For Spring semester, I'm bringing back free weekly open office hours for anyone in the world with Econometrics questions.
Tuesdays 4-6 PM Central European Time (US EST 10AM-12PM) or by appointment; sign up and drop by!
It's a wrap! Very proud to have hosted a fantastic workshop on new methods & models in macro. Two days, ten terrific talks, many lively debates on new models, computation, AI, rational expectation & RL, state/sequence/path space, and beyond. A thread on the talks & frontier🧵
@JesusFerna7026@ProfArbel Benchmarks for LLMs on procedurally generated microeconomic reasoning tasks show good performance for frontier models 1 year ago.
See https://t.co/OZP3yqywEL
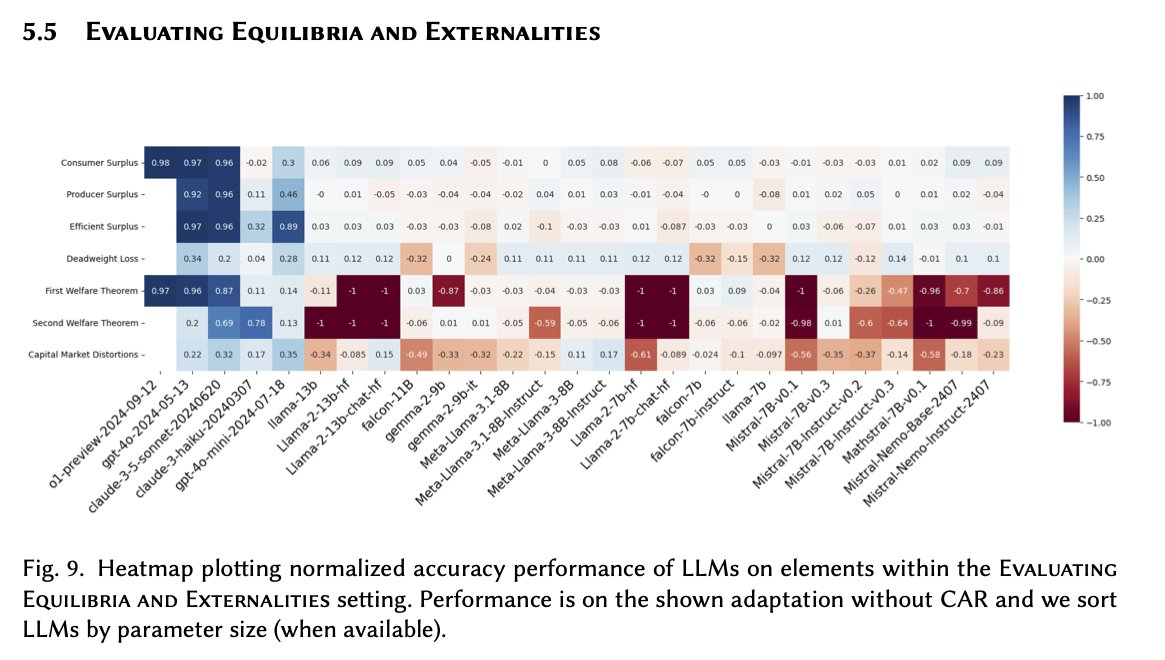
The "art" of price theory, converting a qualitative scenario into a model of this form, is likely harder to evaluate.
@causalinf Lecture 1 & 2 of my computational econ notes, based on Judd's textbook, explain floating point and its propagation. For regression, differences arise due to multicollinearity and mixed scaling, but different algorithms matter a lot in high dimesnions! https://t.co/vA89cajpjn
@jmwooldridge@pedrohcgs Surely that goes into the Intro to Probability and Statistics class that's a prerequisite for Intro to Econometrics, right?
https://t.co/BWN14wmzlm
PSA that due to long-ago choice of username, I am morally obligated to engage with any tweet regarding Donsker's theorem. Please use this power wisely.
For Spring semester, I'm bringing back free weekly open office hours for anyone in the world with Econometrics questions.
Tuesdays 4-6 PM Central European Time (US EST 10AM-12PM) or by appointment; sign up and drop by!
@cis_female That's a pretty modest amount relative to contemporary persistent current account surpluses? There are good reasons to dislike commodity-based currencies, but this is not a feature unique to them.
On the Chinese example, see Jin Xu's "Empire of Silver": https://t.co/BIFRIa8LK0
For Spring semester, I'm bringing back free weekly open office hours for anyone in the world with Econometrics questions.
Tuesdays 4-6 PM Central European Time (US EST 10AM-12PM) or by appointment; sign up and drop by!
I’m at NeurIPS this week (12/2-12/8) to present our work on when/how synthetic data (e.g., LLM simulations) can help scientists make inferences with less real data, improving the efficiency of costly experiments. Come by Poster #904 on Thursday 4:30PM (Exhibit Hall C,D,E)!🙂
We are very proud to present our outstanding 2025/26 cohort of job market candidates from the @UZH_en Department of Finance/Swiss Finance Institute! ✨✨✨✨✨ https://t.co/eKlIVyErvM
Please find their research interests and job market papers below👇👇👇
I will be at University of Tübingen on Tuesday Dec 2, and at NeuRIPS in San Diego Dec 3-8 spreading the good word of the Generalized Method of Moments in the age of AI.
Econometrics lovers come say hi!
@t_holden I was in a seminar the other day where the speaker really did forget to cluster their standard errors. Sometimes you just gotta play the hits.
Updated Fall time for free weekly open office hours for anyone in the world with Econometrics questions.
Wednesdays 3:30-5:30PM Central European Time (US EDT 10:30/EST 9:30AM) or by appointment; sign up and drop by!
Updated Fall time for free weekly open office hours for anyone in the world with Econometrics questions.
Wednesdays 3:30-5:30PM Central European Time (US EDT 10:30/EST 9:30AM) or by appointment; sign up and drop by!
Working on this project to understand how LLM simulation data could contribute to drawing valid scientific conclusions from real world data, led by @yewonbyun_ with @shantanug7, was a great learning experience. Happy to see it forthcoming at #NeurIPS2025
Valid inference w/ LLM-simulated data:
1. Take subsample of texts, extract vars
2. Construct moments identifying param on those vars
3. Ask LLM to simulate vars on sample & remaining texts
4. Use same moments w/ simulated vars
5. Combine moments, estimate jointly w/ 2-step GMM
💡Can we trust synthetic data for statistical inference?
We show that synthetic data (e.g. LLM simulations) can significantly improve the performance of inference tasks. The key intuition lies in the interactions between the moments of synthetic data and those of real data