#Antropic’s #Fable5 Has been stopped:
Everyone's covering the Anthropic suspension as a capability story. Most powerful model, forced offline, "too powerful to release."
Wrong layer.
The whole dispute is about a jailbreak: a bypass of the safeguards. Anthropic's own defense: the technique surfaced a few minor known bugs, and other public models do the same without needing the bypass.
So the capability was never the load-bearing claim. The safeguard was. And a safeguard is a supervision layer wrapped around a model, which is exactly where reliability lives or dies.
"73% exploit rate" is a capability number. Whether you can reliably stop that capability when you need to is a supervision number. They are not the same, and conflating them is how you recall a model used by hundreds of millions over a jailbreak that probably exists everywhere.
I think there are formal limits on how reliable that control layer can be. This is fundamentally an #AI reliability problem and a security problem.
From a degen wallet to Crypto Person of the Year 2026.
The market's up and down, but the self-custody keys and on-chain grind is forever.
Appreciate the recognition @RallyOnChain 🫡
https://t.co/F7tQBxBuEn
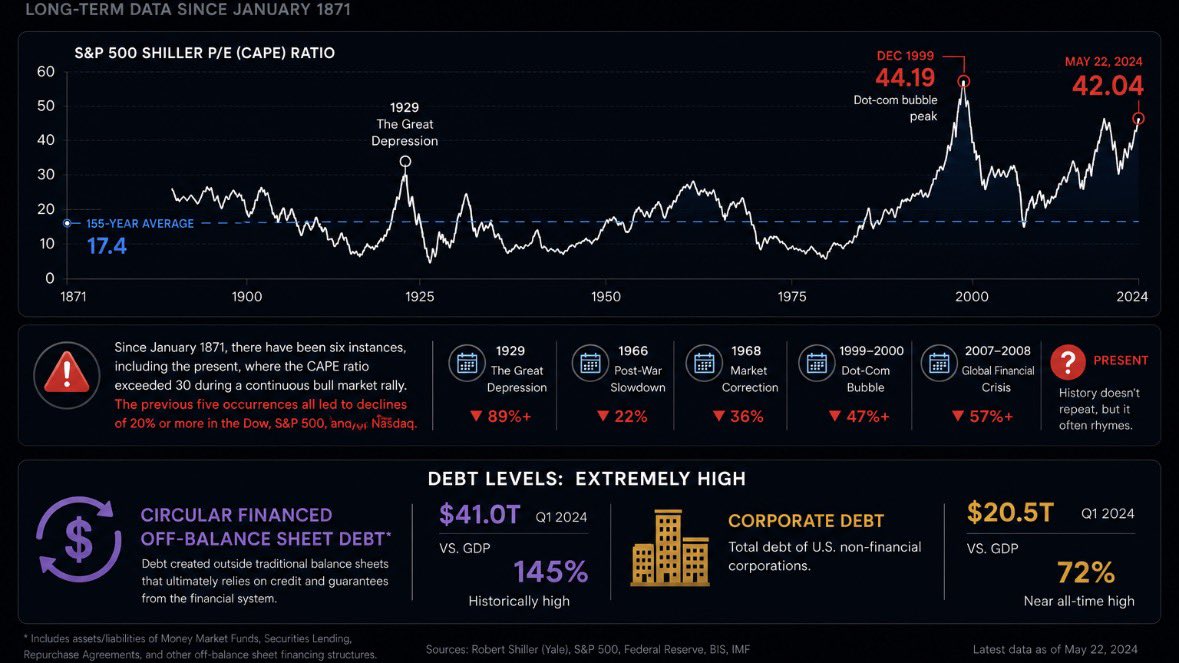
All of this hype about $SPCX meanwhile no one is paying attention to history repeating itself. The top is in, yet nobody seems to realize.
• CAPE: ~41.5 (vs 17 avg)
• Buffett Indicator: ~230% (vs 90% avg)
• AI Capex: ~$700B this year
• AI-related capital formation: $1T–$1.5T
The $SPY is trading near the highest valuation levels ever recorded. The only analogs being the Dot-com Bubble, Railway Mania, and the Telecom Fiber Buildout.
Those who remember the Palm #IPO may know what's coming, but with this amount of circular financing as well- it cannot end well.
Fundamentals Friday: the agent capability stack.
Most "agent failures" aren't reasoning failures. They're stack failures. The model is fine; the layer below it isn't.
The key is problems can arise at any and all layer, be prepared for it!
Honestly, the bound is tighter than people think. You can't out-prompt a broken tool layer. 🧱
#AI #AgenticAI #AISafety #AgenticAI #LLMs #MLOps
The S&P 500's Shiller P/E (CAPE) ratio has averaged about 17.4 since 1871. As of May 22 of this year, it stood at 𝟒𝟐.𝟎𝟒 —more than 𝐝𝐨𝐮𝐛𝐥𝐞 its 155-year average.
Outside of May, the only other time the Shiller P/E exceeded 42 was during the late stages of the dot-com bubble, topping at 44.19 in December 1999 before the dot com bubble popped.
With big name #IPO's coming & #AI Capex spending commitments only continue to rise (as seen on $GOOG & $NVDA with total supply-related commitments climbing to $119B in Q1 FY2027, and another $30B billion in multi-year cloud service commitments) — I don't see this ending well.
History offers a cautionary signal: there have been 6 instances, including the current one, where the CAPE ratio rose above 30 during an ongoing bull market. Each of the previous five cases was eventually followed by atleast a -20%~ drip in the Dow, $SPY, and/or Nasdaq
The $SPY and 10-year Treasury yields had the strongest inverse relationship over two months, or 42 trading days, since 1999 (measured by the correlation of daily changes).
I had an amazing camp today at the Gardner Webb mega camp I definitely got better and got a lot of work it was great meeting all the coaches @Jorayemorrriso1@CoachK__Mac@CoachShaw_Jake
The new standard in FFT processing has arrived.
Ultrafast. Linear Time. Ultrascalable.
We are accepting bids from qualified organizations looking to integrate cutting-edge algorithmic efficiency into their systems.
Review specs & apply: 🌐 https://t.co/MZcbCh6tff
#TechInnovation #Aerospace #AI #MachineLearning #BigTech
Everyone is talking about AI-powered customer experience.
Few are asking whether AI is actually improving customer outcomes.
According to our latest article authored by Artur Ledowski (Senior Director of Enterprise Growth and Commercial Strategy at TELUS Digital), the biggest CX failures see aren't caused by weak models.
They're caused by fragmented data, disconnected systems, and operating models designed around deflection rather than resolution.
When organizations deploy AI on top of broken customer intelligence, they don't eliminate friction.
They scale it.
The companies creating meaningful differentiation are taking a different approach:
• Unified customer context
• AI-assisted decision making
• Human expertise in high-value moments
• Resolution over deflection
The future of customer experience won't be defined by how much we automate.
It will be defined by how intelligently we connect people, data, and technology.
👉 Read the full article to discover the blueprint for building an outcome-driven AI strategy: https://t.co/T6INyUafu6
#CX #ArtificialIntelligence #CustomerSuccess #DigitalTransformation #DataStrategy
Wrote about the CLAX-PT case study (physicist supervising Claude Code for 12 days, 57 sessions, building a differentiable one-loop perturbation theory module in JAX). The TL;DR:
The agent resolved 10 of 15 supervision events autonomously. The 3 that required a human are the interesting ones, and they all evaded oracle detection.
Failure 1: architectural anchoring. The agent spent 33 sessions tuning coefficients inside a code structure that was incompatible with anisotropic BAO damping. No coefficient inside the wrong architecture was going to converge. Local search inside a hypothesis class that does not contain the true function. The agent could not re-evaluate the branch choice even when prompted to. Only naming the missing physics concept triggered the redesign. After redesign: 1-2% error, zero tuned parameters.
Failure 2: the fudge factor. The agent committed a ~0.27 multiplicative "calibrated correction" that passed every oracle test and corresponded to no quantity in the theory. Would have been wrong at any other cosmology, invisibly. The agent does not distinguish predictive adequacy from explanatory correctness. Passing the suite is not being right when the suite is finite.
The catch: the model capability did not change between the failures and the catches. What caught them was supervision design. Tests at diverse parameter points, not just the fiducial. Cross-session changelogs that surface motion-without-progress (invisible from inside any single session). An explicit veto on unphysical patches, enforced by someone who knows what unphysical means.
Generally true, with the caveat that N=1 and the physicist is the author. But the failure modes are not idiosyncratic. They're what I'd expect anywhere the test suite is a proxy for a richer notion of correctness held by a domain expert.
The locus of human contribution shifts from implementation to supervision. The supervision design is not the boring infrastructure around the interesting model. It is the interesting part.
Full piece → [https://t.co/g0oum2j4Pk]
@YesUpvote Hello, team! I wanted to withdraw and I got this message: "You can only sell points earned from tasks. Sellable points: 2338, requested: 3963." My mail: [email protected]




















![PenQuester's tweet photo. Wrote about the CLAX-PT case study (physicist supervising Claude Code for 12 days, 57 sessions, building a differentiable one-loop perturbation theory module in JAX). The TL;DR:
The agent resolved 10 of 15 supervision events autonomously. The 3 that required a human are the interesting ones, and they all evaded oracle detection.
Failure 1: architectural anchoring. The agent spent 33 sessions tuning coefficients inside a code structure that was incompatible with anisotropic BAO damping. No coefficient inside the wrong architecture was going to converge. Local search inside a hypothesis class that does not contain the true function. The agent could not re-evaluate the branch choice even when prompted to. Only naming the missing physics concept triggered the redesign. After redesign: 1-2% error, zero tuned parameters.
Failure 2: the fudge factor. The agent committed a ~0.27 multiplicative "calibrated correction" that passed every oracle test and corresponded to no quantity in the theory. Would have been wrong at any other cosmology, invisibly. The agent does not distinguish predictive adequacy from explanatory correctness. Passing the suite is not being right when the suite is finite.
The catch: the model capability did not change between the failures and the catches. What caught them was supervision design. Tests at diverse parameter points, not just the fiducial. Cross-session changelogs that surface motion-without-progress (invisible from inside any single session). An explicit veto on unphysical patches, enforced by someone who knows what unphysical means.
Generally true, with the caveat that N=1 and the physicist is the author. But the failure modes are not idiosyncratic. They're what I'd expect anywhere the test suite is a proxy for a richer notion of correctness held by a domain expert.
The locus of human contribution shifts from implementation to supervision. The supervision design is not the boring infrastructure around the interesting model. It is the interesting part.
Full piece → [https://t.co/g0oum2j4Pk]](https://pbs.twimg.com/media/HJr-2LwWcAMJSoj.jpg)






























