🚀 Can terminal agents handle real-world human workflows?
We introduce TerminalWorld, a scalable benchmark that reverse-engineers high-quality terminal tasks from real human recordings 🔴REC.
📊 From 80,870 recordings → 1,530 automatically validated tasks (200 human-verified), with ground-truth human solutions, Docker environments, and test suites.
🌍 Covers 18 real-world categories, e.g., 🐳 container orchestration, 🔁 CI/CD, ☁️ cloud infrastructure, with 1,280 unique tools/commands.
🧪 We evaluated frontier LLMs including Claude Opus 4.7, GPT-5.5, and Gemini 3.1 Pro. Even the best reaches only 62.5% pass rate.
🔍 Interesting finding: agents often solve tasks using strategies and tools very different from humans.
🔥 Actively updating TerminalWorld. Feedback welcome!
Paper: https://t.co/BxvLJxDp0y
Code: https://t.co/hc25swXYDu
Dataset: https://t.co/FUUzuJA2OF
🚀 HerAgent: Built by Her, to Rethink Success in Codebase Runnability
𝗛𝗮𝗽𝗽𝘆 𝘄𝗼𝗺𝗲𝗻'𝘀 𝗱𝗮𝘆!
👩💻 A Breakthrough by an All-Female Team As we release this on International Women's Day, we are proud to highlight that HerAgent is the work of an all-female team. This project stands as a testament to the exceptional contributions of women in hard-core AI and Software Engineering. We are not just participating in the revolution of autonomous development—we are leading it.
😫Tired of codebases that clone successfully but fail to execute?Exhausted by the endless battle with dependencies, environments, and build configurations?
Meet HerAgent 👇
It’s not just another Code Agent—it’s an Environment Setup Agent, to get you out of dependency hell. Current autonomous agents often fail because they rely on shallow signals. HerAgent is the first agent designed to achieve full Runnability—ensuring real-world projects actually execute.
🔧 Key Innovations:
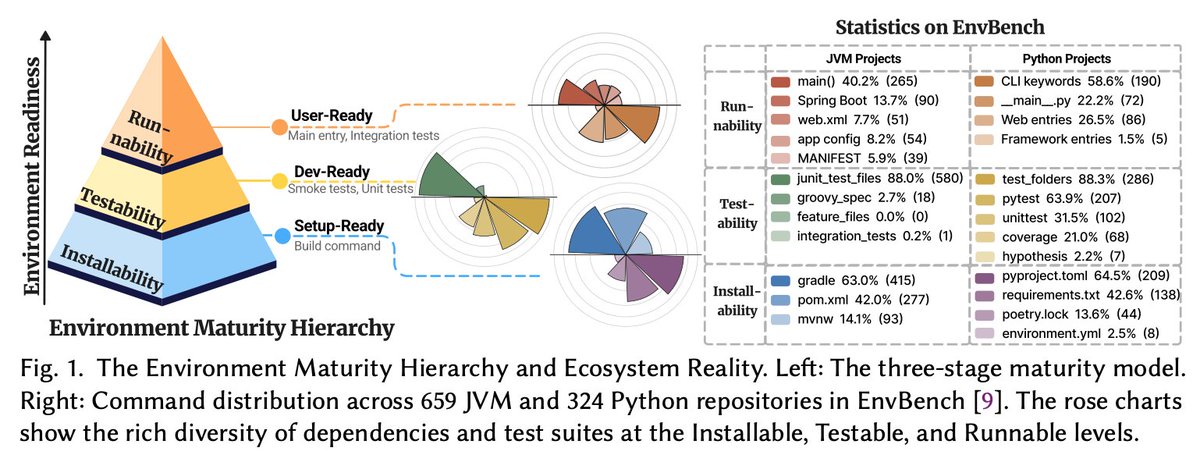
Environment Maturity Hierarchy: We move beyond "Installable" and "Testable" states. If the main workflow doesn't run, the job isn't done.
Script-Centric Architecture: HerAgent generates a unified Global Bash Script. All dependency resolutions and error patches are accumulated in one place, preventing context loss.
Self-Healing Loop: It employs a continuous Execute → Analyze → Self-Repair cycle.
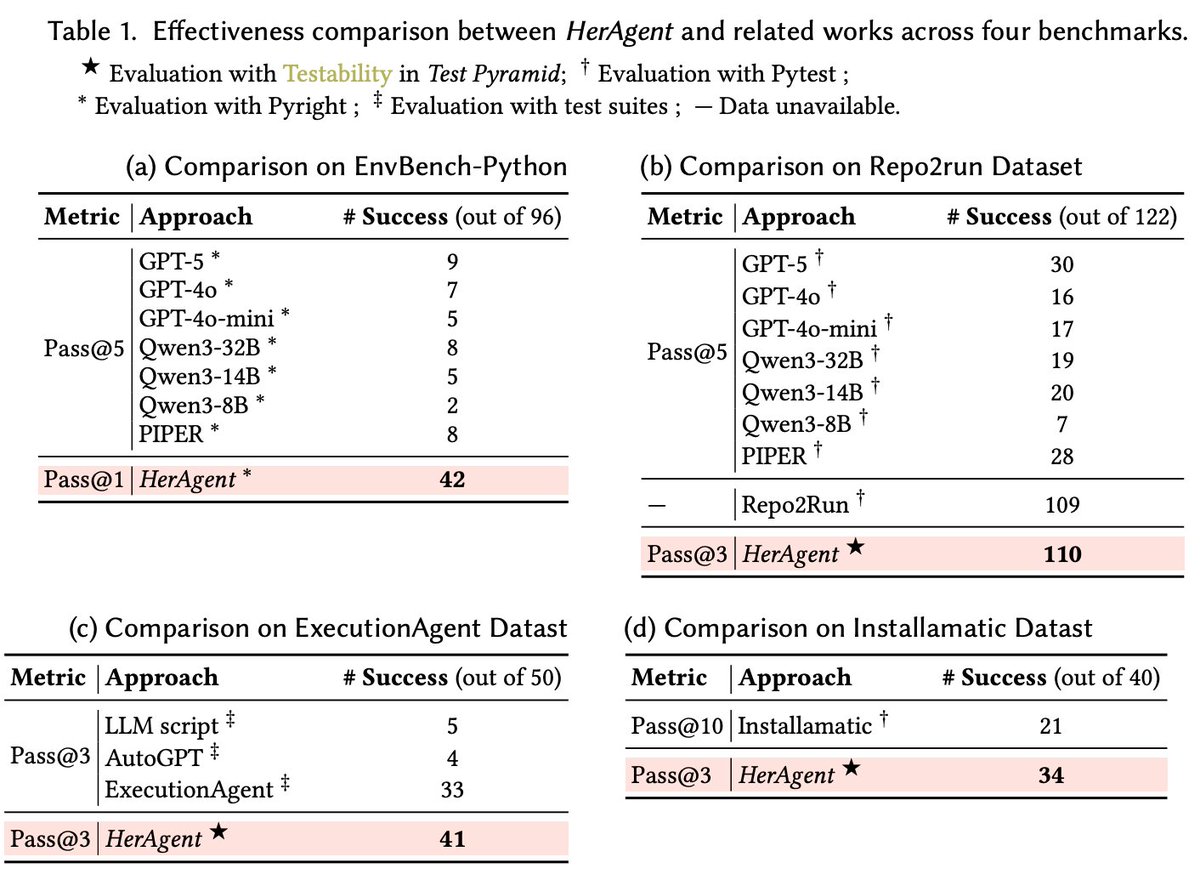
📊 Why It Matters: Achieving a 79.6% performance boost, HerAgent performs exceptionally well in the hardest edge cases (like brittle C/C++ repos). Before AI can write software, it must learn to make it run—and HerAgent is that first step.
📄 Paper 👉 https://t.co/cHW1mq0G1Y
💻 Code 👉 https://t.co/3pvGJhRcxj
#AI #Agent #SoftwareEngineering #WomenInTech #IWD2026
We just released ContextBench 🎉
A benchmark built to answer a question many repo-level evaluations still miss:
Do coding agents truly retrieve and use the right context, or do they just get lucky?👀✨
📊 Highlights
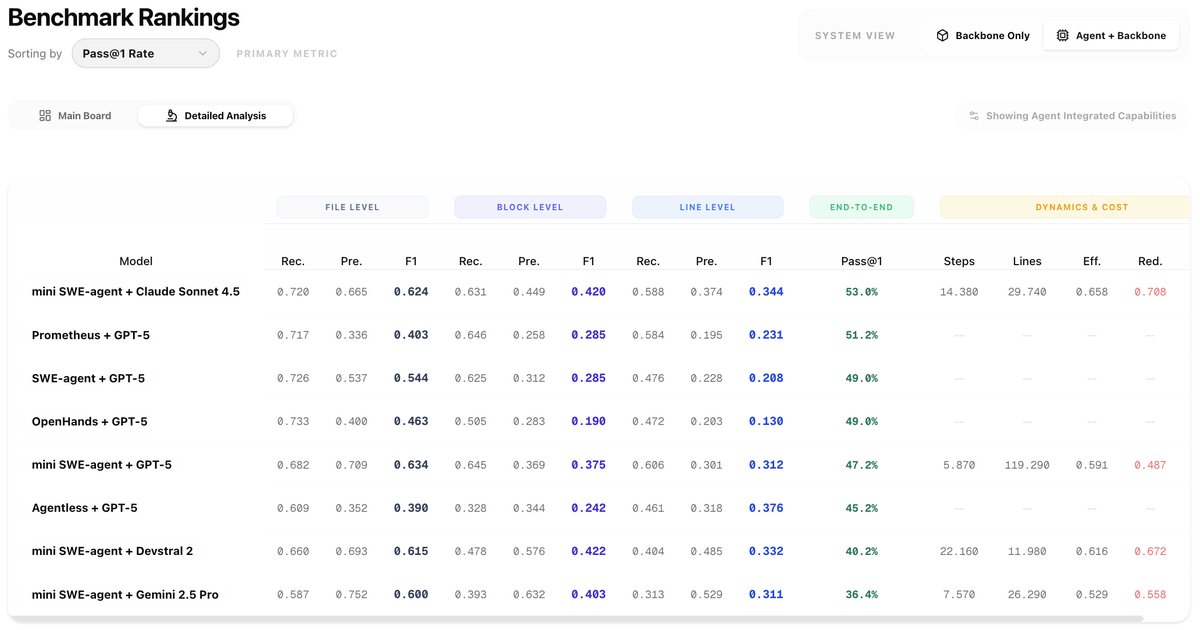
🧩 1,136 real-world issues across 66 repos and 8 languages
🧠 Expert verified gold contexts at file, block, and line levels
👣 Full trajectory tracking of what the agent actually reads and explores
📈 Metrics covering Recall, Precision, F1, Efficiency, and Usage Drop
🔍 Key Findings
1️⃣ Complex agentic scaffolds do not improve context retrieval quality 😅
In many cases, they introduce over-engineering, echoing "The Bitter Lesson" in AI research
2️⃣ Many SOTA LLMs favor high recall over precision 📉
They retrieve more context, but also much more noise
3️⃣ Retrieved does not mean utilized ❗
Agents often inspect the right code but fail to incorporate it into the final patch
4️⃣ Retrieval strategies that are more balanced tend to achieve stronger Pass@1 while keeping compute cost reasonable ⚖️✨
🌐 Homepage 👉 https://t.co/4upNH9XDYi
📄 Paper 👉 https://t.co/xXPziAFins
💻 Code 👉 https://t.co/belNHEFfyi
🗂️ Dataset 👉 https://t.co/XaljqOdg4r
Here are some exciting updates from our EuniAI team!
Our latest version of Prometheus reached Top 1 on AWS’s new SWE-PolyBench multi-language benchmark 🥇
This benchmark is one of the most challenging evaluations for code agents, so we are really happy to see Prometheus perform strongly.
On SWE-bench Verified, Prometheus has also moved up to Top 6 among open-source systems 🏆
Our GitHub repo is now at 400+ stars, and the community keeps growing.
We iterate every day and will continue pushing Prometheus toward a more capable and reliable autonomous code agent 🤖
Thanks to everyone for following our work.
More improvements coming soon! 🚀✨
@The_Delysium ($AGI) is building a blockchain‑native collaboration network for agentic AI, featuring Lucy(https://t.co/5Tdswxpn4E) — an agentic operating system — and the YKILY Network (You Know I Love You) — a digital‑native financial layer for AI agents. Alongside leaders such as Microsoft, Google, and Nvidia, and supported by select top‑tier investors, Delysium delivers secure, scalable infrastructure to power autonomous agent ecosystems.
We’re excited to announce our partnership with @The_Delysium — together, we’re setting open, autonomous, multilingual, and cost-efficient standards for AI coding.
By bridging AI systems engineering with Web3 best practices — @LucyOSAI and the YKILY Network — we aim to make AI development more transparent, verifiable, and accessible for everyone.
We’re excited to announce our partnership with @The_Delysium — together, we’re setting open, autonomous, multilingual, and cost-efficient standards for AI coding.
By bridging AI systems engineering with Web3 best practices — @LucyOSAI and the YKILY Network — we aim to make AI development more transparent, verifiable, and accessible for everyone.
Delysium is proud to announce an official partnership with the @ucl Software Systems Engineering Team and Dr. He Ye from the Department of Computer Science, aiming to advance AI coding standards.
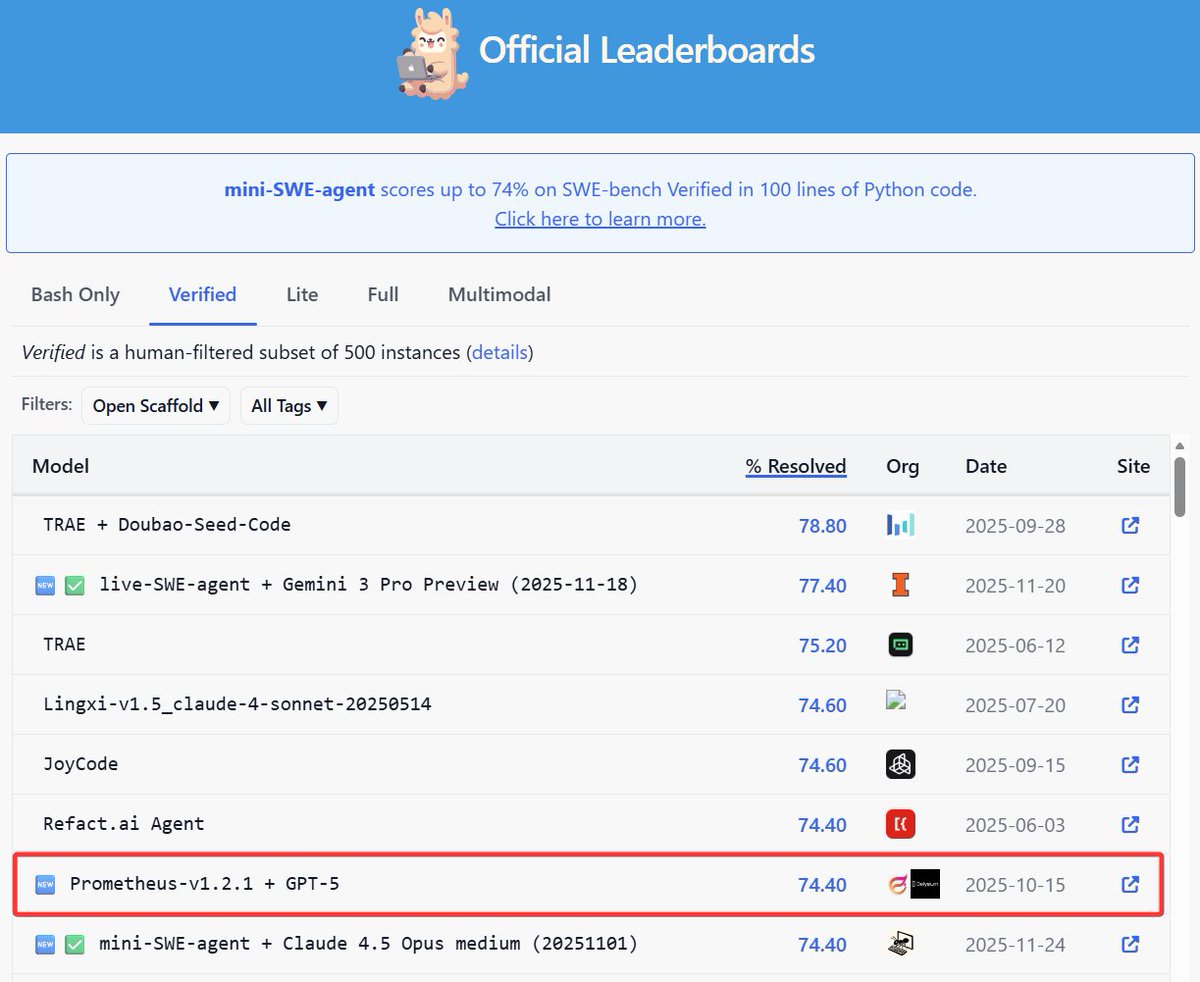
We have reached a significant milestone: the integration of GPT-5 + Pass@1 has been rigorously verified as ranked Top 2 on SWE-Bench (https://t.co/8SNgZ78PUK) on the first attempt.
Furthermore, our jointly developed open-source agent, Prometheus, has achieved a 71.2% resolution rate, ranked 8th globally—just behind @OpenHandsDev.
Together, we are setting open, autonomous, multilingual, and cost-efficient standards for AI coding — powering @LucyOSAI and the YKILY Network, and releasing open models to reduce LLM ops costs for everyone.
��� We’re excited to join #Neo4j #GraphSummit London 2025!
Inspiring day of learning & sharing 🇬🇧
Our mission aligns with graphs as the foundation of knowledge — powering Prometheus (GPT-5) to Top-5 on SWE-bench Verified.
#KnowledgeGraph #LLM #SWEbench #AI #AgenticAI #OpenSource
🚀 New milestone: Hermes hits 50% resolve rate on Terminal-Bench!
📊 Performance:
✅ 91.67% easy
⚡ 54.55% medium
🔥 20.83% hard
Now ranked #6 on the leaderboard, Hermes proves the power of iterative AI agents in complex terminal environments.
#LLM#Agents#AIResearch
🚀 Benchmark update 🚀
Prometheus + DeepSeek-Chat reached 35.33% resolve rate on SWE-bench Lite — achieving state-of-the-art performance in autonomous code agents.
This is just the beginning 👀
🧠 Athena Memory System Launched! 🧠
An innovative memory system purpose-built for autonomous code agents:
⚡️ Long-term learning & memory
⚡️ Deeper context retention
⚡️ Greater adaptability
Athena marks the next leap toward truly self-managing, intelligent code agents.
🧠 Prometheus keeps evolving.
With new integrations & features, we’re pushing the boundaries of what code agents can do:
•Context-rich problem solving
•Flexible workflows
•Real-world performance breakthroughs
🚀 Prometheus Major Update 🚀
Big leap for autonomous code agents:
🔗 MCP Integration for stronger context & multimodal interaction
🔧 Web Search + Custom Build Commands
📊 44% solve rate on SWE-bench Verified
The future of self-managing code starts now.