Leopold Aschenbrenner’s Situational Awareness LP just dropped its Q1 2026 13F, and the move that stands out isn’t the longs — it’s the puts. The fund layered on multi-billion dollar bearish positions across the semiconductor stack: more than billion notional on SMH, over .5 billion on NVDA, roughly billion on AVGO, plus sizable books on AMD, TSM, ASML, MU, and fresh INTC puts while closing prior long calls. Last quarter they held basically zero puts. This is not protective hedging. This is a deliberate, sized short on the most crowded, highest-multiple corner of the AI hardware trade.
The deeper context is Aschenbrenner’s core thesis from his 2024 essay “Situational Awareness: The Decade Ahead.” He puts AGI around 2027 and superintelligence shortly after, but argues the binding constraint is physical infrastructure, not intelligence. Trillions in capital expenditure will be required for clusters, power generation, chips, cooling, and data centers. The fund’s edge is supposed to come from seeing where the real bottlenecks sit before traditional markets price them in.
What the filing shows is a tactical rotation inside that same long-term view. Aschenbrenner is staying aggressively long the broad AGI buildout while exiting or hedging the part of the supply chain that got the frothiest: semiconductors. At the same time he is adding heavily to power, energy, and flexible hosting plays — CleanSpark added over 10 million shares, CoreWeave another million-plus, with continued exposure to Riot, IREN, Applied Digital, and Bloom Energy. The signal is clear: semis are priced for perfection, while power and rapid-deploy compute capacity remain the scarce resources that will actually determine who captures margin as the buildout continues.
Bitcoin miners that have quietly converted capacity to AI hosting now look especially well positioned under this lens. They already cleared the hardest hurdle — securing grid interconnection and power. That advantage is suddenly worth far more than a slightly better chip process node. This filing is sophisticated capital acknowledging that the game has moved downstream. The people who wrote the AGI timelines are now positioning for a world where power is the new oil and hosting flexibility is the real moat.
Big moment for the future of AI in our region. 🚀
Today, Sacramento State joined industry partners, education, and civic leaders in signing a Memorandum of Understanding (MOU) to formalize a first-of-its-kind AI workforce pipeline from kindergarten through career. 📚 💼
The AI K-Career initiative brings schools and industry partners together to align on what education, skills, and training are needed to connect people to jobs in the @CityofRCordova—setting a new standard for how regions can prepare talent for the future.
"This is exactly the kind of collaboration that defines what a university like ours does. We prepare students to create a better life through alignment with industry partners, ensuring they graduate with gainful employment. We're glad to be in partnership with all the amazing people around this table and looking forward to being a core part of what is going to continue to transform this region." - President @DrLukeWood@flcfalcons@FolsomCordova@FarmGPU@hmci_ai@NVIDIAAI@SacStateCarlsen@solidigm
📸 Sacramento State/Andrea Price
The neoclouds quietly became the second tier of hyperscale AI infra. Same 100kW racks, same RoCE fabrics, same firmware nightmares — on a fraction of the team and balance sheet. That's the gap OCP's new Scaling AI Clusters at Neoclouds workstream exists to close, and FarmGPU is co-chairing it alongside Scaleway and Denvr Dataworks.
A few signals from the first 19-operator community survey worth paying attention to:
→ Power sourcing and benchmarking are rated the most important 2026 problems (4.21 / 4.05 importance).
→ But the area where operators think OCP can move the needle most is open rack and pod reference patterns for 30–100kW (4.11 leverage). Hardware ≠ the bottleneck. Operational surface area is.
→ The top operator pain points: networking (RoCE/IB tuning, congestion control), management & automation (Day-2 ops, firmware), and interoperability (BMC/BIOS/telemetry consistency). Every neocloud is independently re-discovering the same gaps and filing the same tickets to the same OEMs.
Concrete output already in motion:
1. A neocloud Redfish profile. Redfish works great on Dell, inconsistently everywhere else. Instead of 20 operators each begging OEMs separately, the workstream is drafting a collective, machine-validatable profile that codifies the BMC, firmware, TLS, telemetry, and event-subscription behaviors neoclouds actually need. One spec OEMs implement against. One checklist procurement validates.
2. FarmGPU is the first neocloud running an OCP-aligned backend fabric in production — the AI Training Fabric Reference Architecture we co-developed with Hedgehog and Celestica. Celestica DS5000 (51.2T) + SONiC + Hedgehog as the K8s-native control plane. 36 ready-to-deploy composition variants spanning OPG-64/128/256/512 → XOC-256/512/1024, air- and liquid-cooled, single- and dual-plane. Vendor-neutral, declarative, reproducible. Contributed back to OCP so nobody has to reinvent it.
3. OCP NVMe SSD spec → predictive failure engine. We standardize on the OCP Datacenter NVMe SSD spec because the telemetry surface is dramatically richer than vanilla NVMe. On top of that we built a fleet-wide predictive failure engine — scores every drive for NAND degradation, ECC escalation, recoverable/uncoverable error trends, surfaces replace/watch/monitor recommendations. Plan is to open-source it so other neoclouds can run it directly.
The whole thesis: write down what neoclouds actually need → get OEMs to ship it through OCP → open-source the operator tooling that turns the spec into operational value. That compounds.
Full writeup, survey results, hardware-management deep dive recording, and how to join the workstream: https://t.co/G2dbSjh2Q1
🌾🚜
Everyone benchmarks GPUs. Almost no one benchmarks the cluster.
@lebanonjon on @SDxCentral: storage, fabric, and the boring stuff that decides whether your H100s actually earn their keep.
https://t.co/7JkrWsaScr
🚜 The OCP just published the first real framework for DC-powered AI data centers. Most of the industry hasn't read it yet.
On March 30, the OCP DCF Power Distribution sub-project — co-led by ABB and Eaton, with NVIDIA, Google, Microsoft, Amazon, AMD, Siemens, Schneider, Vertiv, and 180+ others on the workstream — shipped a white paper on Low Voltage DC power distribution for AI factories.
This isn't a research curiosity. It's the architectural foundation for every NVIDIA 800V DC rack Jensen has been talking about, and the reason Mt. Diablo exists.
The thesis in one sentence: AC has a 100-year head start, but it can't carry a 1+ MW rack without losing 5–10% to conversion stages and choking on 30→100% load swings in milliseconds. So the industry is rediscovering DC.
The numbers worth stopping for:
→ ORv3 HPR power shelves went from 33 kW (v1, AC) → 72 kW (v2, AC) → 100 kW (v4, DC) in the same 1 OU footprint. A 39% density jump, almost entirely from deleting the AC/DC conversion stage.
→ Moving the BBU and CBU out of the IT rack into the Mt. Diablo sidecar reclaims 12–16 OU of compute volume. Another 27–36% of usable rack space, given back to GPUs.
→ AI training availability target: 99.9%. Inference: 99.999%. The catch nobody talks about: DC distribution cannot use UPS maintenance bypass. Redundancy has to live at the power block level. This rewrites how you think about N+1.
→ AI workloads ramp 30→100% in milliseconds. The CBU (capacitor backup) responds in sub-ms. AC architectures can't keep up. Grid operators have noticed.
If your data center can't physically fit a Mt. Diablo / 800V DC rack, you can't run the next NVIDIA generation at full density. The 415V/480V room is already a stranded asset for hyperscale AI.
Read the whitepaper: https://t.co/39YaFg1gq6
🌾🚜
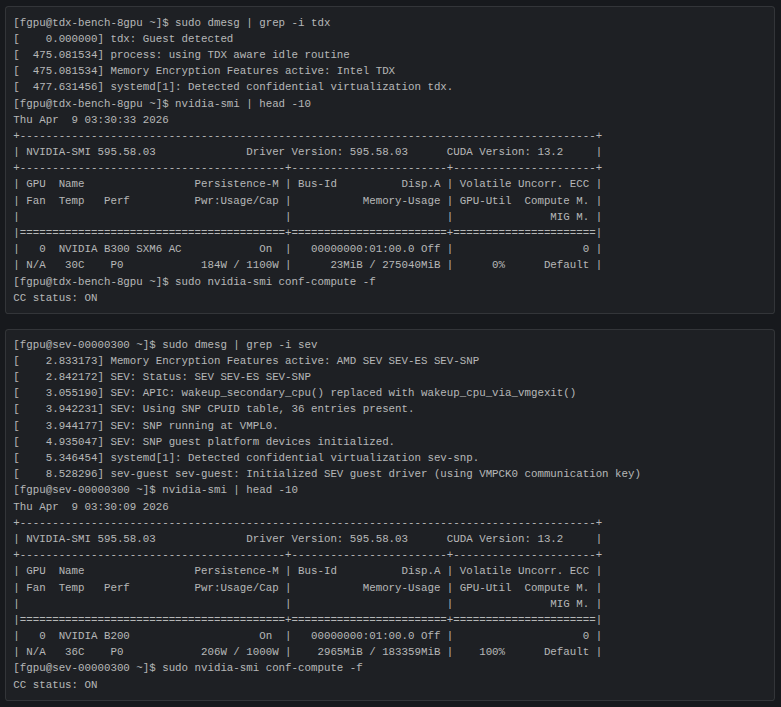
Confidential Computing: Securing Data Where It's Most Vulnerable — In Use
You encrypt data at rest. You encrypt data in transit. But when a GPU processes it — training a model, running inference — it sits in memory in plaintext. Anyone with hypervisor or BMC access can see it. Confidential computing closes that gap.
The Problem: Data in Use Is Data Exposed
Three data states exist: at rest (encrypted, solved), in transit (encrypted, solved), and in use (traditionally wide open). For AI workloads, the stakes are massive — model weights that cost $50M-$500M to train sit in GPU memory unprotected. Training data with PII, financial records, healthcare info — all decrypted during computation.
Confidential computing uses hardware-based Trusted Execution Environments (TEEs) to encrypt and isolate data DURING computation. Not after. Not during transport. While it's being processed.
CPU TEEs: The Foundation
Intel TDX (Trust Domain Extensions) — Creates hardware-isolated VMs called Trust Domains. Entire VMs run with encrypted memory (AES-XTS-128 via MKTME with 28-bit MACs). The hypervisor can schedule VMs but cannot read their memory or modify their code. TDX Connect extends this to PCIe devices, enabling encrypted DMA between CPU and GPU TEEs.
AMD SEV-SNP — Three generations deep. SEV (encryption only) → SEV-ES (+ register protection) → SEV-SNP (+ memory integrity). SEV-SNP prevents hypervisor replay and corruption of encrypted memory. SEV-TIO extends TEE protection to PCIe devices.
ARM CCA — Realm Management Extensions create isolated Realms. Relevant for Ampere-based cloud and edge.
CPU TEEs are necessary but not sufficient for AI. They protect host-side code and data, but GPUs process the most sensitive information — and GPU memory has historically been unprotected.
GPU TEEs: The New Frontier
NVIDIA's H100 was the first production GPU with confidential computing. The architecture:
1. CC-On Boot — GPU boots with hardware protections enabled. On-die silicon root of trust. Debug access, JTAG, and performance counters disabled. BMC restricted to anonymous health metrics only.
2. Secure Boot Chain — Signed firmware verified during boot. Firmware measurements stored in hardware registers. Chain of trust from silicon to software.
3. SPDM Key Exchange — In-CVM driver and GPU firmware establish an SPDM session via Diffie-Hellman. Both authenticate, exchange firmware measurements, and establish AES-256-GCM session keys for all CPU↔GPU data.
4. Data Transfer Modes:
• Bounce Buffers — Shared encrypted pages, AES-256-GCM with rolling 96-bit IVs. Hypervisor sees ciphertext only. Works on Hopper and Blackwell.
• TDISP/IDE (Blackwell + Granite Rapids) — GPU DMAs directly into CVM-private memory. No bounce buffers. IDE encrypts every PCIe TLP at line rate. Zero-copy, near-zero overhead, hardware end-to-end encryption.
5. GPU Memory Encryption — All HBM encrypted. Keys managed by GPU security processor, ephemeral, destroyed on teardown.
6. NVLink Encryption — Blackwell encrypts GPU-to-GPU traffic at 1.8 TB/s via AES-GCM. Critical for distributed training and large-model inference.
7. Remote Attestation — Cryptographically signed reports of firmware version, boot measurements, and configuration. Dual attestation: Intel TDX + NVIDIA GPU TEE providing independent verification.
What It Protects — And What It Doesn't
Protects against: Cloud operator insider access, compromised hypervisors (VM escape), physical access (PCIe analyzers, DIMM dumps, JTAG), co-tenant VMs, supply chain attacks (with attestation).
Does NOT protect against: Side-channel attacks (raised bar, not eliminated), compromised app logic inside the TEE, output inference attacks (differential privacy is the countermeasure).
The Trust Boundary
• Trusted: Inside the CVM — your application, CUDA kernels, model weights, training data. Encrypted in CPU memory by TDX/SEV, encrypted in GPU memory by NVIDIA CC. Only you hold the keys.
• Encrypted boundary: PCIe link + bounce buffers (or TDISP/IDE on Blackwell). All data AES-256-GCM encrypted. With TDISP/IDE, even shared memory intermediaries are eliminated.
• Untrusted: Hypervisor, host OS, BMC, physical access. All see only ciphertext. Keys ephemeral, destroyed on teardown.
Why Now
1. Regulation is enforceable. GDPR requires data protection during processing. HIPAA requires safeguards for PHI during computation. EU AI Act (enforceable August 2027) classifies models >10^25 FLOPS as systemic risk. 35+ countries have sovereign AI programs. This is procurement requirements, not theory.
2. Multi-party AI needs it. Training on combined datasets without exposing raw data requires TEEs. Alternatives (homomorphic encryption, SMPC) are 10-1000x slower. TEEs make multi-party AI commercially viable.
3. Model IP is a survival issue. Frontier training runs cost $50M-$500M. Without TEEs, any admin can dump model weights. CC converts IP protection from a trust relationship into a cryptographic guarantee.
The Market
• 75% of orgs adopting CC (IDC, Dec 2025), 18% in full production
• Market: $12.28B (2025) → $54.92B (2030), 34.7% CAGR
• Azure: only hyperscaler with GA confidential GPU VMs (SEV-SNP + H100, single GPU)
• Google Cloud: TDX + H100, 3 zones, GA Aug 2025
• AWS: no GPU TEE capability (Nitro Enclaves can't access GPUs)
• CoreWeave, Lambda, Crusoe, RunPod: zero CC capability
Hardware's here. Stacks are maturing. Regulations are enforceable. The question isn't whether — it's how fast. 🌾
We partnered with @RunPod to build something the GPU cloud market hasn't had before: bare-metal B200 training performance with instant cluster spin-up, Docker-native, pay by the second.
The "instant" part is real. You spin up a 6-node B200 HGX cluster the same way you'd launch a RunPod pod — minutes, not months. No procurement cycle. No contract. No minimum runtime. Same UX. Training-class hardware.
Under the hood:
• 800G open Ethernet fabric (Celestica DS5000 + @githedgehog) — 50% cheaper than Spectrum X, 400 GB/s GPU-to-GPU bandwidth
• Solidigm PCIe 5.0 NVMe, 8 drives per node — 116 GB/s local storage, #1 in @SemiAnalysis_ ClusterMAX 2.0
• RoCEv2 + NVMe-oF, custom optics for CX7/BF3. OCP-compliant, fully open-spec.
On NCCL: 390 GB/s AllReduce bus bandwidth on 32 B200s. 2.3x performance improvement at 16 MB message size — the exact range SemiAnalysis identifies as critical for real training workloads. Sub-50µs latency for small messages.
Why does that matter? A network that's half as slow on AllReduce costs you 10% MFU on 70B parameter training and 15-20% on MoE models. That's real dollars, idle GPUs, wasted runs. We made NCCL performance the obsession, not an afterthought.
The RunPod magic is the combination: full training performance inside a Docker container, on bare metal, with the same experience you'd use to launch a single GPU pod. No SLURM expertise. No ops team. Full cluster, browser to training job, in minutes.
Two years building this with @RunPod. ClusterMAX #1 in storage. 390 GB/s NCCL. B200 bare metal, instantly available.
https://t.co/DOGdCqjw8z 🌾
B200 bare metal performance. Spins up in minutes.
Good news
FarmGPU + @RunPod Instant Clusters: B200 HGX, 800G open Ethernet fabric, 8x PCIe 5.0. NVMe per node via @Solidigm
No procurement queue. No hyperscaler tax. Just the hardware.
Bad news
we are sold out 😭 need more GPUs
https://t.co/DOGdCqjw8z
NVIDIA's GPU fault remediation tool went production-ready this week. It's called NVSentinel, it's open-source, and I think it's worth understanding how it works because it draws a clean line between two very different layers of the infrastructure stack.
NVSentinel sits inside Kubernetes. It reads GPU health signals from the NVIDIA driver via DCGM, catches things like ECC errors and driver crashes, and then takes automated action at the scheduler level: cordon the node, drain workloads, hand off to a repair workflow. For teams running NVIDIA GPUs on Kubernetes, that automation is real and useful.
What caught my attention is where it stops. NVSentinel operates above the OS. It can tell you a GPU is failing and pull it out of rotation, but it doesn't go below the driver layer to diagnose root cause, it doesn't talk to BMCs, and it doesn't correlate failures across a fleet. The repair workflow it triggers is a handoff to an external system that has to actually figure out what happened and fix it. That lower layer, actual hardware-level diagnostics and recovery, is what we're focusing on at Cosmic.
I like that NVIDIA is raising the baseline here. It makes the conversation about where the real complexity lives a lot easier to have.
What does your GPU fault response look like today? Are you handling it at the Kubernetes layer, the hardware layer, or both?
AI broke the old cloud model.
General-purpose cloud was built for cheap compute abstraction. AI infra is different: storage, fabric, and power density now drive the economics.
If your GPUs wait on I/O, your cloud model is wrong.
https://t.co/3jtZVOCoMS
We’re testing NIXL, Dynamo and new kvcache bench now. Very different world where GPU is the star of the show and they become data monsters instead of just compute monsters
NVIDIA STX is more than just a new storage device. It represents a redesign of how AI systems move, access, and manage data. Traditional storage architectures were built for reliable, large-scale data storage, but agentic AI and long-context inference require different capabilities. These systems need to retrieve data quickly, maintain context across multiple steps, and access information continuously during inference workflows. Under these conditions, conventional storage can become a bottleneck: increased latency, slow data transfer, and decreased GPU efficiency. STX aims to bridge this gap.
Essentially, STX functions as a high-speed data layer positioned between GPUs and standard storage infrastructure. Its purpose is to bring data closer to computing resources, accelerate read/write operations, and reduce data movement overhead. This allows GPUs to spend less time waiting for data, enabling AI models to handle long contexts, multi-step reasoning, and real-time tasks more efficiently.
STX is not just about improving storage performance by optimizing the efficiency of the entire AI infrastructure. Future AI systems will be defined not only by raw compute power but also by how quickly data can be delivered, how well context can be maintained, and how effectively the inference pipeline is optimized.
SemiAnalysis nailed it: agentic workloads and media generation are making GPU demand more price-insensitive.
Cheaper tokens don't shrink demand. They flood the field.
Jevons is farming now. 🌾 @SemiAnalysis_
https://t.co/4hZ8oXPpNN
NVMe is no longer just storage. It’s becoming part of the inference memory hierarchy.
That means predictive failure analysis and storage telemetry stop being optional.
Exactly the shift operators should be watching:
https://t.co/HtqIQEhZ76
There is a 1,500x bandwidth gap hiding in the inference memory hierarchy. And it is about to become everyone's problem.
NVIDIA's Vera Rubin platform now treats the NVMe SSD as part of the inference memory hierarchy. Their CMX architecture (launched at GTC last month with BlueField-4 STX) offloads KV cache from GPU memory to flash so that evicted context survives instead of being recomputed. The performance gain is up to 5x higher tokens per second. Dell, HPE, VAST Data, WEKA, and a dozen other vendors are building products around it. CoreWeave, Lambda, and Oracle are early adopters.
That means the SSD is no longer background storage. Its read latency directly affects time to first token. On a deployment serving tens of thousands of requests per hour, even a small increase in drive latency compounds across every single one.
The technical detail worth understanding: KV cache stores the attention state for every token in context. As context windows grow into the hundreds of thousands of tokens, the cache overflows GPU HBM (22 TB/s on Rubin) into host DRAM (~300 GB/s) and then onto NVMe (7-14 GB/s on PCIe Gen5). That is a 1,500x bandwidth drop from HBM to SSD. The system works when the drive is healthy. When it is not, every cache read slows down, and the latency shows up in token generation without any GPU-side signal that something is wrong.
KV cache recycling is also a write-heavy workload. Every eviction and reload burns SSD write cycles, and the drive's internal garbage collection multiplies those writes further depending on drive quality and whether you are running enterprise TLC or cheaper QLC flash. As the NAND wears, read latency creeps up gradually. The degradation looks like a model problem or a network issue long before anyone checks the drive.
Most inference monitoring tracks GPU utilization, temperature, and token throughput. SSD wear, write amplification, and drive-level latency are almost never in the stack.
Is drive health part of your inference observability, or is the SSD still invisible?
If only a certain neocloud piloting this stack with @nvidia for @Solidigm's AI Central Lab were building the predictive failure engine on top of @OpenComputePrj + hyperscale specs 😎
Once NVMe becomes part of the inference memory hierarchy, storage telemetry stops being optional.
Four business models. One thesis.
1/ On-demand GPU via @RunPod (US-CA-2)
2/ Dedicated bare-metal clusters
3/ Managed GPU infrastructure
4/ NeoCloud software stack
All built storage-first. All running now.
https://t.co/thkGOZ1616
Storage determines whether AI infrastructure actually works.
Our partnership with @solidigm is about building the data layer the right way — not treating storage like an afterthought.
Why that matters:
https://t.co/p49vXH8Xto
Building a 32-node B200 AI cluster was a firsthand reminder that networking is brutally hard.
Optics, switching, RDMA, open fabrics — that was the real grind.
What we learned in 17 days:
https://t.co/QPmh5PG8eU
FarmGPU ranked #1 in SemiAnalysis ClusterMax 2.0 storage benchmarks.
0.98s PyTorch import on H100. 0.72s on B200.
Most clouds talk about GPUs. We focus on the storage stack that keeps them from idling.
Details:
https://t.co/1trpGrJb3u
KV cache is becoming the real inference bottleneck.
With Lightbits + ScaleFlux, FarmGPU showed 100x-280x KV cache acceleration at GTC 2026 — enabling up to 3x more inference requests on the same GPUs with 65% lower infrastructure cost.
This is what storage-first AI infra looks like:
https://t.co/eycJdHqVJJ