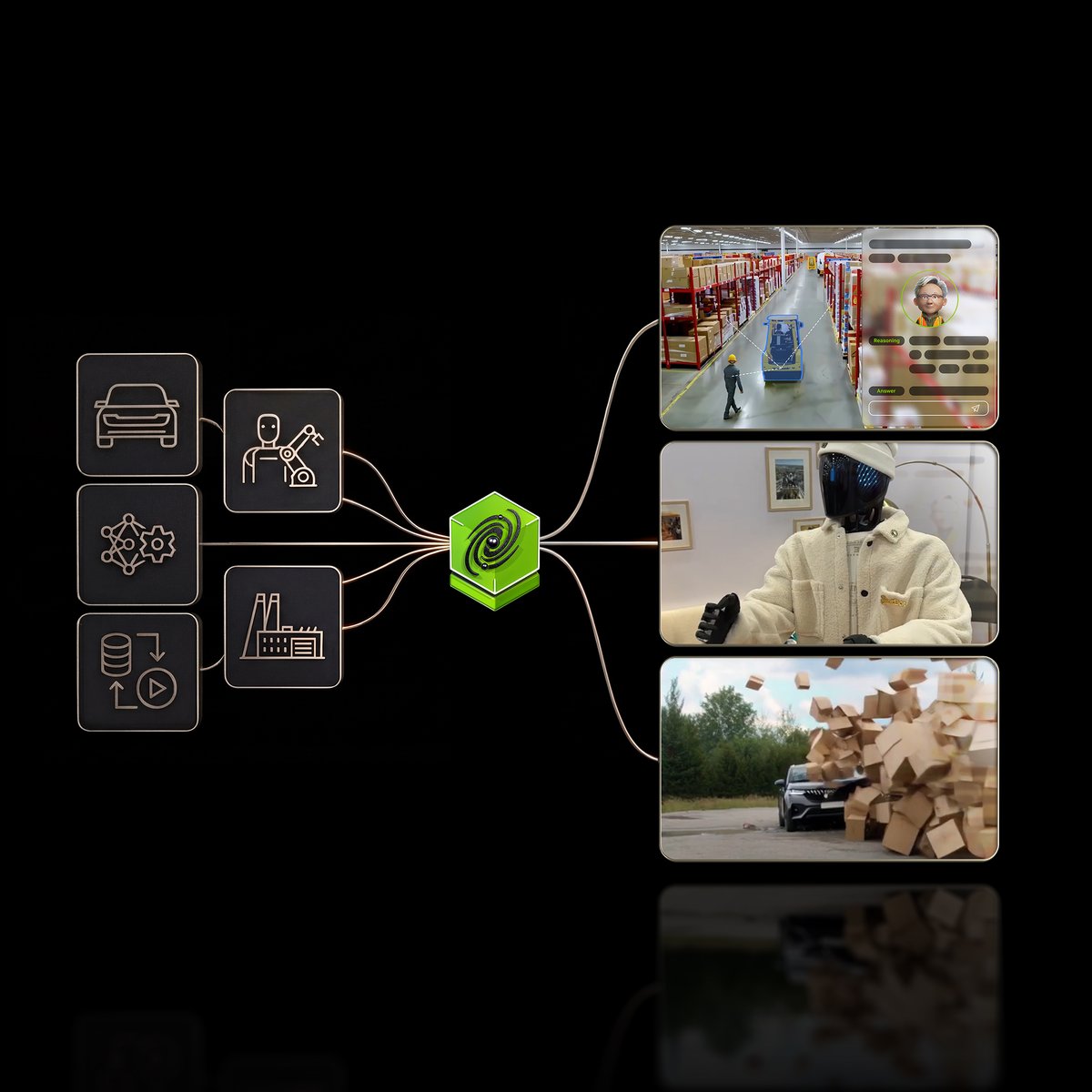
The @nvidia Cosmos Cookoff is here - a 4-week physical AI challenge that could reshape how we approach autonomous systems, and for us it's especially exciting since our CPO and Co-Founder @eranshir is judging alongside experts from @DatatureAI , @huggingface, and @nvidia.
This isn't just another AI competition. With NVIDIA Cosmos Reason 2 and real-world validation requirements, teams will tackle the hardest problems in robotics and AV development - egocentric reasoning, traffic-aware models, and physical plausibility checks.
Eran brings a unique perspective: while others simulate edge cases, Nexar has captured them from 10B+ miles of real-world driving. That's the foundation serious AV development needs.
The industry is finally recognizing what forward-thinking leaders like Eran have advocated for years - simulated data isn't enough. Real roads demand real models.
Jan 29 - Feb 26. Solo or teams up to 4. $5K grand prize plus NVIDIA DGX Spark.
Sign up, and be a part of the future building the future of physical AI: https://t.co/6m0aXrqpTZ
#PhysicalAI #Robotics #AV #EdgeCases #AIChallenge
We’re excited to be part of the NVIDIA Cosmos Cookoff, alongside @nvidia , @huggingface, @nebiusai, and @getnexar
What stands out about Cosmos Reason 2 is its focus on physical AI - moving beyond static perception toward reasoning that accounts for real-world constraints, egocentric understanding, and physical plausibility.
This shift is clear - models must reason in environments governed by physics, not just pixels.
Looking forward to seeing what the community builds over the coming weeks! 🤖
We will also be releasing tutorials on how to leverage cookbooks and blueprints to swiftly build your projects leverage CR2!
🧑🏻🍳 Introducing the NVIDIA Cosmos Cookoff — a virtual, four-week physical AI challenge for robotics, AV, and vision AI builders, sponsored by @nebiusai and @milestonesys.
Build with NVIDIA Cosmos Reason 2 and Cosmos Cookbook recipes—from egocentric robot reasoning to physical plausibility checks and traffic‑aware models.
🗓 Jan 29 – Feb 26
👥 Solo or teams (up to 4)
🏆 Prizes include $5,000, an NVIDIA DGX Spark, and more!
🧑⚖️ With judges from @DatatureAI, @huggingface, @nebiusai, @getnexar, and @nvidia
Sign up and show what’s possible with physical AI ➡️ https://t.co/bAdGbIiCmI
Our latest blog post shows how to fine-tune Vision-Language Models for VQA - so models can answer image-based questions with accuracy & context, not just describe what they see.
Fine-tuning VLMs for VQA is not as simple as feeding models a bunch of image-question pairs. The real challenge lies in dataset preparation and system prompts.
Our guide walks through a practical use case: Fine-tuning Qwen 2.5-VL 7B to answer medical imaging questions using Datature Vi 🤖
Tutorial → https://t.co/j3xKWwCgsD
If you are interested to train your own VLMs, we just launched Vi, a platform that handles annotation → fine-tuning → deployment.
Sign Up For Beta 👉 https://t.co/WyulBS92Am
Most vision-language models don’t fail because they can’t see. They fail because they don’t reason.
Our latest post breaks down Chain-of-Thought (CoT) for VLMs - how explicit reasoning improves grounding ↘
🔗 https://t.co/ORyJLojbJT
ARBOR Technology Corp., a developer of Industrial Internet of Things (IIoT) and edge AI computing solutions, has formed a strategic alliance with @DatatureAI and MemryX Inc.
#MachineVision#AI#Software
Read more here: https://t.co/2vqJAke643
One of the most requested features on @DatatureAI is finally here 🎉
Our new t-SNE Embedding Visualization lets you instantly see how your #datasets cluster - making it easier to spot duplicates, catch anomalies, and speed up labeling.
Really excited for our community to start using this → it’s been on the wishlist for a long time, and the team delivered 🚀
🚀 New on Datature: t-SNE Embedding Visualization
Turn thousands of image embeddings into an interactive 2D map - spot duplicates, detect anomalies, visualize clusters, and speed up curation.
Now Live → Find it under “Projector” in your Asset Tab
AI model accuracy and robustness can be improved by integrating metadata like location enums, IMU data, geo-coordinates, and sensors.
Read more about our experiments with model fusion methods (early, late, hybrid) and best practices in our latest findings ↘
If you missed us at @HIMSS, join us for our webinar to learn more about how Datature can speed up and improve your 3D Medical Model AI Pipeline 🩻
Webinar → https://t.co/nqmZyeY2Lm
At @DatatureAI, we are unifying multi-planar reconstruction annotation, volumetric deep learning, and seamless deployment into a single, integrated intelligence layer.
⚡ Advanced Annotation – AI-driven, scalable labeling for CT, MRI, PET, with strict consensus/review enforcement.
⚡ Volumetric Model Training – Expanded #3DUNET architectures, fine-tuned with 3D augmentation for unparalleled precision.
⚡ Seamless Deployment – Native #3DSlicer integration & PACS support to operationalize insights at scale.
This is just the beginning.
Exciting news! @DatatureAI is headed to #MDMWest in Anaheim, Feb 4-6 at the Anaheim Convention Center, Booth #5529.
Discover cutting-edge machine learning and computer vision for medical, manufacturing & materials solutions with live demos!
Learn how to train an object detection model with YOLOv8 on Datature’s Nexus platform.
In this tutorial, Leonard walks you through: - Training a model to identify and locate objects within images. - Optimizing workflows for speed and accuracy. Applications include warehouse management, autonomous vehicles, and retail analytics. Watch now and see how Nexus simplifies complex tasks #ObjectDetection #AI #ComputerVision #Datature #DatatureTutorials #YOLOv8
Learn how to train a video classification model using MoviNet on Datature’s Nexus platform.
https://t.co/bpZLP59JFK
In this tutorial, Leonard guides you through:
Training a model to analyze and classify actions or events in video sequences.
Enhancing workflows for real-time video processing and accuracy.
Applications include sports analytics, surveillance systems, and content moderation. Watch now and explore how Nexus simplifies advanced video analysis.
#VideoClassification #AI #ComputerVision #Datature #DatatureTutorials #MoviNet
Discover PaliGemma 2: The next-generation vision-language model setting new benchmarks in scalability, high-resolution processing, and domain-specific adaptability.
In this article, we break down its cutting-edge architecture, explore its benchmarks, and highlight the innovations driving its performance.
Perfect for ML practitioners and researchers, this deep dive unveils the model’s capabilities and transformative potential.
Learn more: https://t.co/rSKNw3KlBd