🚨 New paper: Data-driven Circuit Discovery for Interpretability of Language Models 🚨
Do circuits actually explain how language models (LM) implement a task?
In mechanistic interpretability, the goal of circuit study is to discover a “circuit” that is responsible for implementing a “task”.
But we find that existing methods often discover circuits that are:
❌ not general task circuits: they do not capture the full range of mechanisms LMs uses across the task.
Instead, they find:
✅ dataset-specific circuits: they explain how the model processes the examples used for circuit discovery.
✅ mixed-mechanism circuits: consisting of multiple independent mechanisms mixed in a single circuit.
1/🧵
3/ On the noise point: fully agree that single-instance gradients are noisy, and your paper seems to explore this much more in depth. Our work has a different focus: existing circuit studies often claim to have discovered “the mechanism” for a task, but the discovered circuit does not always generalize to all instances of that task. We find there may not be a single coherent circuit that generalizes across all instances. DCD’s goal is to address this by finding mechanism-specific circuits instead — circuits whose scope is a coherent group of examples, rather than an entire human-defined task.
Happy to discuss further :)
🚨 New paper: Data-driven Circuit Discovery for Interpretability of Language Models 🚨
Do circuits actually explain how language models (LM) implement a task?
In mechanistic interpretability, the goal of circuit study is to discover a “circuit” that is responsible for implementing a “task”.
But we find that existing methods often discover circuits that are:
❌ not general task circuits: they do not capture the full range of mechanisms LMs uses across the task.
Instead, they find:
✅ dataset-specific circuits: they explain how the model processes the examples used for circuit discovery.
✅ mixed-mechanism circuits: consisting of multiple independent mechanisms mixed in a single circuit.
1/🧵
2/ On CMD′ and NDF: I totally agree they look similar, since both metrics are derived from the CMD metric proposed in the MIB paper. We also found it unnecessary to penalize the faithfulness score when the circuit performs better than the full model. One small difference is that, unlike NDF, we do not clip under-recovery.
2/ In different ways, both works move away from defining circuit as a mechanism for a task. Wu et al. go to the query or prompt level. Our work instead groups examples by computational similarity (via per-example EAP-IG attribution) and finds one circuit per group — scope is the group of examples, not a prompt or a task. These group-level circuits come out more faithful than the task-level circuit on the same data. Also, the scope of what these circuit explain is not the full scope of the task but only its own group.
Overall: different scope, motivation, and method — but both works point at the current circuit practice having unresolved questions about what a circuit explains and at what scope.
Thanks for sharing the paper - it's definitely related, and we'll include it in future updates of the paper. A few thoughts on similarities and differences:
1/ Different motivations: Wu et al. aim to find a local explanation: a circuit for one specific input. DCD aims for a global explanation of a set of examples sharing a mechanism.
Both works flag limitations of current circuit discovery, but different ones. Wu et al. observe per-query circuits are less faithful than task-level capability circuits with current methods. We observe the task-level circuit may not exist as a single coherent object; current methods assume (i) one human-defined task = one circuit, (ii) the dataset adequately proxies the task, and our experiments suggest both can fail. As a result, current methods can find circuits that silently mix multiple independent mechanisms.
Trying to find circuits in language models?
Bad news is that existing methods DO NOT give you what you think...
Check out new work with @DakingRai@ZiyuYao where we show fundamental limitations of existing approaches and propose a new data-driven framework for circuit discovery
Thanks, really enjoyed your paper.
Besides our new paper, we also made a similar observation in our NeurIPS'25 paper (https://t.co/R4hsYwt0SS) for the code-syntax related task as well. Although the study didn't involve a full circuit study, it strongly suggested the existence of multiple mechanisms with varying levels of accuracy in the model for a single task.
In our new paper (https://t.co/VYuYOytY3w), we also make similar observations to the paper in parallel --- that 𝐋𝐌𝐬 𝐮𝐬𝐞 𝐦𝐮𝐥𝐭𝐢𝐩𝐥𝐞 𝐝𝐢𝐬𝐭𝐢𝐧𝐜𝐭 𝐜𝐢𝐫𝐜𝐮𝐢𝐭𝐬 𝐟𝐨𝐫 𝐢𝐦𝐩𝐥𝐞𝐦𝐞𝐧𝐭𝐢𝐧𝐠 𝐭𝐚𝐬𝐤.
We find that the existing circuit discovery methods do not discover:
❌ General task circuits: they do not capture the full range of mechanisms LMs uses across the task.
Instead, they find:
✅dataset-specific circuits: they explain how the model processes the examples used for circuit discovery.
✅ mixed-mechanism circuits: consisting of multiple independent mechanisms mixed in a single circuit.
🧵 More in our paper thread: https://t.co/6eSrttZDg1
Does mechanistic interpretability really find the circuit?
Our new paper, "All Circuits Lead to Rome: Rethinking Functional Anisotropy in Circuit and Sheaf Discovery for LLMs," (Accepted by ICML 2026) suggests the answer may be: not always.
A common implicit assumption in mechanistic interpretability is that a model's behavior is explained by the circuit — a sparse, canonical, almost-unique mechanism.
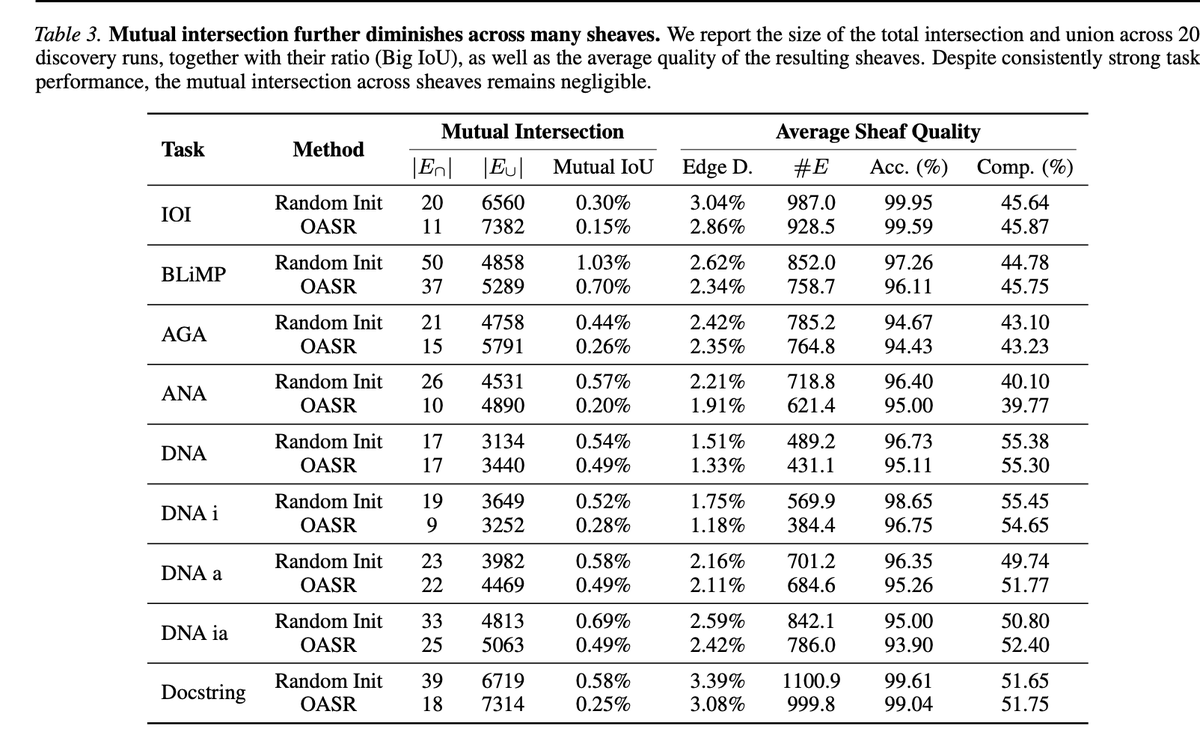
Instead, for the same LLM task, we find multiple circuits/sheaves that are:
✅ faithful
✅ sparse
✅ structurally different
✅ low-overlap
This means a discovered circuit may not be the unique mechanism behind a behavior, but one realization among many possible mechanisms. We call for rethinking how circuit/sheaf discovery results should be interpreted and evaluated.
Huge thanks to my amazing collaborators: @frankniujc, @YutongYin774638, and @zhaoran_wang
Paper: https://t.co/J5zO36Mr7m
#MechanisticInterpretability #LLM #AI #MachineLearning
8/8 Paper: https://t.co/wEQi9OlvYC
Grateful to my amazing collaborators: @ZiyuYao , @megamor2 !
We'd love to hear your thoughts — feedback and comments welcome!
7/8 Our experimental results show that:
1. DCD recovers more faithful and sparser circuits on mixed-task datasets than standard hypothesis-driven methods.
2. It also produces circuits with clearer specialization: different circuits explain different subsets of examples.
The broader takeaway:
1. Human task labels do not always match how language models organize computation internally.
2. To understand models mechanistically, we should let the model’s internal structure help define the scope of explanation.
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵