Read a review of @jmichaelbatty's recently published book, The Computable City. The review from @APA_Planning says the book is 'accessible to a broad audience and serves as a particularly valuable reference for scholars'. #JAPAplanning
https://t.co/diUdlhg8Q1
CrowdStrike effectively bricked windows, Mac and Linux today.
Windows machines won’t boot, and Mac and Linux work is abandoned because all their users are on twitter making memes.
Incredible work.
🗓Hoy, Día Mundial del Autismo, recordamos que la diversidad y el valor de las personas con autismo están cerca de nosotros en cada sonrisa, en cada desafío superado.
🔹️Por una sociedad más inclusiva y respetuosa. #AutismoCercaDeTi
🩵 Rematamos o #FIGaE_2024 en Bruxelas este fin de semana! Grazas a todas as persoas asistentes e poñentes, pola vosa participación e aportacións tan interesantes. E á @axenciaGAIN polo seu apoio e co-organización, así como á @EmbEspBelgica A ciencia galega ten moito que decir!
'Habelas,Hailas: investigacións galegas en Europa' falamos de IA,bacterias púrpuras como fonte de proteínas, coanoflaxelados,enx. de tecidos ao estilo Tony Stark,antimateria e agora para finalizar o #FIGaE_2024 o bonus track co director do @IncipitCSIC Felipe Criado.
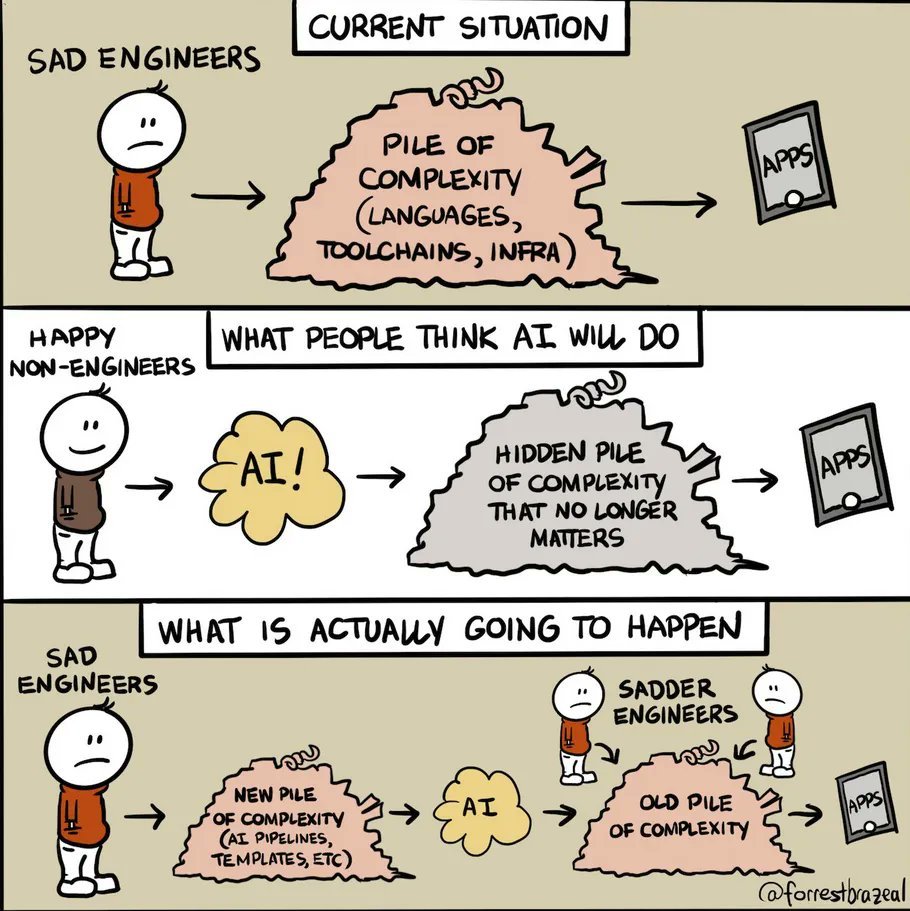
I suspect many AI projects will end up in ruin because its developers are just muddling around getting their dopamine hits from the deluge of micro-events about AI. They focus only on the trees but can't see the forest!
The LVM (large vision model) revolution is coming a little after the LLM (large language model) one, and will transform how we process images. But there’s an important difference between LVMs and LLMs:
- Internet text is similar enough to proprietary text documents that an LLM trained on internet text can understand your documents.
- But internet images – such as Instagram pictures – contain a lot of pictures of people, pets, landmarks, and everyday objects. Many practical vision applications (manufacturing, aerial imagery, life sciences, etc.) use images that look nothing like most internet images. So a generic LVM trained on internet images fares poorly at picking out the most salient features of images in many specialized domains.
That’s why domain specific LVMs – ones adapted to images of a particular domain (such as semiconductor manufacturing, or pathology) – do much better. At @LandingAI , by using ~100K unlabeled images to adapt an LVM to a specific domain, we see significantly improved results, for example where only 10-30% as much labeled data is now needed to achieve a certain level of performance.
For companies with large sets of images that look nothing like internet images, I think domain specific LVMs can be a way to unlock considerable value from their data. Dan Maloney and I share more details in the video.
(1/2)
Check out 𝐌𝐞𝐬𝐡𝐆𝐏𝐓!
MeshGPT generates triangle meshes by autoregressively sampling from a transformer model that produces tokens from a learned geometric vocabulary.
As a result, we obtain clean and compact meshes :)
https://t.co/ynrf0qjYVF
https://t.co/rQe7ipP15t