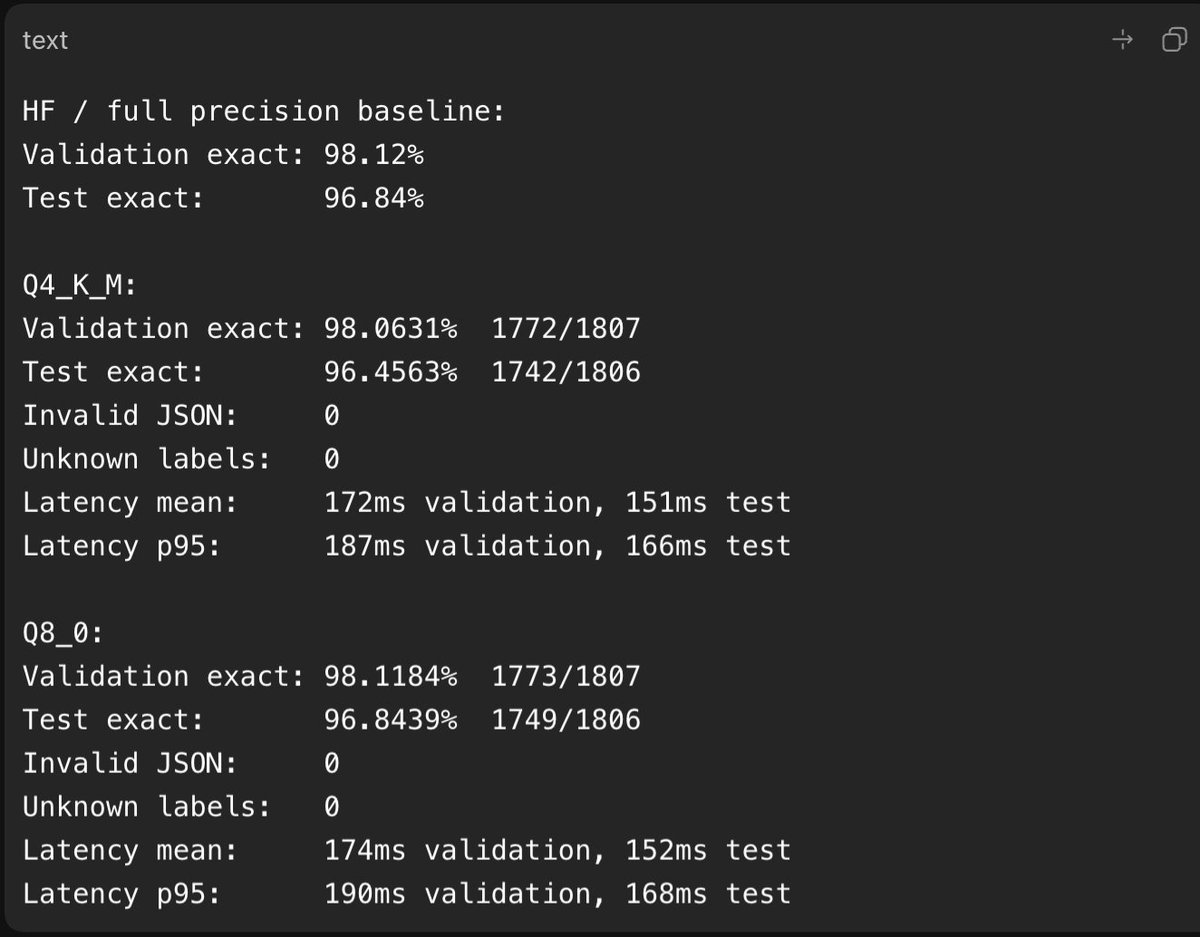
🖥️ Best Local LLMs for Consumer GPUs — llama.cpp Guide (June 2026)
What I actually run on consumer hardware right now. Every model below runs via llama.cpp with a simple one-liner — no Docker, no Python env, no cloud.
━━━ 8-16GB VRAM ━━━
🔹 Gemma 4-12B (Google)
• Smartest model in this size class — competes with stuff 2× bigger
• Unsloth's MTP GGUFs: 162 tok/s vs 52 tok/s normal (3× speedup)
• Minimum 8GB VRAM recommended for Q4_K_M quant
• GGUF → https://t.co/VWp818MB3D
🔹 LFM2.5-8B-A1B (LiquidAI)
• Hybrid MoE, only 1B active params — absurdly fast for its size
• Perfect for 8-12GB cards, MacBooks, or anyone on a tight budget
• GGUF → https://t.co/ZbOs4mXJDq
━━━ 16-32GB VRAM ━━━
🔹 Qwen3.6-27B (Qwen)
• Scored 1.00 on tool-efficiency benchmarks — best local agent available
• 40 deterministic tasks, 32k/128k context needle tests — all passed
• GGUF → https://t.co/n7K3sPvliE
• MTP version (faster) → https://t.co/gwdfnJTzcy
🔹 Qwopus3.6-27B-v2 (Jackrong)
• Best quantization of Qwen3.6-27B — topped 5 agent & coding benchmarks (1200 samples)
• If you're running Q4, this is the one to grab
• GGUF → https://t.co/tV1DFqXnOD
• MTP version → https://t.co/PMqz7V5ewv
🔹 Gemma 4-31B QAT (Google/Unsloth)
• QAT variant with MTP draft head: 76-125 tok/s (1.67× speedup)
• Excellent for multi-agent / subagent workflows
• GGUF → https://t.co/FgVsUX0YOB
🔹 Nex-N2-Mini (Nex AGI)
• Post-train of Qwen3.5-35B-A3B — MoE with only 3B active params
• Fits on 16GB+ VRAM, overflow loads from system RAM
• Adaptive thinking saves ~20% tokens with no quality loss
• For deep multi-step reasoning, nothing in this size comes close
• GGUF → https://t.co/oyC522a8Eh
━━━ Quick Picks ━━━
• 16GB all-rounder → Gemma 4-12B with MTP GGUFs
• 32GB all-rounder → Qwen3.6-27B / Qwopus-v2
• Agents & tool use → Qwen3.6-27B or Qwopus Q4
• Deep reasoning → Nex-N2-Mini (MoE, fits 16GB+)
• Tight budget → LFM2.5-8B-A1B
• Cheapest full build: 1× used RTX 3090 (24GB) + rest of PC ≈ $1000-1500
━━━ Setup on Windows ━━━
1. Download llama.cpp → https://t.co/et0J7Swua7 (latest .zip)
2. Extract to any folder (e.g. C:\llama.cpp)
3. Download a .gguf from the links above (Q4_K_M or Q5_K_M for best quality/speed balance)
4. Run one of the commands below depending on your hardware
━━━ Launch Commands ━━━
SINGLE GPU — Standard model (no MTP):
llama-server.exe ^
-m C:\models\Qwen3.6-27B-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
-ngl 100 ^
-np 1 ^
--port 8080 ^
--jinja
SINGLE GPU — MTP model (faster inference):
llama-server.exe ^
-m C:\models\Qwen3.6-27B-MTP-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
--spec-type draft-mtp ^
--spec-draft-n-max 3 ^
-ngl 100 ^
-np 1 ^
--port 8080 ^
--jinja
DUAL GPU — Split across two cards:
llama-server.exe ^
-m C:\models\Qwen3.6-27B-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
-ngl 100 ^
--tensor-split 0.55,0.45 ^
--main-gpu 0 ^
-np 1 ^
--port 8080 ^
--jinja
DUAL GPU + MTP + Vision (multimodal):
llama-server.exe ^
-m C:\models\Qwen3.6-27B-MTP-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
--spec-type draft-mtp ^
--spec-draft-n-max 3 ^
-ngl 100 ^
--tensor-split 0.60,0.40 ^
--main-gpu 0 ^
-np 1 ^
--port 8080 ^
--jinja ^
--mmproj C:\models\mmproj-F16.gguf
━━━ Parameter Breakdown ━━━
-m <path>
Path to your .gguf model file. Change this to wherever you downloaded it.
--ctx-size 180000
Context window in tokens. 180k = huge context for long conversations or big codebases.
Reduce to 32768 or 65536 if you don't need long context — uses less VRAM.
--flash-attn on
Flash Attention — dramatically speeds up inference and reduces VRAM usage.
Works on RTX 30xx/40xx/50xx. Always enable this.
--cache-type-k q4_0 / --cache-type-v q4_0
Quantizes the KV cache (key/value attention cache) to 4-bit.
This is what makes 180k context fit in VRAM. Without it, huge contexts eat all your memory.
Quality impact is minimal — this is a free performance win.
--batch-size 1024 / --ubatch-size 512
batch-size = how many tokens are processed in one forward pass (throughput).
ubatch-size = micro-batch actually sent to the GPU per step.
Higher = faster prompt processing but needs more VRAM.
If you run out of VRAM, lower these (e.g. 512/256).
-ngl 100
Number of layers to offload to GPU. 100 = all layers on GPU (full offload).
This is what you want if the model fits in your VRAM.
If it doesn't fit, reduce this (e.g. -ngl 40) — remaining layers run on CPU/RAM.
--tensor-split 0.55,0.45
How to split model layers across multiple GPUs. Values are ratios.
0.55,0.45 = GPU 0 gets 55% of layers, GPU 1 gets 45%.
Adjust based on your VRAM — give more to the card with more memory.
Example: 0.70,0.30 for a 24GB + 12GB setup.
Not needed for single GPU setups.
--main-gpu 0
Which GPU handles the batch computation (the "orchestrator").
Set to 0 (your primary GPU). The other GPU(s) handle their assigned layers.
Minor performance impact — usually just leave it at 0.
-np 1
Number of parallel slots (concurrent requests). 1 = one user at a time.
Increase to 2-4 if you want multiple clients connected simultaneously.
Each extra slot uses additional VRAM for its own KV cache.
--port 8080
Which port the server listens on. Change if port 8080 is busy.
--jinja
Enables Jinja2 template processing — required for proper chat formatting.
Most modern models expect this. Always include it.
--spec-type draft-mtp
Enables Multi-Token Prediction (MTP) speculative decoding.
Only works with MTP GGUF models (downloaded separately).
The model predicts multiple tokens at once and verifies them — big speed boost.
--spec-draft-n-max 3
How many tokens the MTP draft head proposes per step.
3 is a good default. Higher = potentially faster but more VRAM and may reduce quality.
--mmproj <path>
Path to the multimodal projector file (for vision models).
Enables image understanding — paste screenshots into the web chat.
Only needed if you want vision capabilities. Omit for text-only use.
━━━ Your Hardware → Your Command ━━━
Single GPU (8-24GB VRAM):
Use the "Single GPU" command. Change -m to your model path.
8GB card → Gemma 4-12B Q4 or LFM2.5-8B
12GB card → Gemma 4-12B Q5/Q6
16GB card → Gemma 4-31B QAT Q4 or Nex-N2-Mini
24GB card → Qwen3.6-27B Q4/Q5, Qwopus-v2, Gemma 4-31B QAT Q5/Q6
Dual GPU:
Use the "Dual GPU" command. Adjust --tensor-split based on your VRAM ratio.
24GB + 24GB → --tensor-split 0.50,0.50
24GB + 12GB → --tensor-split 0.70,0.30
24GB + 8GB → --tensor-split 0.75,0.25
Want speed? Use MTP versions of models with the "MTP" commands.
Want vision? Add --mmproj with the projector file from the model's HuggingFace repo.
5. Once running, you get:
• Web chat UI → http://localhost:8080
• OpenAI-compatible API → http://localhost:8080/v1
• Playground → http://localhost:8080/playground
━━━ Why /v1 API Is the Killer Feature ━━━
One local endpoint replaces your entire cloud API bill. The /v1 endpoint is drop-in OpenAI-spec compatible — every tool that speaks OpenAI just works. No custom code, no glue layer.
Works out of the box with:
• IDEs: Cursor, Continue, Windsurf, Cline, Roo Code
• CLI tools: aider, Open Interpreter, OpenCode
• Frameworks: LangChain, LlamaIndex, LiteLLM
• Any OpenAI SDK (Python, Node, Go, Rust)
Why this beats cloud APIs:
• 100% private — code never leaves your machine
• $0 per token — no rate limits, no quotas, no surprise bills
• Works fully offline
• Zero telemetry, no training on your data
• Swap models by dropping in a different .gguf — no app changes needed
• Run 32k–128k context windows without burning money
Good combos:
• Cursor + Qwopus-v2 → near-frontier quality, zero API cost
• Continue + Qwen3.6-27B → best local coding agent
• aider + Gemma 4-12B MTP → 162 tok/s, feels instant
• OpenCode + Nex-N2-Mini → deep reasoning on 16GB
Set any OpenAI-compatible client to your local endpoint:
set OPENAI_API_KEY=sk-dummy (any non-empty string works)
set OPENAI_BASE_URL=http://localhost:8080/v1
# every OpenAI-compatible tool now hits your local GPU
Shoutouts: @0xSero@rS_alonewolf@witcheer@UnslothAI@LottoLabs
In light of what happened, I'm doubling down on skills like /improve.
A frontier model got pulled. If it happened once, it's gonna happen again. Fable today. 4.9 tomorrow or maybe gpt 6 one day.
So, treat intelligence as borrowed. Drain intelligence when it's available. Build a catalog of plans today. Then implement later with a cheaper, open source, or a model you control.
Build the backlog now.
https://t.co/rqHw0fPv4G
@his_eminence_j@Polymarket When government is allowed to do more than protect the rights of liberty & property, eventually it will try to do everything, except protect liberty & property.
built a littlething for non-technical people drowning in new coding / AI jargon
what's a webhook? a worker? CLI? why does everyone keep saying MCP?
plain english, an analogy for each one, illustrated.
→ https://t.co/u9K38m7WQ8
https://t.co/OsRRM3zBq9
My last AI Coding Cohort was the most successful course I've ever released.
2,500+ students worked with Claude Code for 2 weeks, building a real app with AFK agents and software fundamentals.
So, we made version 2:
- Use any coding agent you like
- Updates for every skill
- Uses Sandcastle for AFK agents
Feeling behind the curve? How would you like to be... ahead of it?
Starts June 1st. Get your seat now:
https://t.co/YmvYUzwpL7
If you love fine-tuning open-source models (like me), then listen.
> Start with 1B, 2B, 4B, and 8B models. (Don't start with a 27B model or bigger at first.)
> Use WebGPU providers. I use Google Colab Pro for any model smaller than 9B. A single A100 80GB costs around $0.60/hr, which is cheap. Enough for small models.
> Don’t buy GPUs unless you fine-tune 7 to 10 models. You'll understand the nitty-gritty in the process.
> Use Codex 5.5 × DeepSeek v4 Pro to create datasets. Codex to plan, DeepSeek v4 Pro to generate rows.
> Use Unsloth's instruct models as a base from Hugging Face. Yes, there are others too, but Unsloth also provides fast fine-tuning notebooks.
> Use Unsloth's fine-tuning notebooks as a reference. Paste them into Codex, and Codex will write a custom notebook with the configs you need.
> Spend 1 day learning about:
- SFT (supervised fine-tuning)
- RL training (GRPO, DPO, PPO, etc.)
- LoRA / QLoRA training
- Quantization and types
- Local inference engines (llama.cpp)
- KV cache and prompt cache
> Just get started. Claude, Codex, and ChatGPT can design a step-by-step plan for how you can fine-tune your first AI model.
Future tech is moving toward small 5B to 15B ELMs (Expert Language Models) rather than general 1T LLMs.
So fine-tuning is an important skill that anyone can acquire today.
Tune models, test them, use them. Then fine-tune for companies and make a career out of it. (Companies pay $50k+ to fine-tune models on their data so they can get personalized AI models.)
Shoot your questions below. I'll be sharing in-depth raw findings about this topic in the coming days.
@eddiejiao_obj@drewocarr @LTXStudio @modal_labs All of this is live! it's early and slow. many of the demos above are sped up/edited, but we can't wait to see what you think. Try it yourself at https://t.co/bcephqPu1c (5/5)
@JeffKirdeikis Hello! We are preparing to get heavily involved with the integration of AI solutions within the US Agricultural Industry, with a focus on keeping solutions as local as possible.
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: https://t.co/NlAfEJjtJV
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Do you want to try Droid?
I’m doing a giveaway 3 people will win 100M Factory credits each.Thats 5 months of their 20$ a month subscription.
Winners selected randomly from comments in 48 hours.