antibodies, a critical modality for therapeutics.
We have designed and validated miniprotein binders and single chain antibodies across five therapeutic targets that are important in cancer and immunology. We are seeing very high success rates, and affinities at levels consistent with therapeutic activity.
We’re also releasing an atlas of 6.8 billion proteins, and 1.1 billion predicted structures.
ESMFold2 is built on a state of the art language model that has been trained on billions of protein sequences.
A world model of protein biology emerges through language modeling.
We’ve used the techniques of mechanistic interpretability developed to understand large language models to understand the concepts ESM uses to represent proteins.
The model’s representation space has a compositional organization of features across scales, levels of complexity, and abstraction, that reflects and mirrors the understanding of protein biology developed through a century of empirical science.
This understanding emerges without prior knowledge, just from language modeling of protein sequences.
Language models are becoming a powerful substrate to understand and program biology.
The design of protein interactions is one of the most fundamental problems in biophysics, and has critical implications for the discovery of new medicines. A simple gradient based search with the model was able to discover high-affinity protein binders.
I'm excited by the potential this has to accelerate basic science and the understanding of proteins. And especially for the new avenues it opens up for therapeutic design and medicine.
New Blog: What's the point of theory in biology, especially in the age of machine learning?
I just published a series of letters by @NoahOlsman that start to get at this question, especially in the context of virtual cells: https://t.co/tcJLPgPs94
"If you're not failing, you're not pushing boundaries."
Hear medicine laureate Elizabeth Blackburn speak about the valuable lessons we can learn from failure.