@tunguz In politics you only need the wrong person at the wrong time to sink a ship. If the reporting we have heard is right from
what happened, well, the person who decided to share to Amazon’s CEO about the supposed “jailbreak” might be thinking a lot about this too.
NEW: Inside the 24-hrs before WH slapped export controls on Anthropic
- Last Thursday, Amazon CEO Andy Jassy raised concerns about Fable jailbreak to Trump admin
- Friday AM, Sean Cairncross, Bessent, Susie etc. held WH call to discuss
- Then White House started reaching out to Anthropic to speak with Dario Amodei, who was at a wellness retreat.
- When Amodei was finally available past 1pm, he had three tense phone calls with a combo of ppl including Cairncross, Bessent, Lutnick, Kessler, Will Scharf, Richard Walters, and Walker Barrett.
-Amodei tried to clear up what he assumed was a misunderstanding. He defended the guardrails and distinguished between universal and non-universal jailbreak
- Cairncross and Bessent were unmoved and asked Amodei to take down Fable and work with the admin to fix the vulnerabilities. (A WH official said Amazon’s findings were run past the NSA and they felt they had “proof.”)
- Amodei asked for more time and info, but he made no commitments to pull the model
- Bessent told Amodei directly at one point that he was making a “bad decision”
- By Friday evening, the Trump admin imposed its export controls.
- “Export controls were a last resort after begging them for hours to work with us,” senior WH official said.
W/ @cheyennehaslett
https://t.co/0Rwny9md3p
Anybody using Opus for red teaming since the early days knows this. If you
tried to go around the safeguards in Fable 5 you got caught early on due its long horizon capabilities. Opus 4.x it’s quite good if you really know what you are looking for.
As a person who has done a ton of red teaming and finding jailbreaks in oai and anthropic models, my guess is that Anthropic is actually correct about the jailbreak presenting no additional risk. So many people claim jailbreaks but the model actually hedged, output false info on purpose, or it’s like 10% functional.
At the end of the day, it’s all moot because 4.6-4.8 can find critical vulnerabilities
@ianbremmer Being a bit of a devil’s advocate it’s probably safe because for a tiny number of highly educated Americans truly see its power. However, for adversaries it’s gift since their education and willingness to learn is bigger than what we have. 🤷🏻♂️
In AI most people are still trying to use old maps on a new territory.
Throw the maps away. It's time to draw new ones. The only way you can do it is walking the land.
I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
Guess what happens next? We should expect an OSS model with capabilities equal or greater than Mythos in the coming days or months. This action only puts companies, systems and governments at higher risk today with this decision.
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: https://t.co/bwn0sximKZ
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
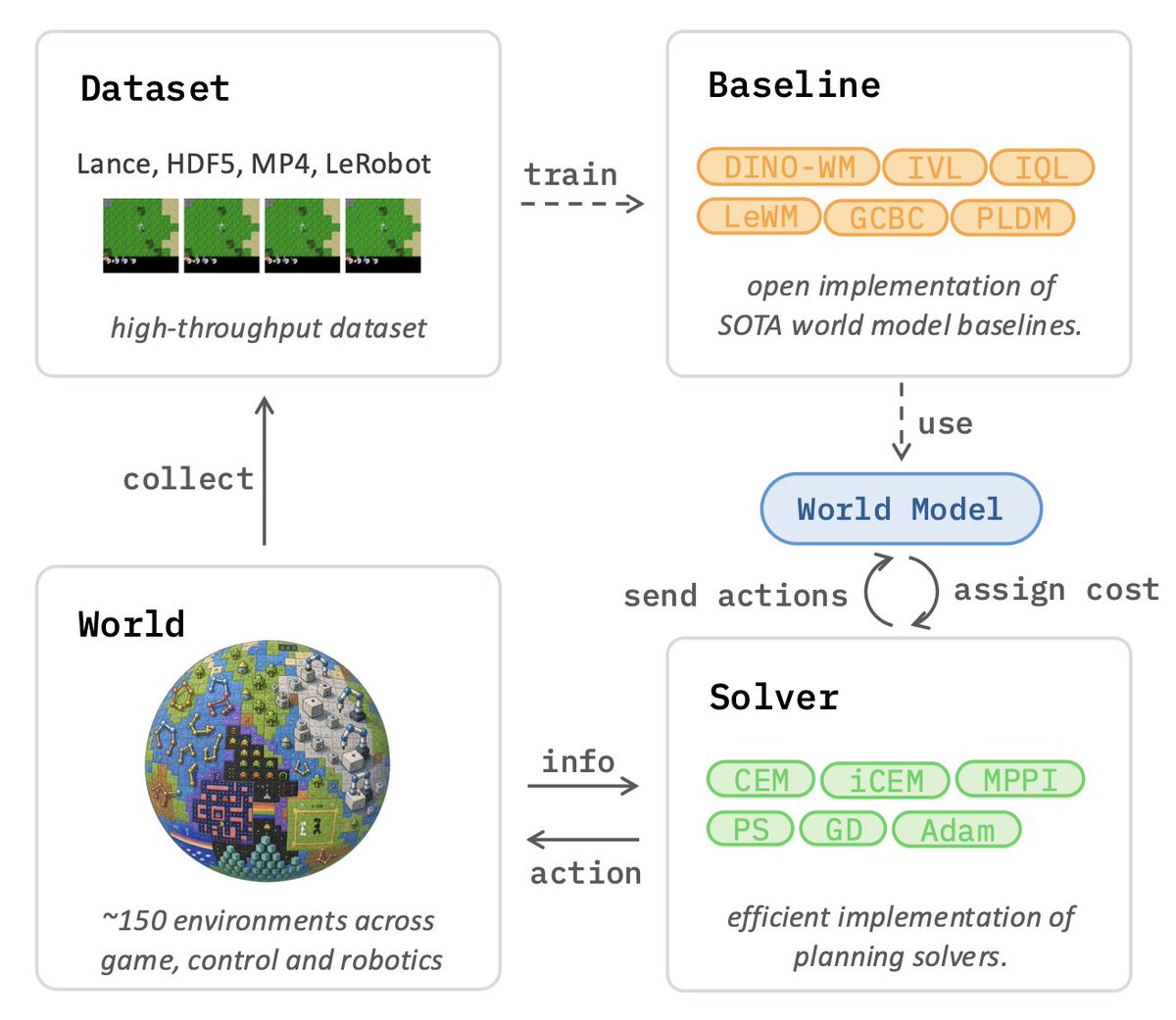
Most work still relies on MP4 videos ... creating a major bottleneck that kills GPU utilization and training throughput.
Not anymore.
We teamed up with the incredible @lancedb team to build blazing-fast data loading with native @huggingface bucket streaming support! ⚡
Would you like to join the research effort on JEPA and World Models easily?
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: https://t.co/gnxGvens5A
I’ve been saying this for months: we are all running into the same patterns and is a shame that our progress is limited to our own repos or laptops. I’ve been doing this for the last 2 months and I’m glad to see Anthropic making this a proper feature.
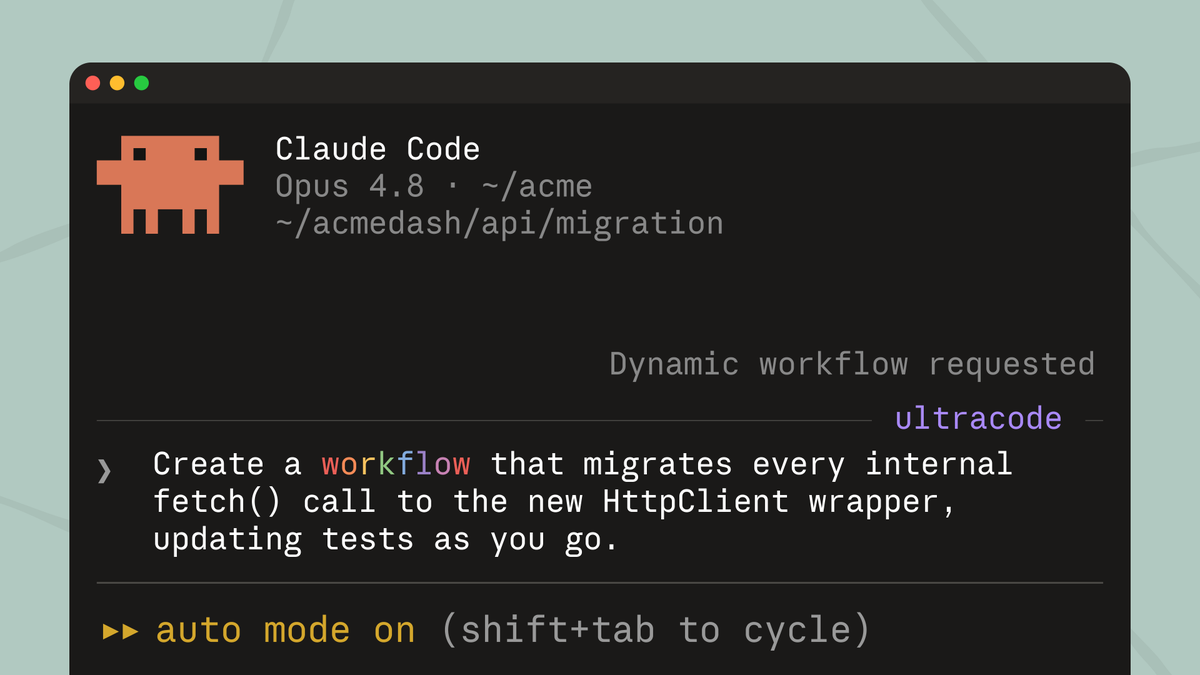
New in Claude Code (research preview): dynamic workflows.
Claude writes an orchestration script on the fly, then spins up a large fleet of coordinated subagents in parallel to take on your most complex tasks.
Use the word "workflow" in a prompt to get started.
@bcherny So can i remove all my introspection rules now? I feel that asking Opus 4.7 to “don’t rush” “double check, when you say is done it must be done for real after running unit tests, etc” was a waste of tokens.
I feel that I should release my framework after this or at least part of it. The convergence of what we are discovering what models are capable to introspect about their own work is remarkable.
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
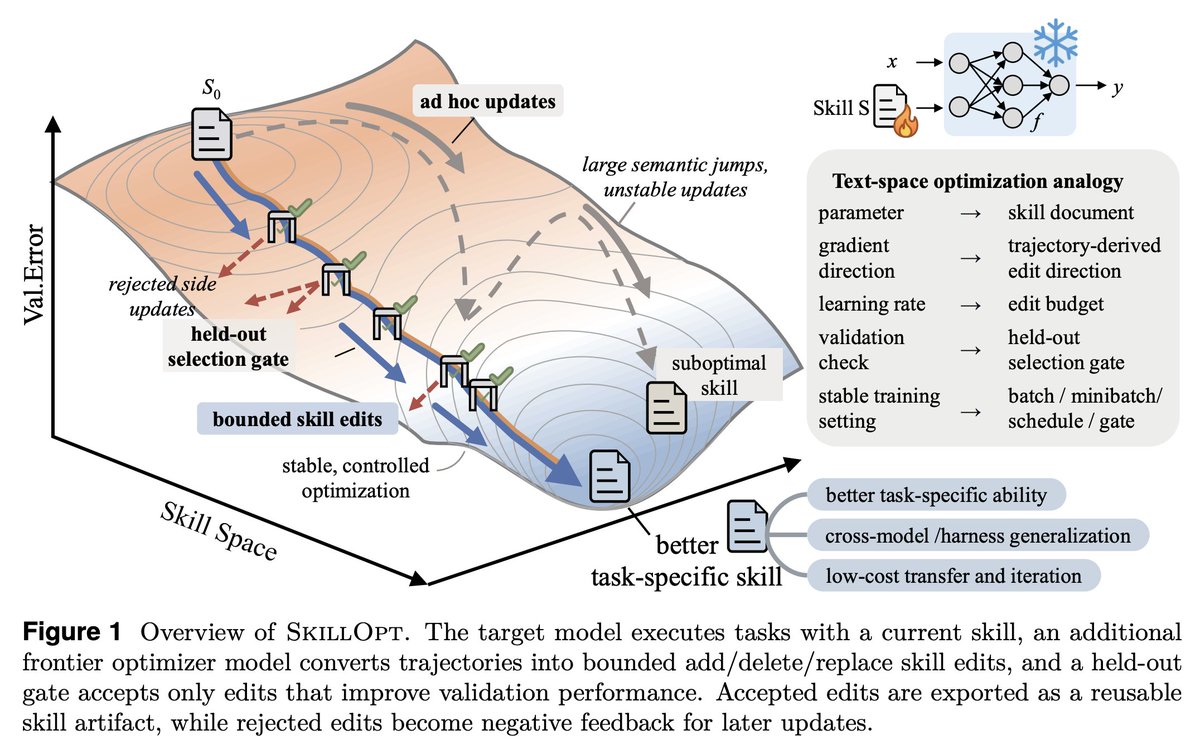
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
CEOs are uniquely prone to AI psychosis because they’re sufficiently distant from the last mile of work that still has to happen to generate most value with AI.
So when they play with AI, they see the happy path results, often not considering the next 10 or 20 things that have to happen to get sustainable results from agents.
“Look I made this awesome product prototype”. Yes but you didn’t have to review the code before it went into production and fix a bunch of issues.
“Look I generated a contract”. Yes but you didn’t verify all the terms before it goes out to the counterparty and didn’t have to wire up all the past contracts to work with.
The best thing you can do as a CEO is to use AI a *ton* to figure out the real implications of agents in the enterprise, and come out the other side with an appreciation for both the upside and the real work that goes into them.