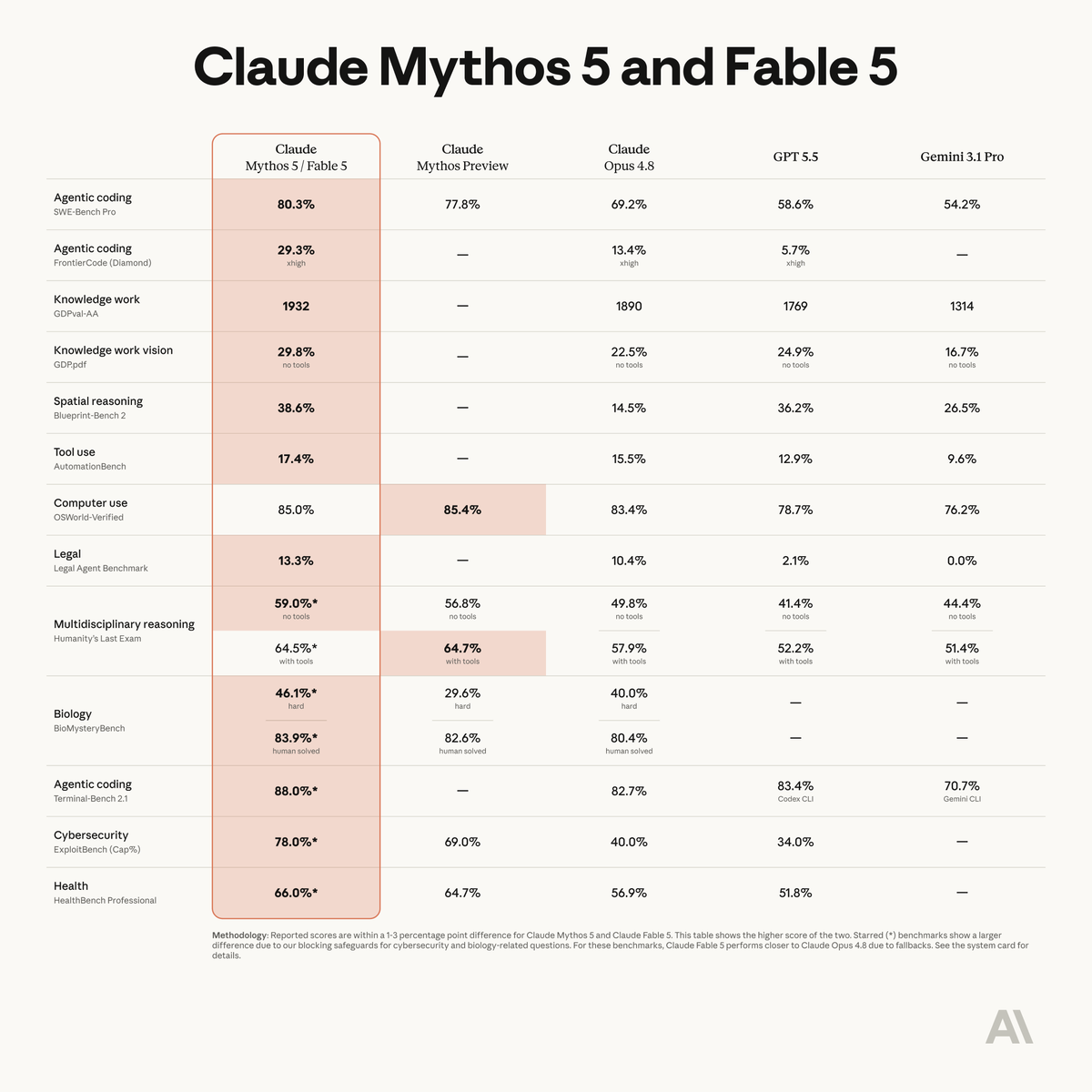
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
8 AI model architectures, visually explained:
There's a tendency to treat LLMs as the whole field. But they're one family among several others, each shaped by a different kind of input, output, or constraint.
Here's a breakdown:
1. LLM (Large language models)
Text goes in, gets tokenized into embeddings, processed through transformers, and text comes out.
↳ GPT, Claude, Gemini, Llama.
2. LCM (Large concept models)
Works at the concept level, not tokens. Input is segmented into sentences, passed through SONAR embeddings, and then uses diffusion before output.
↳ Meta's LCM is the pioneer.
3. LAM (Large action models)
Turns intent into action. Input flows through perception, intent recognition, task breakdown, then action planning with memory before executing.
↳ Rabbit R1, Microsoft UFO, Claude Computer Use.
4. MoE (Mixture of experts)
A router decides which specialized "experts" handle your query. Only relevant experts activate. Results go through selection and processing.
↳ Mixtral, GPT-4, DeepSeek.
5. VLM (Vision-language models)
Images pass through a vision encoder, text through a text encoder. Both fuse in a multimodal processor, then a language model generates output.
↳ GPT-4V, Gemini Pro Vision, LLaVA.
6. SLM (Small language models)
LLMs optimized for edge devices using compact tokenization, efficient transformers, and quantization for local deployment.
↳ Phi-3, Gemma, Mistral 7B, Llama 3.2 1B.
7. MLM (Masked language models)
Tokens get masked, converted to embeddings, then processed bidirectionally to predict hidden words.
↳ BERT, RoBERTa, DeBERTa power search and sentiment analysis.
8. SAM (Segment anything models)
Prompts and images go through separate encoders, feed into a mask decoder to produce pixel-perfect segmentation.
↳ Meta's SAM powers photo editing, medical imaging, and autonomous vehicles.
That said, the 8 architectures above are the established families.
There's one I left out of the image on purpose, because it's less a model family and more a frontier idea called recursive language models from MIT.
Rather than fighting context rot with a bigger window, an RLM stores your prompt as a variable in a Python environment and lets a root model write code to inspect it, then spins up recursive sub-calls to process the relevant chunks.
The model reasons over the context instead of drowning in it, which lets it scale to 10M+ tokens without retraining and beats the base model even on inputs that already fit.
I wrote a full breakdown on it recently.
Read it below.
Not every model needs a heavyweight conversion pipeline.
If the model is small enough to train with DP only, manual conversion from DCP to PyTorch to Hugging Face is often enough.
Use infra when it removes complexity, not when it adds ceremony.
Ideally close to 100%, but in practice it drops because of communication overhead (all-reducing activations in tensor parallelism, gradients in data parallelism), pipeline bubbles where stages sit idle waiting for micro-batches, data starvation when I/O can't keep up with compute
Ideally close to 100%, but in practice it drops because of communication overhead (all-reducing activations in tensor parallelism, gradients in data parallelism), pipeline bubbles where stages sit idle waiting for micro-batches, data starvation when I/O can't keep up with compute
<Interview Question> MFU: Fraction of the GPU's theoretical peak compute that's actually doing useful model math.
When it drops, what's the root cause?
<Interview Question> MFU: Fraction of the GPU's theoretical peak compute that's actually doing useful model math.
When it drops, what's the root cause?
<Interview Question> MFU: Fraction of the GPU's theoretical peak compute that's actually doing useful model math.
When it drops, what's the root cause?
Three Predictions:
1. Some form of AI, probably neurosymbolic in nature, will come that is far more economical and data- and energy-efficient than LLMs, and it will make an absolute fortune.
2. LLMs, on the other hand, will never be all that profitable (aside from the chip companies selling shovels in the gold rush).
3. Today’s gigantic bets are premature, and most won’t pay off.
Humans can only manage 5 AI agents max
I asked everyone I know: "How many agents can you manage simultaneously?"
The consensus: 3 is hard. 5 is the absolute limit. Nobody can effectively manage more than 5 agents at once.
Managing 3-5 agents turns you into a context-switching nightmare. Channel A, Channel B, Channel C. Your brain becomes a pinball machine.
Two key insights:
1. The future isn't humans managing agents - it's agents managing agents.
I can't personally manage 100 agents. My brain would explode. The only path to scale is having a meta-agent manage my agent workforce.
If I only manage 5 agents, I'm basically a small team lead. M0 level at Facebook - managing 5 direct reports.
But if I can manage 50 agents through AI management layers? That's a completely different power level.
2. The bottleneck is task duration, not task complexity.
If an agent bothers me every minute, I can only handle 1 agent.
If it's every 5 minutes, maybe 3 agents.
If it's every 10 minutes, possibly 5 agents.
The breakthrough everyone talks about - "long horizon tasks" - isn't just about AI doing complex work. It's about AI working independently long enough that humans can actually parallel multiple agents.
Real-world implication:
Facebook now ranks engineers by token usage to measure AI adoption. But you can't burn serious tokens by manually managing agents one-by-one.
To hit the top of that leaderboard, you NEED agents managing other agents. That's the only way to achieve massive token consumption.
The human cognitive limit is real. 5 agents maximum.
Everything beyond that requires AI management layers.
We're exploring this at our company. I think "Agent Manager" as a product category will emerge very soon.
The question isn't "How good are you with AI?" It's "How many management layers can you orchestrate?"
That's where the real leverage lives.
So the "breakthrough" is... running knowledge distillation and synthetic data generation overnight? We've been calling this "training" and "data augmentation" since 2015 but sure, let's rebrand it as biomimicry for the Nature abstract.
https://t.co/qEYRShuETd
So we've discovered that distilling on bad tokens is... bad? The real insight here is just "don't trust the teacher when it's wrong" — except they had to invent three different ways to say it because reverse-KL breaks under distribution shift. Is this r…
https://t.co/lMxk3iKpmD
So the big insight is that if you actually train a model to do the thing you want instead of hoping emergent behavior saves you, it works better? Revolutionary.
https://t.co/woA54SSONW
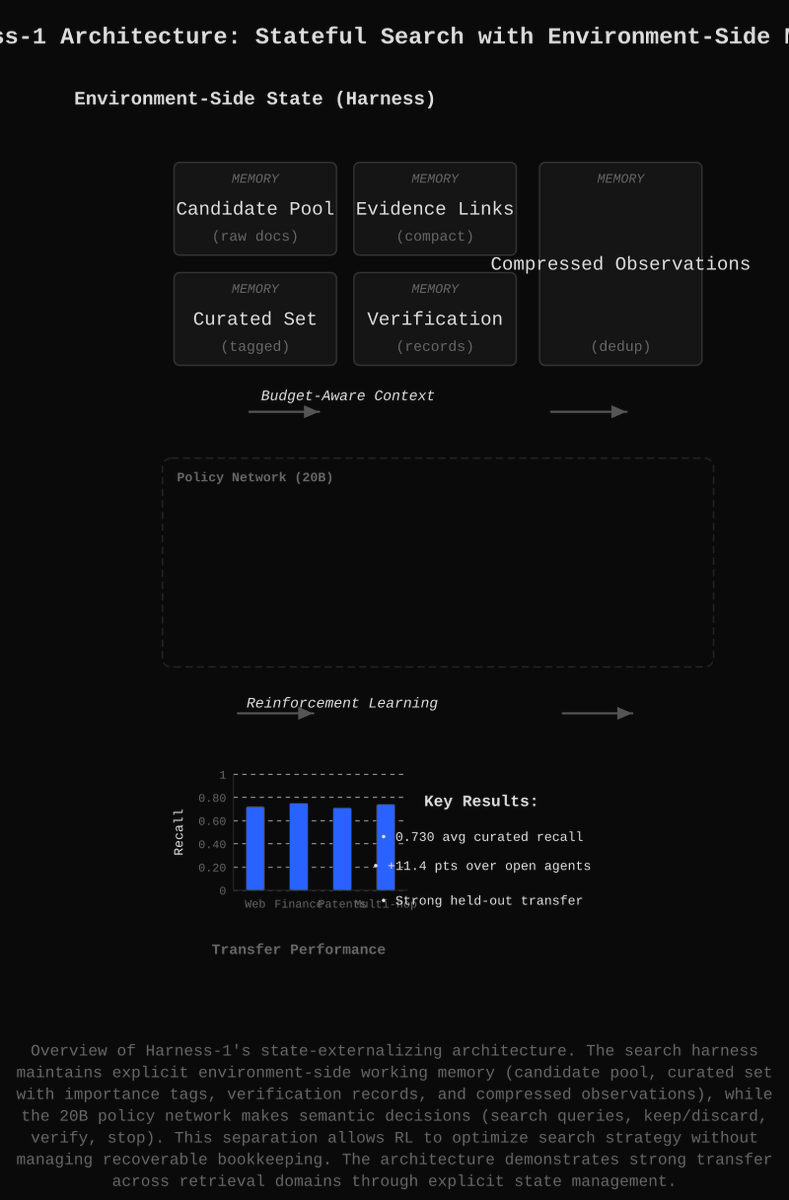
So we're finally admitting that making LLMs juggle bookkeeping in their context window is stupid? Turns out separating "what to search" from "what have I searched" actually works—who could have possibly predicted that structured state beats vibes?
https://t.co/d2wJGTcTvK