Can AI agents truly synthesize information across multiple sources?
🏆 Best system: 8.97 F1
❌ Most systems: 0% exact match
🚀 Introducing DEEPSYNTH, our new benchmark accepted at #ICLR2026!🇧🇷
📄 Paper: https://t.co/lmSQHtWS6q
🤗 Data: https://t.co/sjHPBlEyoc
🔬 Hiring 2 undergrad research interns (6 months) at Microsoft Research India.
The transformer has been the default encoder for dense retrieval. But under the low-latency constraints of real production systems, it becomes a serious bottleneck on retrieval performance, deep encoders are accurate but too slow, shallow ones are fast but lossy.
So we're asking fundamental questions:
→ What assumptions are we baking in when we reach for a transformer to solve a task?
→ What alternative scalable encoder architectures can exploit the natural biases of retrieval better than the transformer does?
What interns will actually work on over 6 months:
→ Critically analyzing where transformer-based dense encoders fall short under production retrieval pressure
→ Exploring alternative architectures that preserve deep-encoder accuracy at a fraction of the inference cost
→ Data + compute efficient training algorithms for large dense encoders
Strong Python + PyTorch. Bonus if you've trained an encoder or built a retrieval pipeline end-to-end.
For undergrads who treat "why is the architecture shaped this way?" as a real question.
Apply: https://t.co/eTfA15eRnU
DMs open.
#InformationRetrieval #MLSystems #NLProc
@MSFTResearch
The better LLMs get at reasoning, the longer their traces get—thousands of tokens, dozens of tool calls. But in law, medicine, and agentic AI, "usually correct" isn't good enough: answers must be verifiably correct.
We built interwhen at @MSFTResearch to make that tractable. And it's now open source.
Across benchmarks, plugging interwhen into an LLM yields:
✅ 100% soundness (with full verifiers)
📈 up to 15% accuracy gain
⚡ ~ 1.5× compute cost
🧵
📢 Open-sourcing the Sarvam 30B and 105B models! Trained from scratch with all data, model research and inference optimisation done in-house, these models punch above their weight in most global benchmarks plus excel in Indian languages.
Get the weights at Hugging Face and AIKosh. Thanks to the good folks at SGLang for day 0 support, vLLM support coming soon. Links, benchmark scores, examples, and more in our blog - https://t.co/DcCG3zlN8p
In the LLM era, author responses seem much longer, with more arguments and justification. I felt this in my own pool. Are meta-reviews drifting toward weighing extended defenses and vague complaints about reviewers instead of the technical core?
#ACL2026#NLProc
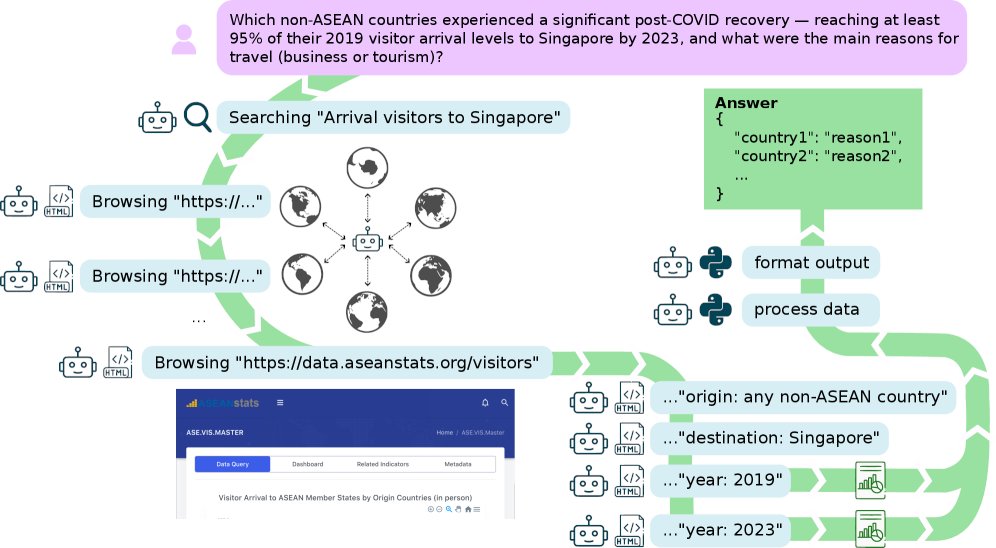
Your AI agent scores 95% on benchmarks but can it actually synthesize information from multiple sources to answer a real question?
DEEPSYNTH, a new benchmark from @DebjitPaul2, Daniel Murphy, Milan Gritta and team at Huawei Noah's Ark Lab (@HuaweiNoahsArk), @imperialcollege, @ucaboratory, and @Cambridge_Uni, tests exactly this. 120 tasks across 7 domains, 67 countries, requiring agents to gather data, cross reference sources, and produce structured insights.
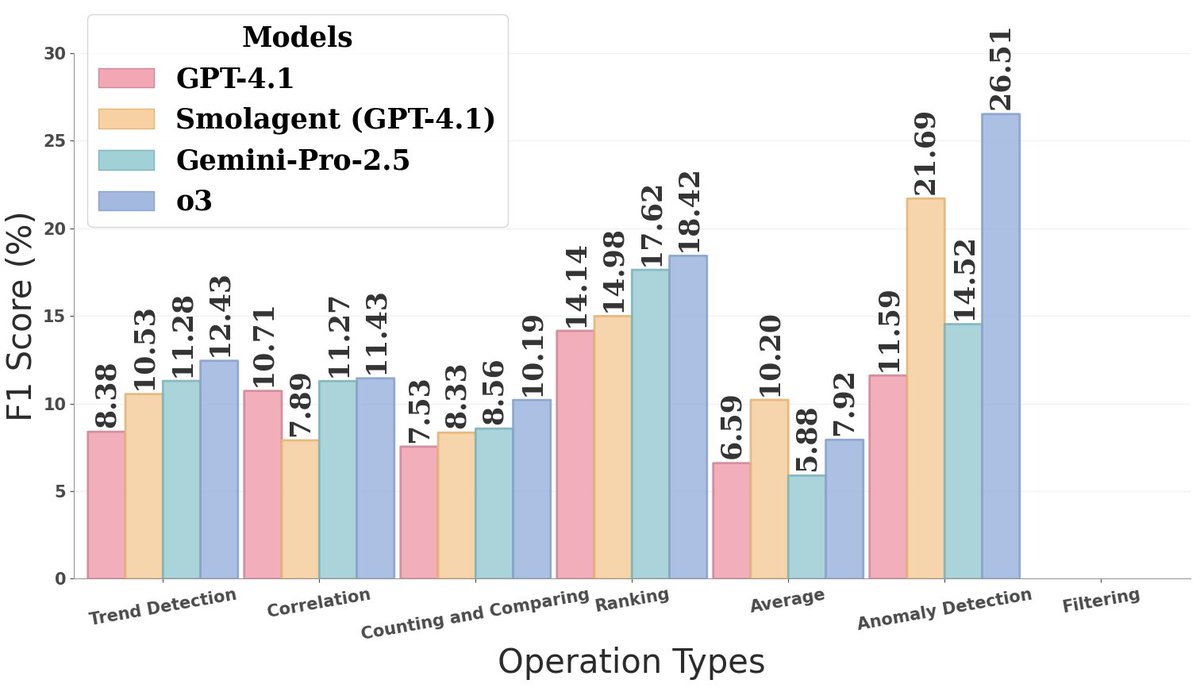
The results are sobering: 11 state of the art LLMs and deep research agents top out at 8.97 F1. The best LLM judge score reaches only 17.5. Models hallucinate freely and collapse when reasoning over large information spaces.
The gap between answering trivia and doing actual research remains massive. Accepted at ICLR 2026.
Can AI agents truly synthesize information across multiple sources?
🏆 Best system: 8.97 F1
❌ Most systems: 0% exact match
🚀 Introducing DEEPSYNTH, our new benchmark accepted at #ICLR2026!🇧🇷
📄 Paper: https://t.co/lmSQHtWS6q
🤗 Data: https://t.co/sjHPBlEyoc
Work done in collaboration with Daniel Murphy, @milangritta, Ronald A. Cardenas, @victor_p91, Jun Wang, @glampouras_NLP, and an amazing annotation team.
Project Page: https://t.co/cioEw2oWSZ
Can AI agents truly synthesize information across multiple sources?
🏆 Best system: 8.97 F1
❌ Most systems: 0% exact match
🚀 Introducing DEEPSYNTH, our new benchmark accepted at #ICLR2026!🇧🇷
📄 Paper: https://t.co/lmSQHtWS6q
🤗 Data: https://t.co/sjHPBlEyoc
🔍 Key findings: Current agents “struggle with hallucinations and reasoning over large information spaces”. In other words, they tend to make unsupported claims or miss links across sources when answering complex questions.
Hiring alert 🚀 – Microsoft Research India.
We’re expanding our team in AI reasoning and related areas.
If you’re building reasoning models, verification frameworks, or next-gen research agents, I’d love to connect.
Roles across levels + Postdoc openings.
DM me to chat.
🚨 I'm looking for emergency reviewers for ARR submissions in the interpretability and analysis track. Topics include: Analysis of CoT, Supervised Fine-tuning, and Matryoshka Representation Learning.
🚨 ARR Jan 2026 needs 5–6 emergency reviewers
If you have bandwidth for one additional paper, I’d really appreciate the help. DM or email me.
Please DM - and feel free to RT 🙏
I go around saying we should be builders across the 'full stack' @SarvamAI - from compute, to data, to models, to apps. And in come @thekrishnambiar and @thedesignobsess and say we should compose our own music for model launches! And so here we go with our first Sarvam sound track.
India's most ambitious decade to build is here; come join the build.
And yes for your ringtone upgrade, go here: https://t.co/Bcngnsjsvw
Drop 4/14: Introducing Sarvam Vision: a state-space based 3 billion parameter vision language model that is competitive with the best results in digitisation in English, and defines a significantly higher bar for Indian languages. See the details in our blog: https://t.co/HyGMPNWJu7
I started my career as a theorist, and am now an empirical LLM researcher. In today's blog post, I talk about the parallels between theory and empirical research: https://t.co/7YozHl514D