i've recently been distilling stockfish into a no-search transformer. some cool results:
- recreated the neural scaling laws
- observed chinchilla optimality
- curriculum learning on ascending depth data sub-performs
you can also play against the model! (full details below)
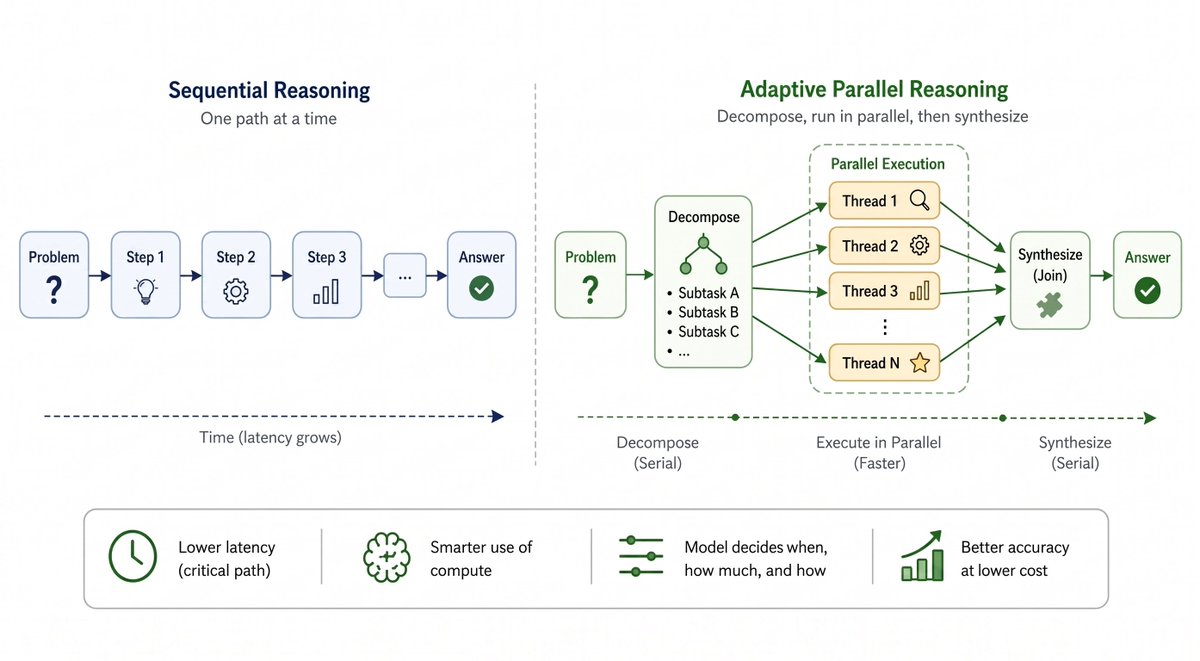
Longer chain-of-thought = slower inference, more context rot, and ballooning compute.
So what if the model could decide for itself when to go parallel?
Our new BAIR blog breaks down Adaptive Parallel Reasoning (APR) — the next paradigm in inference-time scaling. 🧵