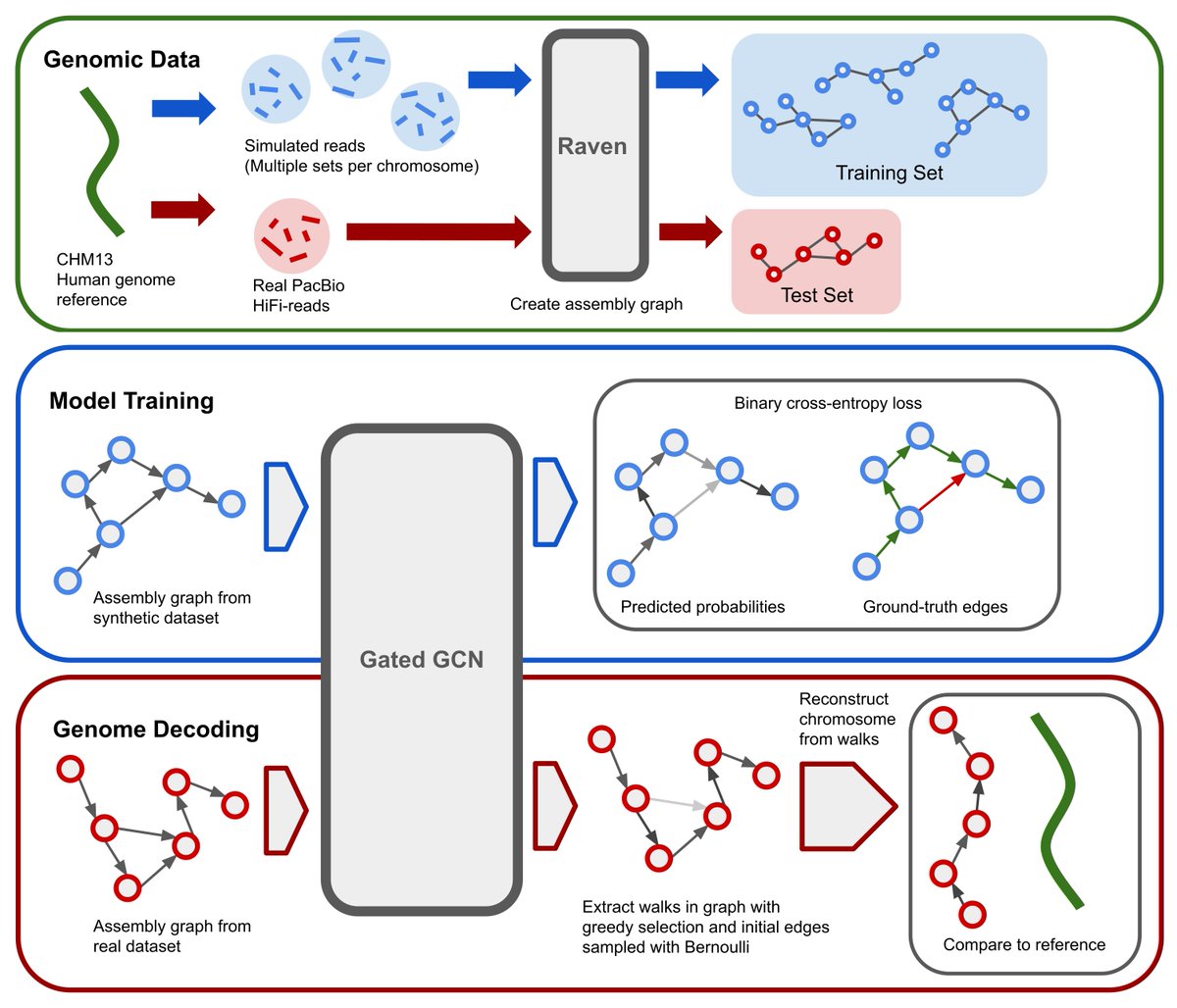
Our new paper is out! We made a lot of progress on our GNN-based de novo genome assembly paradigm and here we present all our findings and progress 🧬🥳
Code: https://t.co/L4vDO0SSZn
Paper: https://t.co/90jHKL0Jjd
See details of GNNome below 👇🧵
Happy to present RiNALMO - our RNA large language model https://t.co/V1N8D1QeJh w/ @RJPenic Tin Vlasic @ywan_wan and Roland Huber.
RiNALMo is the largest RNA language model to date, with 650 million parameters pre-trained on 36 million non-coding RNA sequences. 1/2
Are nanopore UL reads only long reads we need? We developed Herro https://t.co/KyR3LPx5rT AI error correction model that can correct reads to accuracy above Q30 while trying to keep informative positions intact. w/ @domstanojevic@DehuiLin@sergeynurk@PaolaFlorezdeS@nanopore
Long reads metagenome benchmark is out. Highlights. 1. In most cases Kraken, 2. minimap2/ram for slightly higher accuracy. 3. The right database is of huge importance 4. Check taxonomy files carefully. https://t.co/VqbanGKrIU w/@NiranjanTW@KrizanovicK @jmaricb @Sylvain14518009
After many months, I'm proud to share our work on untangling genome assembly graphs with GNNs. Or, GNNome Assembly (sorry not sorry)🧬
Paper: https://t.co/LjBGjwI7km
Code/Data: https://t.co/T0YrGTzosi
with @xbresson, T. Laurent, @Martin_fschmitz, and @msikic.
Read more in 🧵