flex factor -- your flex relative to your net worth. Important in Germany were things are measured, standardized so people can understand and generational wealth is the predominant form of wealth.
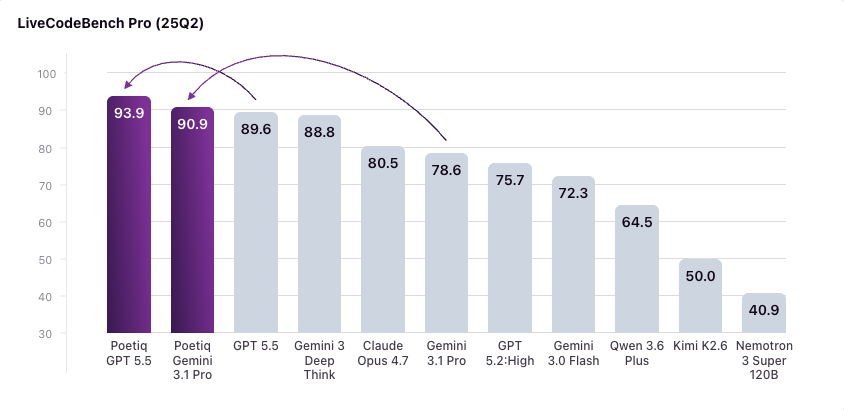
Poetiq's Meta-System built its own coding harness from scratch. It got SOTA on LiveCodeBench Pro.
No fine-tuning, no special model access. Just standard APIs. Using Gemini 3.1 Pro, it made a harness that beat all frontier models we tested.
@KyleHessling1 Thank you for calling out the “highly experimental” part. Had it halfway deployed to do fuel estimates on my nuclear power plant. I’ll use llama 3 then…
🇨🇳After testing Chinese models over the last few weeks, my coding ranking currently looks like this:
1. Kimi K2.6
2. GLM-5.1
3. MiMo V2.5 Pro
4. MiniMax 2.7
5. DeepSeek V4 Pro
👉But each of them has its own superpowers.
Frontend/Design: K2.6
Backend: K2.6 / GLM-5.1
Code review: MiMo
All-rounder: M2.7
Reasoning: DeepSeek
Now I'm waiting for MiniMax 3.0, which I hope will take the number 1 spot!
SubQ , a new type of AI model, says they are 50x faster and 20x cheaper than Opus 4.7 and GPT 5.5
In fact, they also say they perform INSANELY WELL on benchmarks and have a 12M context
This would be earth shattering, if true - Anthropic/OpenAI's valuation would go to zero 😱
This is one of the craziest AI launches of 2026 and it came out of basically nowhere (Save this).
A company called Subquadratic just shipped SubQ, and the benchmarks are almost hard to believe.
To understand why this is such a big deal, you have to understand the fundamental problem that has defined AI for the last decade.
Every large language model in existence is built on transformer architecture, and transformers use a mechanism called standard attention that checks every single word in a sequence against every other word.
Double the context length and compute doesn't double, it quadruples, triple it and compute goes up nine times.
This quadratic scaling is why frontier models have been stuck at roughly 1 million tokens, why running them at those lengths gets expensive fast, and why the AI labs have essentially been printing money charging you more the longer you need the model to think.
The industry has known this problem existed since 2017 but they scaled it anyway. SubQ is built from the ground up to solve it.
Instead of processing every possible token relationship, SubQ's sparse attention architecture identifies which relationships actually matter and ignores the rest meaning compute is used where it counts and wasted nowhere else.
The result is that compute scales linearly with context length instead of exponentially, and the implications of that one architectural shift are enormous.
At 12 million tokens, SubQ reduces attention compute by nearly 1,000x compared to standard frontier models and at 1 million tokens, it runs 52x faster than FlashAttention.
And it does all of this while posting frontier level accuracy, scoring 95% on the RULER 128K long-context benchmark versus Claude Opus 4.6's 94.8%, and an 81.8 on SWE-Bench Verified coding tasks, besting Opus 4.6 (80.8) and DeepSeek 4.0 Pro.
The cost comparison is where it gets genuinely insane.
SubQ runs at under $1.50 per million tokens less than 5% of what Claude Opus charges.
On the RULER benchmark, running the test with SubQ cost $8, running the same test with Claude Opus cost $2,600 and that's a 300x cost reduction at equivalent or better accuracy..
Subquadratic launched with $29 million in funding, SubQ is available today for early access via API, and SubQ Code, a coding agent built on the architecture ships alongside it.
The transformer has been the unchallenged foundation of every major AI system since 2017.
SubQ is the first serious evidence that something structurally better might have just arrived.