For some reason, AI has convinced people that closed-source software is the way forward.
It's not. Security through obscurity isn't security.
Anyone claiming otherwise is too dumb to understand the problem and thus must not propose solutions.
Speak less, listen more.
Tokenmaxxxing: seeing a stairwell notice about hedge trimming and teaching @_HermesAgent to turn it into an OCR → sabre/vobject → iCalendar → iTIP-over-email pipeline, instead of just adding the damn event to your calendar manually.
In the next months I'll provide you with a Hacker News replacement that I'll run myself and I'll guarantee personally: no benefit for whatsoever individual, a team of 10/20 persons since the start, from different time zones, clear rules, total transparency, and a "karma" system. I really want to fix HN and provide something that is not bound to a specific company.
@Dimillian Move connections feature from beta to main app.
Option to automatically keep cli updated from app.
Synced state between cli and app.
Adhoc sessions outside of a project.
iOS app.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
tldr; if you used @vltpkg as your package manager, then you were protected the minute @SocketSecurity flagged the malicious packages in the `axios` attack yesterday. The best time to switch your package manager was 48hrs ago, the next best time is right now.
More below: https://t.co/7ePAlJT54t
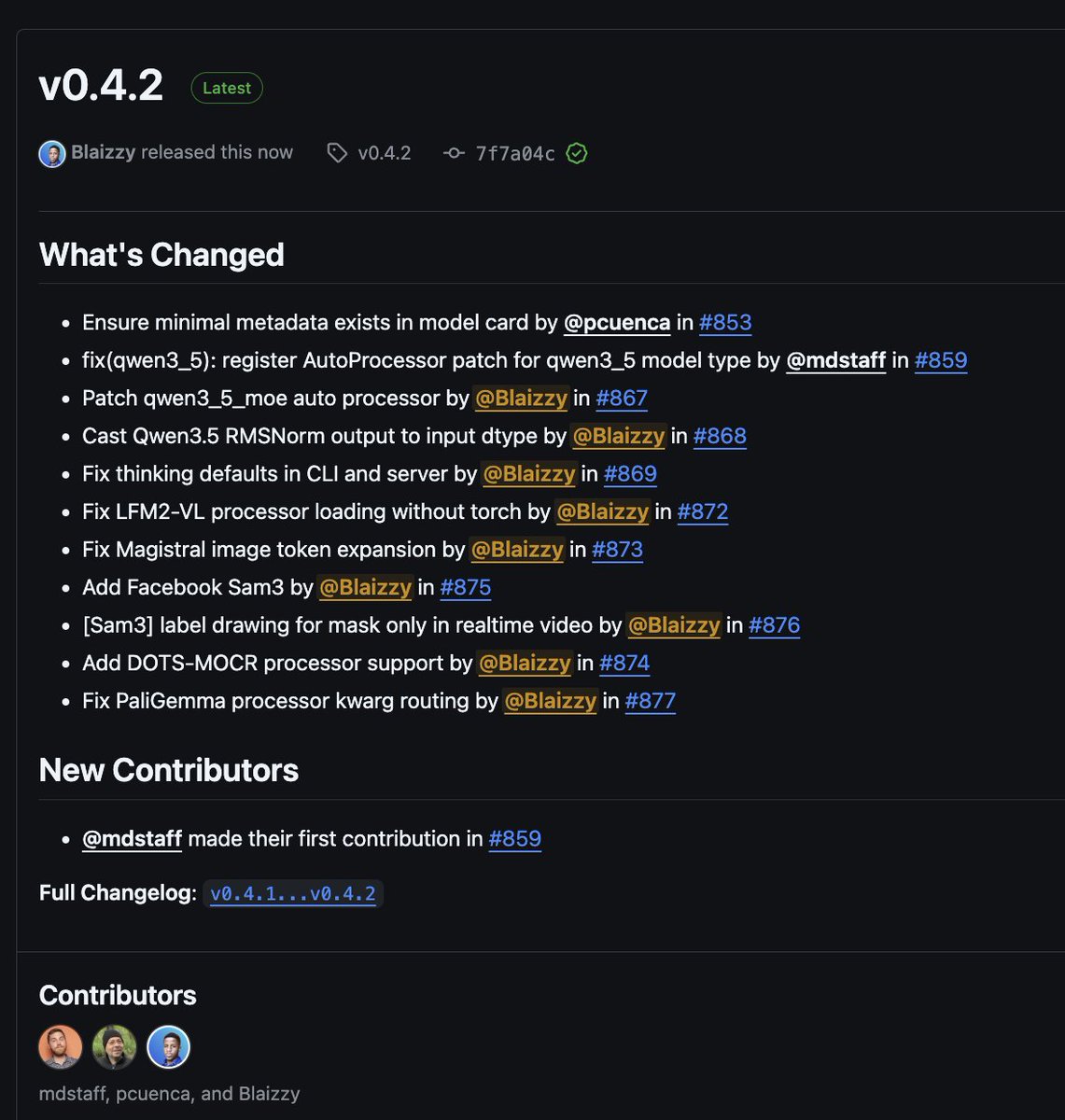
mlx-vlm v0.4.2 is out 🚀
New models
• Sam3 by @facebook (+ realtime mask-only label drawing)
• DOTS-MOCR by rednote-hilab
Fixes
• Qwen3.5 RMSNorm dtype fix
• LFM2-VL loads without torch
• Magistral image token expansion fix
• PaliGemma processor kwarg routing fix
• Thinking defaults fixed in CLI + server
Shoutout to @pcuenq, and @mdstaff for his first contribution!
Get started today:
> uv pip install -U mlx-vlm
Leave us a star ✨
https://t.co/DAM9aS9Y9V
Apple Xserve is back !?!?!
Apple Xserve 2024 ? ? ?
😱😱A3174😱😱
Looks like 4-way Apple M2 Ultra chips.
It even has 16GB RAM and 1TB SSD on the BMC.
I think the BMC controller might be an Apple M1/M2 CPU?
---
🤔Are they still using the MacOS Server OS???🤔
seems obvious but:
things that are changing rapidly:
1. context windows
2. intelligence / ability to reason within context
3. performance on any given benchmark
4. cost per token
things that are not changing much:
1. humans
2. human behavior, preferences, affinities
3. tools, integrations, infrastructure
4. single core cpu performance
therefore,
ngmi:
1. "i found this method to cut 15% context"
2. "our method improves retrieval performance 10% by using hybrid search"
3. "our finetuned model is cheaper than opus at this benchmark"
4. "our harness does this better because we invented this multi agent system"
5. "we're building a memory system"
6. "context graphs"
7. "we trained an in house specialized rl model to improve task performance in X benchmark at Y% cost reduction"
wagmi:
1. product/ui
3. customer acquisition
4. integrations
5. fast linting, ci, skills, feedback for agents
6. background agent infra to parallelize more work
7. speed up your agent verification loops
8. training your users, connecting to their systems and working with their data, meeting them where they are
I got a 1T-parameter model running locally on my MacBook Pro.
LLM: Kimi K2.5
1,026,408,232,448 params (~1.026T)
Hardware: M2 Max MacBook Pro (2023) w/ 96GB unified memory
Running on MLX with a flash-style SSD streaming path + local patching.
This is an experimental setup and I haven’t optimized speed yet, but it’s stable enough that I’ve started testing it in an autoresearch-style loop.
#LocalAI #MLX #MoE