How to use UMAP dimensionality reduction for Embeddings to show multiple evaluation Questions and their relationships to source documents with Ragas, OpenAI, Langchain and ChromaDB by @DocBrownMS https://t.co/QhmQzTof2g
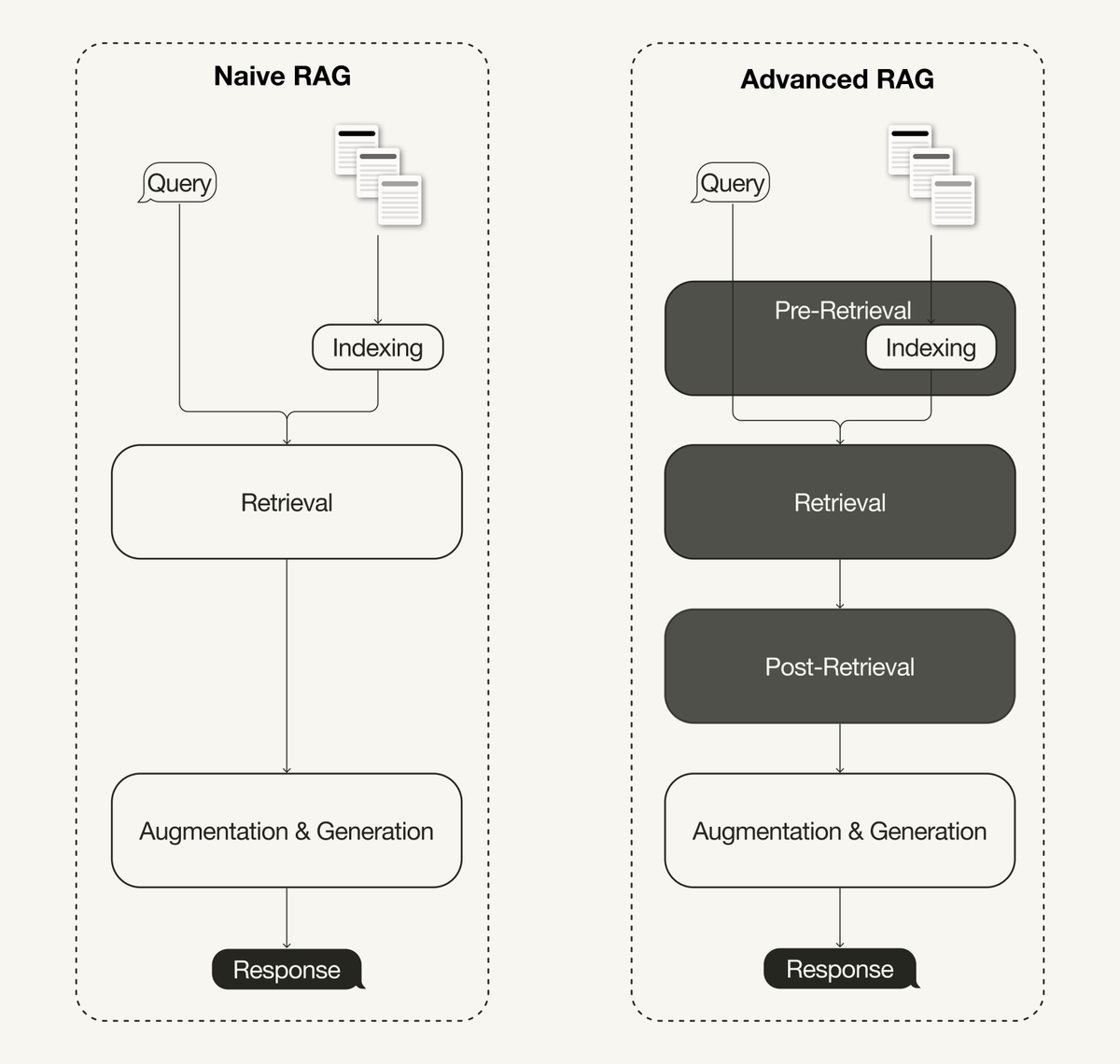
Advanced Retrieval-Augmented Generation (RAG) techniques address the limitations of naive RAG pipelines.
A recent survey on RAG classifies advanced RAG techniques into pre-retrieval, retrieval, and post-retrieval optimizations.
🔗 Paper: https://t.co/dWkf0Uc587
My latest article gives an overview of advanced RAG techniques:
🦙 Pre-retrieval includes techniques like sliding windows, enhancing data granularity, adding metadata, or optimizing index structures, such as sentence window retrieval.
🦙 Retrieval includes optimizing the embedding models (e.g., fine-tuning) or advanced retrieval techniques like hybrid search
🦙 Post-retrieval includes reranking or prompt compression.
We also implement a naive RAG pipeline using @llama_index and then enhance it to an advanced RAG pipeline using the following:
• Sentence window retrieval (as a pre-retrieval optimization)
• Hybrid search (as a retrieval optimization)
• Re-ranking (as a post-retrieval optimization)
💻 Jupyter Notebooks: https://t.co/MFiz00RQHb
Read more on @TDataScience: https://t.co/zgD02G1Rn7
Game changer. You can now visualize your RAG Data.
See how questions, answers, and sources are related.
The animation below shows the UMAP of the embeddings of document snippets, colored by their relevance to the question "Who built the Nürburgring?"
UMAP is dimensionality reduction techniques that transforms complex, high-dimensional data into a clear and interactive 2D map.
It can also be used for debugging and improving the performance of your RAG models.
Use big models to specialize small models! Thats the way. 💫 🚀
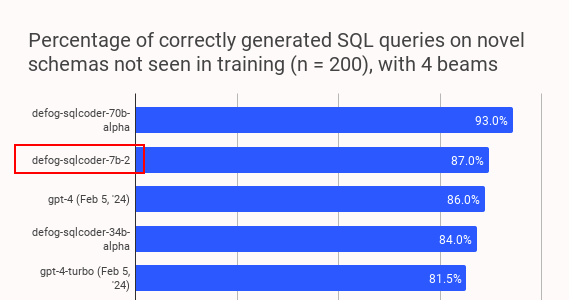
7B Text-to-SQL model outperforms @OpenAI GPT-4 (Turbo)! @defogdata released a new fine-tuned @AIatMeta Code Llama 7B model outperforming the latest GPT-4 & GPT-4 Turbo Models!
The team boosted the 7B performance by leveraging distillation from a fine-tuned 70B Code LLama model! 👨🏫
Models can be commercially used (CC-by-SA-4.0) and are available on @huggingface
👉 https://t.co/O0zglaYd4t
@rishdotblog mentioned they are now pushing for improved performance on joins and group-bys! 🤌🏻 Big Shoutout to Defog for pushing open Code Models! 🧑🏻💻
Spotlight, Spotlight Pro, and Spotlight API Docs 1.5.5 have been released at https://t.co/qW49pbV0SF
Features:
- Transmit errors via websockets and display them
- Disable caching of frontend files.
- Rouge score lens.
- Toggle between continuous and discrete coloring
- Rebuild old-style H5 datasets using dataset.rebuild().
- Apply filters on the confusion matrix widget.
- Utilize Mel scale for spectrogram visualization.
Bug Fixes:
-Ensure browser always opens on localhost.
-Adjust color scaling for spectrogram decibel levels.
-Prevent failure when no simple converter is available
-Explicitly fail when data source is not supported.
-Improve appearance of ns-datetimes.
-Avoid reusing the viewer when a new port is assigned.
@skeptrune@renumics@huggingface@CleanlabAI With PCA from the scikit-learn package and an additional Procrustes Analysis [3] from the SciPy package. This enables smoother transitions in the animation. More details and source code in https://t.co/wNNkCgKxpb