¿Las empresas usan a la IA como excusa para despidos masivos?
En el Ep. 48 de EurekAI analizamos la trampa laboral, la Orden Ejecutiva de EE.UU. y el panorama desde San Francisco.
Escucha el debate aquí:
https://t.co/hKI6D2Jmt3
¿El avance algorítmico destruye la diversidad cultural?
En el Ep. 47 de EurekAI analizamos el "AI backlash", la Encíclica 4.0 y el caso SpaceX.
Escucha el debate aquí: https://t.co/fKykqv3ifv
🚀 ¡Regresamos con el 2º Foro AI Experience – Voice AI! 🎙️
La Inteligencia Artificial ha evolucionado: ya no solo lee y escribe, ahora escucha y habla. Te invitamos a nuestra segunda edición del AI Experience en Foro @GBM_mx_ , esta vez dedicada totalmente al mundo del Voice AI.
Exploraremos cómo los LLMs se integran con sistemas de voz para potenciar tecnologías como Text-to-Speech, Speech-to-Text y Agentes de Voz en tiempo real.
Agenda del evento:
🔹 Intro a LLMs para Voz: José María Sarmiento Chávez (Sr. Staff Data Scientist, GBM) explicará el stack tecnológico detrás de las experiencias de voz modernas.
🔹 Arquitectura de un Agente de Voz: Edgar Zúñiga Aguilar (SDE IV, GBM) presentará una demo en vivo sobre sistemas de voz en tiempo real.
🔹 Keynote Speaker: Dante Tellez , PhD, líder global en IA y Datos (ex-Google, Apple, Chubb).
🍕🍻 Al finalizar, quédate al networking con pizza y chelas cortesía de la casa.
📅 Fecha: Miércoles, 28 de enero, 2026 🕔 Hora: 5:00 PM - 9:00 PM CST 📍 Lugar: Foro GBM, Santa Fe, CDMX
👉 Asegura tu lugar aquí: https://t.co/VbMMB6H7zD
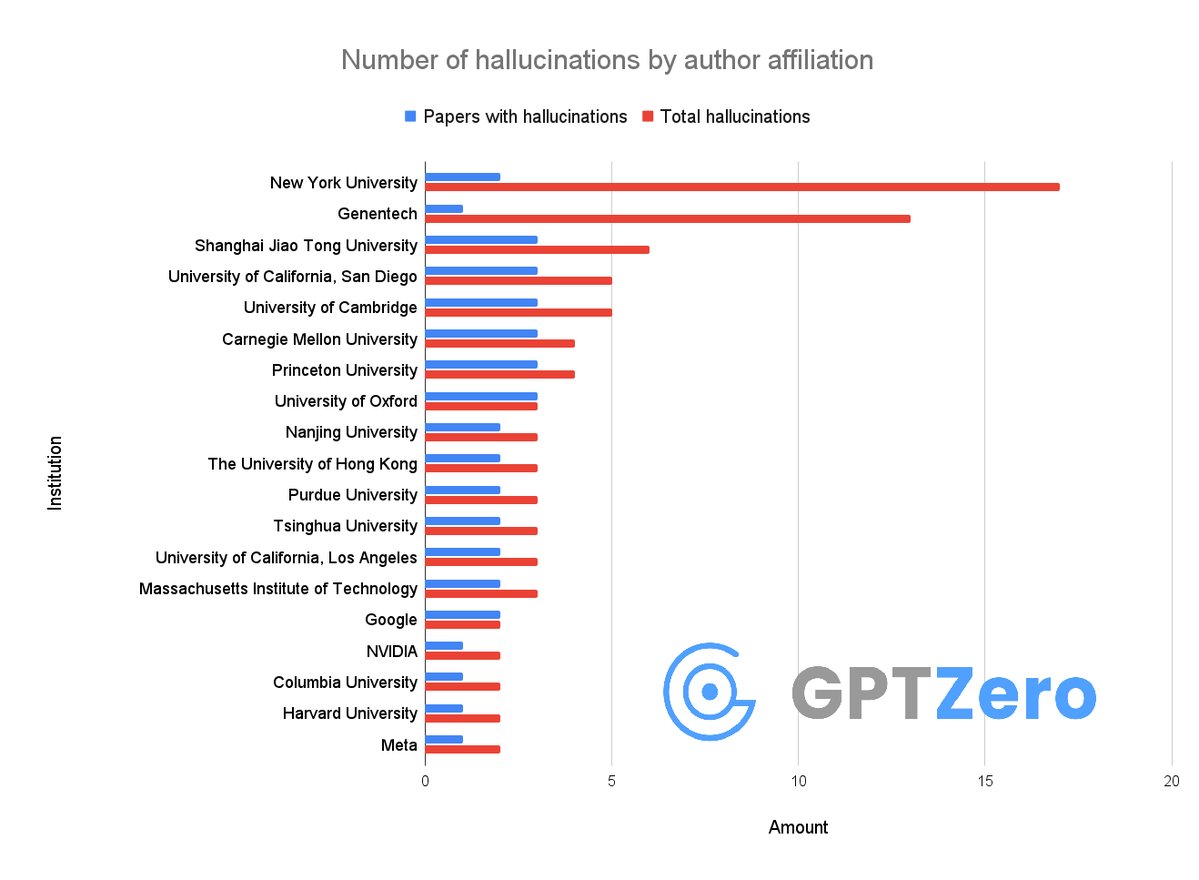
Okay so, we just found that over 50 papers published at @Neurips 2025 have AI hallucinations
I don't think people realize how bad the slop is right now
It's not just that researchers from @GoogleDeepMind, @Meta, @MIT, @Cambridge_Uni are using AI - they allowed LLMs to generate hallucinations in their papers and didn't notice at all.
It's insane that these made it through peer review👇
1/ I am truly honoured and completely delighted to have won the 2025 Berggruen Essay Prize (English), for my submission “The Mythology of Conscious AI” @berggruenInst@NoemaMag https://t.co/n3eXSRXkvk
Ayer arrancamos la clase de NLP (Procesamiento de Lenguaje Natural) con una premisa clara: Desmitificar la creencia de que los LLMs son la solución mágica para todo.
Es común ver empresas queriendo resolver tareas clásicas —como clasificación de texto o análisis de documentos masivos— a punta de LLMs.
¿El resultado?
❌ Sobreingeniería.
❌ Costos de inferencia disparados.
❌ Latencia innecesaria.
Muchas veces, la solución no es un modelo gigante de billones de parámetros, sino una arquitectura clásica bien implementada que resuelve el problema de forma más rápida, barata y sencilla.
🚨 Most people did not pay attention, but China's proposed law on AI anthropomorphism is one of the world's STRICTEST AI laws.
(and it helps demystify the idea that China does not regulate AI or that the only way to be a competitive player in the AI race is through radical deregulation or inattention to AI harms)
My full article below.
Genial. Pero como en todos los videos editados de robots o GenAI que nutren el hype, falta ver si estos modelos aguantan el flujo natural de una acción o conversación. No sólo fragmentos curados.
this is a catastrophe. StackOverflow provided data to LLMs, LLMs replaced StackOverflow, and now no new Q&A hub exists to provide fresh data. it’s a self-undermining causal loop, like mold growing on food, consuming it, and dying once the food is gone.
Suecia apuesta por volver a lo básico: libros de texto, papel y bolígrafo. Gobierno de Suecia ha decidido dar un paso atrás en su estrategia de digitalización educativa. Parte de una reflexión sobre cómo las pantallas estaban afectando negativamente al aprendizaje de los estudiantes https://t.co/Bg2fSRyK8S
At least 25 data centers were canceled last year as communities organized and pushed back against them. That's four times as many as 2024, according to @heatmap_news.
Why you should know the difference between Tokenization and Vectorization.
Most people mix these up. It is common to hear them used interchangeably as just "text processing," but they are actually two distinct steps with completely different goals.
1. Tokenization: The Structure 🪓
Action: Slices text into smaller units (tokens).
Output: A list of IDs.
Analogy: Chopping vegetables. You are just prepping the ingredients into usable pieces.
2. Vectorization: The Meaning 🧭
Action: Converts those tokens into mathematical coordinates.
Output: Semantic understanding (e.g., "King" is mathematically close to "Queen").
Analogy: Analyzing the flavor profile. Now you are defining what the ingredient is.
The Bottom Line:Tokenization handles Syntax. Vectorization handles Semantics.
You can chop an onion (Tokenization) without knowing what it tastes like (Vectorization)—but you need to do both to cook.
Con una base instalada que supera los 1,500 millones de iPhones, Gemini se posiciona —una vez más— como el motor de IA de facto para el ecosistema Apple. ¿Cuáles son las implicaciones de esto? No debemos olvidar que Google mantiene un acuerdo valorado en cerca de 20 mil millones de dólares para permanecer como el buscador predeterminado en Apple, una estrategia que ha sido clave para cimentar su hegemonía en el mercado de búsquedas.
La interrogante ahora es si esta maniobra permitirá a Google consolidar también su ventaja como la IA dominante en las interacciones del día a día. Queda pendiente observar cómo responderá Siri ante esta integración, especialmente cuando la plataforma nativa de Apple parece estar rezagándose frente a la competencia
📚 5 Días de cursos transformativos y fundacionales: Día 1
La clase que podríamos decir lo empezó todo: Machine Learning de @AndrewYNg (@Stanford ).
Este fue el curso que disparó la fiebre del ML en muchas partes del mundo y con el que arrancó Coursera (aunque la versión online sea una adaptación más "light" del material original).
Para mí, la historia fue distinta. Yo ya había aprendido Machine Learning tiempo atrás, pero este curso se convirtió en mi "Estrella Polar" (North Star) para la docencia.
Andrew Ng no solo me mostró algoritmos que ya conocía; me enseñó cómo explicarlos. Su capacidad para transmitir intuición matemática y su claridad inspiraron a cientos de miles, y ciertamente definieron mi camino para enseñar esta disciplina con la misma pasión, rigor y amor.
Si hoy disfruto tanto estar frente a un grupo explicando Deep Learning, es porque tuve el mejor referente de cómo hacerlo.
👇 Cuéntame: ¿Este curso fue tu introducción al ML o también te sirvió para reforzar conceptos?
#MachineLearning #AndrewNg #AI #Docencia #DataScience #Stanford #education
La definición de "Data Scientist" se está reescribiendo
Estamos presenciando un cambio fundamental en lo que significa practicar la Ciencia de Datos. Los silos entre los roles se están desmoronando, y la IA Generativa es el mazo que los está rompiendo.
Esta es mi predicción hacia donde se dirige el rol en 2026:
1. El auge del practicante de IA "Full-Stack"
Los días de "yo solo construyo el modelo y se lo paso al ingeniero" están terminando. El Data Scientist debe aprovechar la GenAI para cerrar la brecha hacia la Ingeniería de Datos y el ML Engineering. No necesitas ser un experto en cada herramienta de infraestructura, pero debes saber usar la IA para escribir el Terraform, optimizar el SQL y contenerizar la aplicación. La expectativa ahora es tener capacidades end-to-end.
2. Pipelines supercargados
Si no estás integrando la programación con GenAI en tu flujo de trabajo, ya te estás quedando atrás. No se trata solo de escribir código más rápido; se trata de arquitectar pipelines robustos a una velocidad que antes era imposible. Elige una herramienta, domínala y deja que maneje el código repetitivo (boilerplate) para que tú puedas concentrarte en la arquitectura.
3. El regreso a los fundamentos
Paradójicamente, a medida que codificar se vuelve más fácil, la comprensión teórica profunda se vuelve más crítica. Cuando la IA escribe el código, se pierde la fricción de "aprender haciendo". Por eso, es vital entender exactamente qué están haciendo los modelos "en el fondo" (in the background). Si no puedes explicar la matemática o la lógica detrás de la caja negra, no podrás depurarla cuando inevitablemente alucine o sufra de drift.
El veredicto: Usa la GenAI para ampliar tu alcance operativo, pero redobla tu profundidad teórica para mantener tu ventaja competitiva.
¿Estás de acuerdo? ¿O ves que los roles se volverán más especializados en lugar de converger?
#DataScience #InteligenciaArtificial #MachineLearning #GenAI #DesarrolloProfesional #TechTrends
Este año fue intenso… en el mejor sentido posible.
Tuve la oportunidad de viajar a Japón para dar conferencias, gracias a la invitación de Christian Peñaloza, uno de los líderes mexicanos que están generando un impacto real allá. Después vino Sofía, Bulgaria, para hacer lo mismo: compartir ideas, aprender y confirmar que estas conversaciones sobre IA ya son verdaderamente globales.
En el ámbito académico, impartí cinco clases en total. Una de ellas fue especialmente significativa: mi primera clase en la Escuela de Matemáticas Bourbaki, junto a mi amigo Carlos, uno de los grandes referentes educativos de la región. Las otras fueron en la Universidad Panamericana, enfocadas en Deep Learning y Machine Learning: profundas, retadoras y muy satisfactorias.
También escribí un artículo para la conferencia de IA más importante de México, junto con Edgar Avalos, otro hito que me obligó a afinar ideas y convertir la práctica en teoría.
En lo profesional, lideré un proyecto multimillonario en Novartis y más adelante tuve la oportunidad de convertirme en Head of Innovation AI Lab en GBM, trabajando con el increíble Alejandro Correa, sin duda uno de los mejores líderes de IA en la región.
Todo esto ocurrió en paralelo a múltiples conferencias académicas y de industria en Ciudad de México, Puebla y Guadalajara.
Y como un logro muy personal, el crecimiento de nuestro podcast Eurekai, junto a Enrique Siqueiros, una de las voces más fuertes en México sobre IA humanizada. Ver crecer esa comunidad ha sido algo muy especial.
Agradecido, cansado, inspirado… y muy consciente de que esto es solo un paso más, no el destino.
Seguimos 🚀