Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
Why "Last Exam"? The name has two meanings:
"Last" as the bar to clear:passing these exams means an agent can actually do the job and continue to deliver economically-valuable work in that profession.
"Last" as the frontier of difficulty:tasks are real, complex, long-horizon, and require professional expertise to execute. ALE sits right at the edge of what today's agents can reliably accomplish.
Come test your agent on ALE →
Website: https://t.co/YjfsZILxBb
Tasks: https://t.co/Pyoud9MffS
Leaderboard: https://t.co/eoURCYi8Jx
Paper: https://t.co/Ts2xbXcQBL
Dataset: https://t.co/EBy9MpJUk1
Code: https://t.co/rcijuQ2Grn
My group & collaborators have built many of the benchmarks the field now runs on — MMLU, MATH, CyberGym, ExploitGym, etc.. I'm really excited to share our latest: Agents' Last Exam (ALE).
Why "Last Exam"? The name has two meanings:
"Last" as the bar to clear — passing these exams means an agent can actually do the job and continue to deliver economically-valuable work in that profession.
"Last" as the frontier of difficulty — tasks are real, complex, long-horizon, and require professional expertise to execute. ALE sits right at the edge of what today's agents can reliably accomplish.
A few things that make ALE different:
• Real work, not vibes. Every one of the 1,500+ tasks comes from real projects or research contributed by domain experts. We converted them into verifiable tests and objectively graded evaluations — no human judges required.
• Built for breadth. ALE spans 55 non-physical occupations based on the O*NET / SOC 2018 occupational taxonomy, with contributions from 300+ experts across 100+ institutions.
• Judged on results, no restriction on process. We evaluate Generalist Computer-Use Agents (GCUAs) with full GUI + CLI access, allowing them to solve tasks however it would — clicking, typing, scripting, browsing, and more. We just grade the outcome.
Huge thanks to my postdoc @YiyouSun for spearheading this tremendous effort, and to our esteemed advisory committee, incredible team and collaborators who made it possible.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains. 🧵👇
“AI agents will outperform humans at almost all jobs by 2026–2027.” - The forecast is everywhere.
So we built the exam to test that claim, on real labor-market aligned work. On the hardest tier, top agents pass 2.6%.
Meet Agents' Last Exam (ALE), a rolling benchmark measuring whether agents can actually do real jobs. 🧵👇
Static benchmarks inevitably saturate as models improve.
Our recent work explores how to evolve existing tasks into harder, validated variants that co-evolve with frontier models — and also serve as RL training data for self-improvement.
A step toward benchmarks that evolve as quickly as the models they measure.
Static benchmarks are dying — they tend to get saturated quickly.
Evaluation and training data should co-evolve with frontier models.
We released BenchEvolver — a framework that automatically evolves saturated problems into harder, verified tasks for evaluating frontier models, which can also serve as useful self-improvement signals for RL.
New work from UC Berkeley @berkeley_ai@BerkeleyRDI@BerkeleySky
Project Page: https://t.co/PL1KpGyd87
Paper: https://t.co/gBQOXrZbAV
Excited to see ExploitGym used to evaluate Claude Mythos Preview’s cyber capabilities.
ExploitGym tests a critical question: can AI agents turn real vulnerabilities into working exploits? ExploitGym is the first comprehensive benchmark to systematically evaluate this question, including 898 real-world exploitation tasks across userspace programs, V8, and the Linux kernel, with realistic mitigation toggles.
Exploitation remains challenging, but frontier models are making significant progress, underscoring the need for rigorous, reproducible, dual-use cyber evaluations.
Last month we launched Project Glasswing, our collaborative AI cybersecurity initiative. Since then, we and our partners have found more than ten thousand high- or critical-severity vulnerabilities in essential software.
6/ Many thanks to our wonderful coauthors and collaborators from UC Berkeley, MPI-SP, UCSB, ASU, Anthropic, OpenAI, and Google for their invaluable contributions.
We also sincerely thank the support from the GLM team, as well as everyone who provided feedback and help for this work.
Paper: https://t.co/fkVWJbNZvf
Blog: https://t.co/ZoX6jjYDhs
1/ Can AI agents turn security vulnerabilities into real attacks?
This is one of the most critical tasks for measuring the impact of frontier AI on cybersecurity.
In ExploitGym, we find that autonomous exploitation is no longer hypothetical, even on complex targets such as browser engines and the Linux kernel.
How we measured this⬇️
5/ This is deeply dual-use. ExploitGym gives defenders, AI developers, and policymakers a rigorous way to measure frontier cyber capabilities and reason about risk.
Excited to share DecodingTrust-Agent Platform (DTap), the first controllable, full-stack simulation platform for advanced AI agent red-teaming across 50+ realistic environments.
DTap supports multiple attack vectors, including environment-, tool-, skill-, and prompt-level injections, as well as their compositions. We also build DTap-Bench, a ~7K-task benchmark with complex workflows and sophisticated attacks for evaluating agent security and utility under realistic threat scenarios.
Through DTap, we uncover systematic vulnerabilities and zero-day failure modes in popular agents such as OpenClaw and Claude Code, and provide insights on how to improve harness design, tool execution, and trust calibration for more robust agentic systems.
Read our paper to learn more 👇
Paper link: https://t.co/TeCeqfDsd9
Platform + benchmark + code: https://t.co/dlyeMoTba3
Great work by the team!
AI agents are already going wild, but today’s red-teaming tools for them are still like toys 😢
🔥👽 After spending 20 months and $120K API credits, we are excited to finally open-source DecodingTrust-Agent Platform (DTap): the first controllable, realistic simulation platform for advanced AI agent red-teaming !!
🌍 DTap simulates 50+ real-world environments across 14 high-stakes domains, with realistic agent interfaces replicated from their official MCPs and GUIs. The environments are full-stack, interactive, fully parallelizable, and can be easily configured to reproduce arbitrary real-world attack scenarios, making agent red-teaming scalable and highly transferable to deployment settings.
🔥We also release DTap-Bench, a large-scale benchmark with ~7K agent red-teaming tasks and ~4K policy-grounded malicious goals.
Each red-teaming task includes a sophisticated attack sequence across environment-, tool-, skill-, prompt-level injections, as well as their compositions, plus a handcrafted verifiable judge that checks the actual consequences in the environment.
Using DTap-Bench, we evaluate popular agent frameworks and backbone models across diverse policies, risks, threat models, and attack strategies, revealing systematic vulnerabilities and zero-days in today’s agents!
Paper link: https://t.co/PjnGC5wKk9
Platform + benchmark + code: https://t.co/aicipKMnig
Join our Discord: https://t.co/8UyRjH6RqX
Read more below 👇
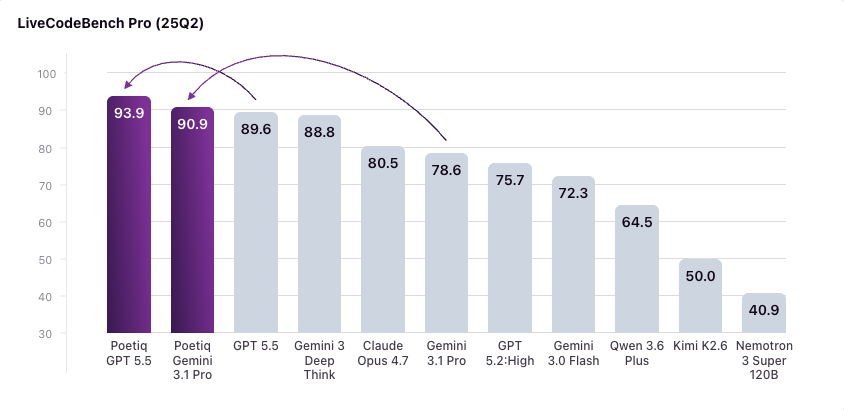
Poetiq did it again: SOTA on LiveCodeBench Pro after ARC-AGI and HLE! Truly impressive work from @poetiq_ai, really showing the power of their meta-system for agentic AI!
Poetiq's Meta-System built its own coding harness from scratch. It got SOTA on LiveCodeBench Pro.
No fine-tuning, no special model access. Just standard APIs. Using Gemini 3.1 Pro, it made a harness that beat all frontier models we tested.