New paper! LLM memory keeps improving, but this makes them *worse* as user sims. If we want to build models that can, e.g., simulate realistic students to train chatbots to be better teachers, then these models need to be able to forget like humans do
📄: https://t.co/1GpOfwcsat
Today, we’re thrilled to share that our friends at @TrajectoryLabs have officially launched from stealth!!!
We first met Ronak a few days before Delta was founded in February 2025, and it’s been an incredible journey seeing him grow from his time at Windsurf, to DeepMind, and now to Trajectory.
The Trajectory team has seen Delta’s full trajectory, and now we’re incredibly excited for the world to see theirs!! 🚀
“When all is said and done, and Nature passes her final judgement, you will not be measured by the number of moments in which you worked as hard as you could. You will not be judged by someone rooting around in your mind to see whether you were good or bad. You will not be evaluated according to how unassailable your explanations are, for why the things that you couldn't possibly have prevented the things that went wrong.
You will be measured only by what actually happens, as will we all.”
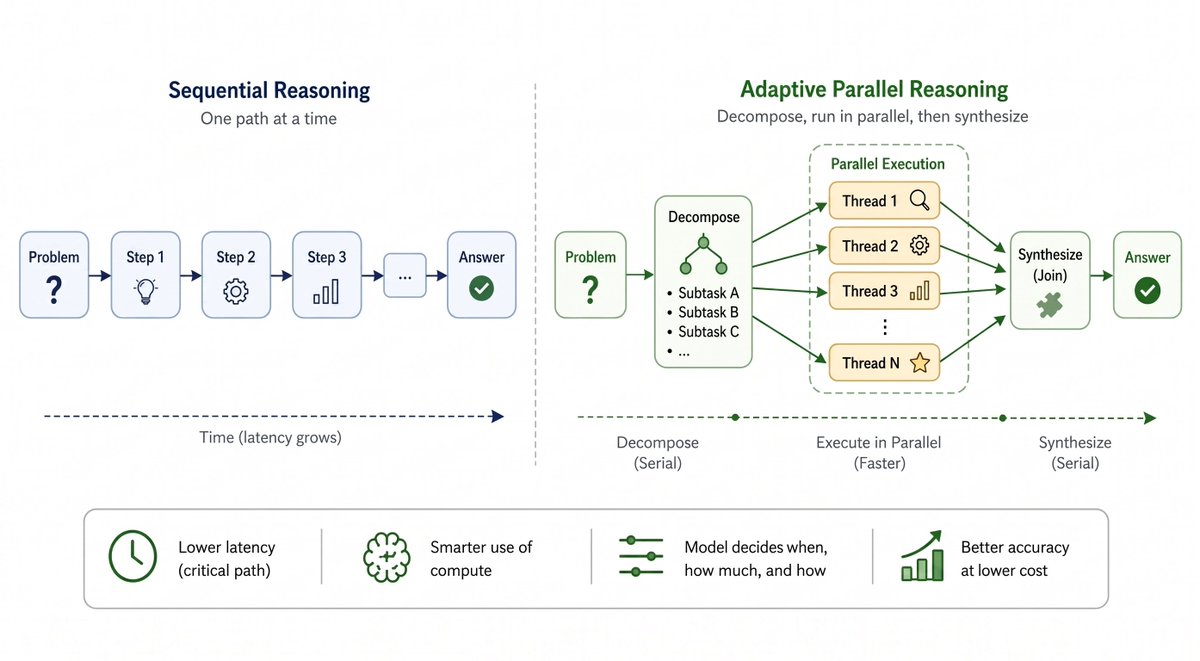
Longer chain-of-thought = slower inference, more context rot, and ballooning compute.
So what if the model could decide for itself when to go parallel?
Our new BAIR blog breaks down Adaptive Parallel Reasoning (APR) — the next paradigm in inference-time scaling. 🧵
Full post — inference systems, training recipes, reward design, eval, and a survey of Multiverse, Parallel-R1, NPR, ThreadWeaver + the original APR method (Pan et al., 2025):
https://t.co/iFQwVISoue
Co-authored with @tonylian!