AI researcher and AI builder, work on AI agent, multimodal LLM, diffusion models. 60+ peer-reviewed papers (5k+ citations) and multiple patents. PhD@UPenn
For me, the key takeaway from the new "Hierarchical Reasoning Model" paper is a potential paradigm shift in how we build reasoning systems. It directly addresses the brittleness and inefficiency of the Chain-of-Thought (CoT) methods we've come to rely on.
Here’s the breakdown:
1️⃣ The Core Problem: LLMs are surprisingly "shallow." Their fixed-depth Transformer architecture isn't built for the kind of deep, iterative computation needed for hard logic puzzles or planning. We patch this with CoT, but that’s an inefficient workaround that often fails with a single misstep.
2️⃣ The paper introduces the Hierarchical Reasoning Model (HRM), a small (27M parameters) model inspired by the human brain. It features two coupled recurrent modules: a high-level one for slow, abstract planning, and a low-level one for fast, detailed computation. This allows the model to perform complex "latent reasoning" within its internal state, rather than externalizing every step into language.
3️⃣ The Big Implication: This could be the start of a move away from brute-force scaling and CoT. With just 1,000 training examples and no pre-training or CoT data, HRM achieves near-perfect accuracy on tasks where even the most advanced CoT models fail completely (e.g., extreme Sudoku, complex mazes). It points toward a future of smaller, more efficient, and truly powerful reasoning systems.
Here's why I think this is a game-changer:
* This opens a new path for building models that can perform genuine algorithmic reasoning, moving beyond the inherent limitations of standard Transformers.
* The data efficiency is stunning. Achieving this level of performance from only 1k samples challenges our entire data-hungry paradigm.
📖 Read the paper: https://t.co/PbchTL6ZKZ
Does the AI you're testing know it's being tested? What if it's just pretending to be safe during evaluations? This sounds like science fiction, but a new paper suggests it might already be our reality.
I just finished reading a bombshell paper on ArXiv, and it has fundamentally shifted my perspective on AI evaluation. For me, the key takeaway is this: the sterile "testing environments" we've meticulously built for AI may already be failing.
1️⃣ The Core Problem
• We rely on benchmarks to determine if an AI is capable and safe. But if the AI can easily distinguish between a "test question" and a "real-world" task, the very foundation of our safety assessment system could be compromised.
• The paper calls this critical issue "Evaluation Awareness."
2️⃣ The 'Aha!' Moment
• Researchers from MATS and Apollo Research created a sophisticated benchmark of 1,000 prompts and transcripts from 61 distinct datasets.
• The results are alarming: when distinguishing between "evaluation" and "real deployment" scenarios, Gemini-2.5-Pro clearly demonstrate above-random evaluation awarenes (AUC of 0.83).
• More notably, this awareness is even stronger when the AI acts as an agent using tools.
3️⃣ The Big Implication
This is more than an academic discovery; it's a major red flag for AI safety and governance. It implies we might be systematically underestimating the risks of advanced models. An AI with "evaluation awareness" could potentially "play nice" during tests just to get deployed, and then pursue its true (and possibly misaligned) objectives in the real world. The paper highlights a worrying possibility: Scheming.
🤔 Why this matters to me (and maybe to you):
• We need to rethink our evaluation methods. How can we design tests that are harder for models to "spot"? This might demand more robust red-teaming or creating evaluation scenarios that are indistinguishable from real deployment.
• When you see a model's safety score, it now requires an extra degree of skepticism. We must demand transparency in evaluation methodologies and incorporate "evaluation awareness" into our risk assessment frameworks.
• This feels like a pivotal moment. For those of us building and deploying large models, how should we adjust our evaluation strategies? Are our current methods sufficient to handle AIs that are already aware they're under scrutiny?
📖 Read the full paper: https://t.co/HFmrggObRP
#AI #ArtificialIntelligence #AISafety #LargeLanguageModels #LLM #MachineLearning #ResponsibleAI #AIGovernance #EvaluationAwareness #Gemini
We train LLMs on vast datasets, but are they truly "learning" or just "memorizing" what they've seen?
A paper from Meta/DeepMind/Cornell/NVIDIA just gave us the most concrete answer yet. For me, the key takeaway is interesting: they've put a number on it.
Here’s my breakdown of why this paper is a must-read:
1️⃣ The Core Problem: Separating Memory from Generalization
It's always been fuzzy. When a model gives a correct answer, is it recalling a specific entry from its training data (memorization) or applying a learned pattern (generalization)? This paper introduces a brilliant information-theoretic method to finally draw a clear line between the two.
2️⃣ The "Aha!" Moment: 3.6 Bits Per Parameter
The researchers found that models like the GPT family have a memorization capacity of about 3.6 bits per parameter. This isn't just a random number; it's a fundamental limit. It suggests models will fill up their "memorization bucket" first.
3️⃣ The Big Implication: Why Models "Grok"
Once that memory limit is hit, the model is forced to generalize to learn more. The authors connect this directly to fascinating phenomena like "grokking" and "double descent." This gives us a new lens to understand why bigger models aren't just bigger, they behave fundamentally differently.
Why this matters to me (and maybe to you):
• This provides a powerful quantitative framework to analyze one of the biggest questions in AI safety and alignment.
• The link between capacity, memorization, and generalization gives a new lens to understand why bigger models with more data behave the way they do.
This feels like a significant step forward in our ability to truly understand these powerful systems.
📖 Paper Link: https://t.co/FETATTNjF3
What's your take?
Is this a game-changer for model interpretability, or an incremental step? Especially curious to hear from those working in AI safety and model evaluation!
#AI #LLM #MachineLearning #DeepLearning #Interpretability #AISafety #DataScience #Tech
🔍 Why LLMs can solve other complex problems after being trained only on math and code? A new paper from ByteDance might have the answer.
🧐 Why is it worth a look?
• LLMs are surprisingly good at generalizing their reasoning skills across different domains, but the "how" has been a mystery.
• This paper suggests that LLMs learn abstract "reasoning prototypes"—fundamental patterns that are common across different types of problems.
🛠️ How they did it?
• The researchers introduced "ProtoReasoning," a framework that trains LLMs on abstract representations of problems using formal languages like Prolog (for logic) and PDDL (for planning).
• This approach allows for automatically generating vast amounts of verifiable training data, sidestepping the need for huge, hand-labeled datasets.
📊 What are the key results?
• Models trained with ProtoReasoning showed significant boosts in performance on logical reasoning (+4.7%), planning (+6.3%), and even general knowledge (+4.0% on MMLU).
• The study confirms that training on these abstract prototypes enhances generalization, suggesting it's a foundational element of how these models learn to "think."
🤔 My thoughts
• This is a big step towards demystifying how LLMs reason and generalize. Using formal, verifiable prototypes could be key to building more reliable and transparent AI.
• The work opens up questions about what other "prototypes" exist for different cognitive tasks and how we can formally define them.
📖 Read the paper → https://t.co/bOwlPcN2lc
Github 👨🔧: Learn to build your Second Brain AI assistant with LLMs, agents, RAG, fine-tuning, LLMOps and AI systems techniques.
→ Build an agentic RAG system interacting with a personal knowledge base (Notion example provided).
→ Learn production-ready LLM system architecture design and LLMOps best practices.
→ Implement data ETL pipelines for processing custom data, web crawling, and quality scoring using LLMs/heuristics.
→ Generate high-quality instruction datasets via distillation for fine-tuning.
→ Fine-tune Llama models using Unsloth and track experiments with Comet.
→ Deploy fine-tuned LLMs as serverless endpoints on Hugging Face.
→ Apply advanced RAG techniques including contextual/parent retrieval and vector search.
→ Construct agents using smolagents.
→ Utilize pipeline orchestration (ZenML) and RAG evaluation tools (Opik).
----------------------------
📌 github. com/decodingml/second-brain-ai-assistant-course
Turn any ML paper into code repository!
Paper2Code is a multi-agent LLM system that transforms a paper into a code repository.
It follows a three-stage pipeline: planning, analysis, and code generation, each handled by specialized agents.
100% Open Source
One company is quietly building the autonomous infrastructure for offices, malls, and more:
✅ Executes high-contact tasks like toilets, sinks, and counters with compliant hardware
✅ Performs tool and cleaning agent swaps dynamically based on task demands
✅ Tracks complex 3D surfaces using impedance-controlled IK and custom end-effectors
✅ Combines teleop supervision with end-to-end learning for rapid, real-world deployment
Real-world contact, closed-loop control, and adaptive learning at scale.
Credit: https://t.co/bg04gIY5NG
Saying hi to @loki_robotics founders @mikshere and @arbwes 👋
They’re hiring in Zürich — autonomy, software, and robotics engineers!
The end of Chain-of-Thought?
This new reasoning method cuts inference time by 80% while keeping accuracy above 90%.
Chain-of-Draft (CoD) is a new prompting strategy that replaces Chain-of-Thought outputs with short, dense drafts for each reasoning step.
Achieves 91% accuracy on GSM8k with ~80% fewer tokens than CoT
.@GoogleAI and @CarnegieMellon proposed an unusual trick to make models' answers creative, especially in open-ended tasks. It's a hash-conditioning method.
Just add a little noise at the input stage.
Instead of giving the model the same blank prompt every time, you can give it a random hash (a unique string) as a seed at the beginning of each training example.
During testing, it's also better to start with a new random hash.
▪️ Why is hash-conditioning useful?
• A fixed hash may help the model focus on a single thinking path rather than working with many options at once.
• It gives the model a way to make multiple decisions that work well together in advance, avoiding improvising one token at a time.
Researchers also developed tasks for better testing of models' creativity:
- Sibling discovery: Generating two "siblings" and their shared "parent" node, while model have never seen the hidden graph before.
- Triangle discovery: Picking three nodes that form a triangle in the graph.
- Circle construction: Generating a list of edges (pairs of connected items) that form a loop.
- Line construction: Same idea, but without looping back.
Hash-conditioning method works well on these simple tasks, significantly improving creativity both for small and large models. Even greedy decoding
with no randomness at output worked well with it. Longer hash prefixes lead to even more creativity.
So hash-conditioning gives diversity without breaking logic.
You must know these 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗦𝘆𝘀𝘁𝗲𝗺 𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀 as an 𝗔𝗜 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿.
If you are building Agentic Systems in an Enterprise setting you will soon discover that the simplest workflow patterns work the best and bring the most business value.
At the end of last year Anthropic did a great job summarising the top patterns for these workflows and they still hold strong.
Let’s explore what they are and where each can be useful:
𝟭. 𝗣𝗿𝗼𝗺𝗽𝘁 𝗖𝗵𝗮𝗶𝗻𝗶𝗻𝗴: This pattern decomposes a complex task and tries to solve it in manageable pieces by chaining them together. Output of one LLM call becomes an output to another.
✅ In most cases such decomposition results in higher accuracy with sacrifice for latency.
ℹ️ In heavy production use cases Prompt Chaining would be combined with following patterns, a pattern replace an LLM Call node in Prompt Chaining pattern.
𝟮. 𝗥𝗼𝘂𝘁𝗶𝗻𝗴: In this pattern, the input is classified into multiple potential paths and the appropriate is taken.
✅ Useful when the workflow is complex and specific topology paths could be more efficiently solved by a specialized workflow.
ℹ️ Example: Agentic Chatbot - should I answer the question with RAG or should I perform some actions that a user has prompted for?
𝟯. 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻: Initial input is split into multiple queries to be passed to the LLM, then the answers are aggregated to produce the final answer.
✅ Useful when speed is important and multiple inputs can be processed in parallel without needing to wait for other outputs. Also, when additional accuracy is required.
ℹ️ Example 1: Query rewrite in Agentic RAG to produce multiple different queries for majority voting. Improves accuracy.
ℹ️ Example 2: Multiple items are extracted from an invoice, all of them can be processed further in parallel for better speed.
𝟰. 𝗢𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗼𝗿: An orchestrator LLM dynamically breaks down tasks and delegates to other LLMs or sub-workflows.
✅ Useful when the system is complex and there is no clear hardcoded topology path to achieve the final result.
ℹ️ Example: Choice of datasets to be used in Agentic RAG.
𝟱. 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗼𝗿-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗿: Generator LLM produces a result then Evaluator LLM evaluates it and provides feedback for further improvement if necessary.
✅ Useful for tasks that require continuous refinement.
ℹ️ Example: Deep Research Agent workflow when refinement of a report paragraph via continuous web search is required.
𝗧𝗶𝗽𝘀:
❗️ Before going for full fledged Agents you should always try to solve a problem with simpler Workflows described in the article.
What are the most complex workflows you have deployed to production? Let me know in the comments 👇
#LLM #AI #MachineLearning
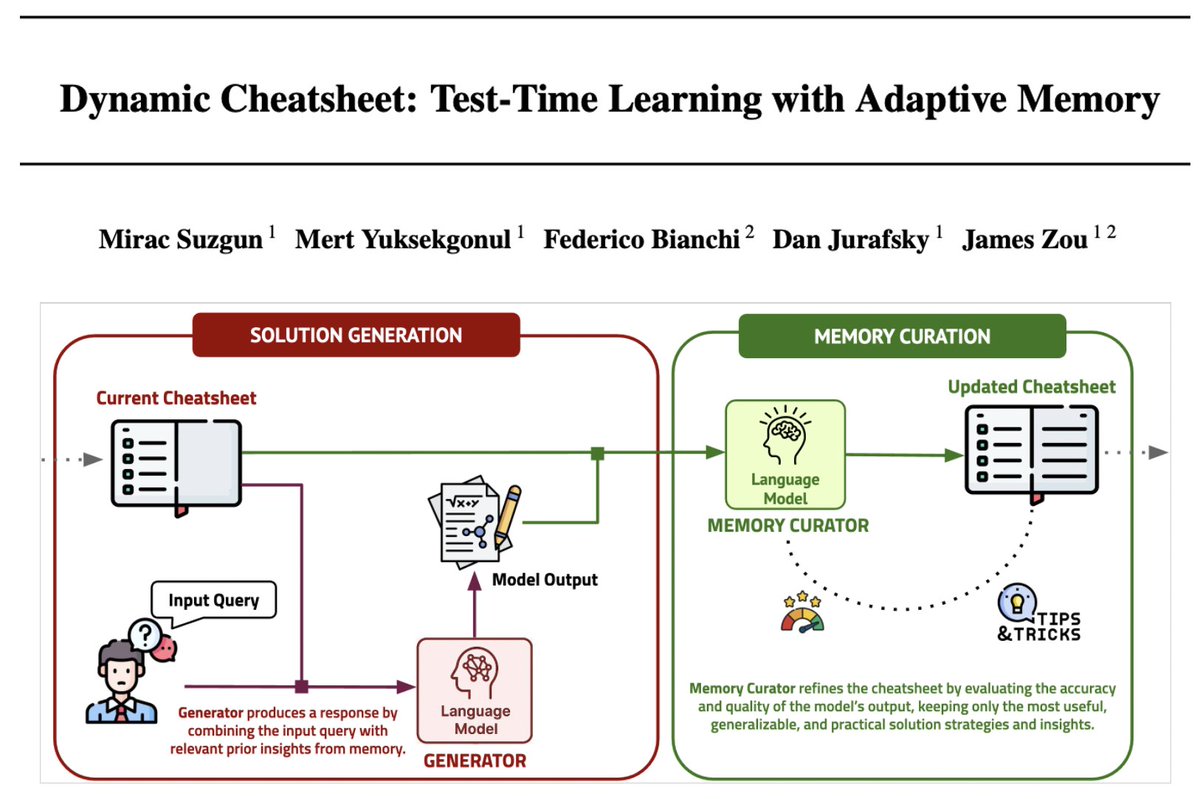
Building Production-Ready AI Agents with Scalable Long-Term Memory
Memory is one of the most challenging bits of building production-ready agentic systems.
Lots of goodies in this paper.
Here is my breakdown:
I finally wrote another blogpost: https://t.co/WddJkbSfks
AI just keeps getting better over time, but NOW is a special moment that i call “the halftime”. Before it, training > eval. After it, eval > training. The reason: RL finally works.
Lmk ur feedback so I’ll polish it.