L'innovation est bouillante à #VivaTech
Mais une question récurrente brûle les lèvres ou écrits de certains :
Pourquoi n'y a t-il plus les lettres habituelles de @VivaTech devant lesquelles on pose chaque année ?
Rassurez-vous, les lettres sont bien là depuis le premier jour 🕺
Polsia just raised $30M at a $250M valuation.
Approaching $10M annual run rate.
One Founder + AI. Zero employees.
Polsia runs companies autonomously.
It also ran its own fundraising.
I just showed up for signatures.
La France est un pays de frondeurs, d’ingénieurs, de chercheurs et d’industriels capables de se réinventer quand l’ambition est claire.
Sur les semi-conducteurs et le quantique, il n’est pas trop tard. Mais il faut éviter l’erreur classique de vouloir tout faire, partout, avec trop peu de moyens
La France doit choisir les maillons où elle peut devenir indispensable.
Quelques points qui pourraient être intéressants :
1. Une fiscalité beaucoup plus attractive pour les pépites industrielles
Crédit d’impôt, amortissements accélérés, incitations au réinvestissement en R&D, stock-options plus compétitives, PEA encore plus avantageux pour orienter l’épargne vers nos champions technologiques.
Bonus : Un fond de retraite souverain avec avec un panier axé sur nos pépites (Spoiler : infaisable).
Il faut permettre aux jeunes entreprises hardware de grandir en France, de lever en France, de produire en France, sans être contraintes de partir chercher ailleurs le capital patient dont elles ont besoin.
2. Des parcours qualifiants beaucoup plus rapides
Les semi-conducteurs, ce ne sont pas seulement des ingénieurs. Ce sont aussi des techniciens de salle blanche, opérateurs, spécialistes packaging, test, métrologie, maintenance, process, qualité.
Il faut des formations courtes, exigeantes, professionnalisantes, directement connectées aux fabs, aux laboratoires, aux sous-traitants et aux équipementiers.
Pas dans cinq ans, il nous le faut au plus vite.
3. Des investissements massifs sur des niches critiques
>La Corée est devenue incontournable en mémoire avec Samsung et SK Hynix qui ont récemment poussé l'indice coréen très haut.
>Taïwan en fonderie avec TSMC.
>Les Pays-Bas en lithographie avec ASML.
La France doit choisir ses propres goulots d’étranglement : matériaux, électronique de puissance, photonique, packaging avancé, équipements, logiciels EDA, contrôle qualité, supply chain critique.
Et ces entreprises existent déjà. 2CRSI, KALRAY , SOITEC, STMi, RIBER pour ne citer que elles.
Je pense qu’Il faut arrêter de penser uniquement en enveloppes budgétaires
Le vrai sujet, c’est la concentration des moyens, la vitesse d’exécution et la construction d’un avantage industriel défendable sur 10-20-30 ans, comme on a su faire sur le nucléaire. Mieux vaut dominer 3 maillons critiques que subventionner 30 projets moyens.
La France sait faire, nos ingénieurs sont parmis les meilleurs au monde. Maintenant, il faut choisir, accélérer et protéger nos champions.
Notre pays est incroyable mais rendons le indispensable
Anthropic vient de prouver qu’on peut être rentable dans l’IA générative.
OpenAI continue de brûler 14 milliards par an et prévoit 115 milliards de pertes cumulées d’ici 2029. Mistral plafonne.
Quand l’un démontre que c’est possible, les autres deviennent suspects. Le marché va commencer à trier.
Pour la première fois, une grande IA générative gagne plus d’argent qu’elle n’en brûle.
C’est la fin d’un mythe : celui d’une bulle technologique qui ne tiendrait que sur des promesses. L’IA n’est plus une dépense d’avenir, c’est une industrie qui dégage du cash.
Et ça change tout. Pour les marchés, pour les valorisations, pour les concurrents qui n’y arriveront jamais.
Le problème n'est pas que les députés français ne comprennent rien à l'IA. Il est plus profond.
Le 12 mai, Arthur Mensch était auditionné à l'Assemblée nationale par la commission d'enquête sur les vulnérabilités numériques. Le diagnostic du PDG de Mistral est clair : l'IA est une technologie d'infrastructure; l'Europe a quelques mois pour choisir entre en être productrice ou simple consommatrice.
Premier élément frappant : la salle est quasi vide.
Deuxième élément: les questions posées à Mensch sont triviales et montrent une méconnaissance de députés pourtant membres d'une commission sur le numérique et dont on aurait pu penser qu'ils maîtrisaient le sujet.
Troisième élément: un député présent s'inquiète qu'un data center consomme des terres "où il y avait des betteraves". Oui, Make the Betteraves Great Again semble être le leitmotiv de la commission... numérique.
L'absence, la trivialité et la question des betteraves disent la même chose: le sujet de l'IA n'est pas perçu comme stratégique.
Dans le modèle mental dominant, le numérique reste une nuisance à pondérer, pas une infrastructure à bâtir et encore moins un jeu industriel mondial à jouer avec nos atouts. On ne se déplace pas pour une nuisance. On vient, au mieux, pour la réguler.
Et après on pleure sur la souveraineté perdue. Les pays qui dominent l'IA ne sont pas plus intelligents. Ils ont simplement compris ce qu'est une infrastructure stratégique.
Le vrai problème de la France est là.
Excellente intervention de Mensch cette semaine à la commission d’enquête sur la souveraineté numérique.
Il aborde à peu près tous les thèmes avec brio, et expose parfaitement les enjeux.
C'est à se taper la tête contre les murs qu’il n’y ait eu qu’une poignée de personnes présentes, alors que c’est le futur du pays qui se joue là.
TOUS les politiciens devraient prendre verbatim son intervention et l'intégrer à leur programme 2027.
Ceux qui ne comprennent pas ce qu'il dit, ceux qui ne le prennent pas en compte, trahissent la France et son avenir.
Résumé :
Mensch commence par exempliquer que si la France et l'Europe passent à côté de l'IA, elles sortent de l'Histoire, et que ça se joue maintenant.
Stratégie de reconquête numérique : Le cloud, c'est l'IA. La distinction entre les deux est obsolète. La croissance et la marge à haute valeur ajoutée sont dans l'IA ; tout le reste suit.
Conséquence opérationnelle : on ne reconquiert pas le cloud par les couches basses (stockage, VM), on part de la couche haute marge et on redescend. C'est la matrice exacte d'un colbertisme technologique appliqué au numérique : capter l'amont stratégique, laisser l'aval se déployer.
Cadre macro. L'IA transforme électricité en tokens, ressource naturelle à traiter comme telle. Horizon 3-4 ans : 10% de la masse salariale européenne sera dépensée en IA, soit 1 trillion annuel. Importé, c'est 1 trillion de déficit commercial supplémentaire, réinvesti en R&D ailleurs. L'Europe n'a donc qu'un seul enjeu économique pour sa balance commerciale : produire de l'IA localement.
Horizon 5 ans : 1 kW d'IA potentiellement utilisable par personne, 40 GW à construire en France, 400 GW en Europe, 20 trillions d'investissement. C'est 24 EPR2 pour la France ! Sur la chaîne électron=>token, 10% de la valeur revient à l'électron, 90% au reste. Vendre seulement de l'électricité revient à abandonner 90% de la valeur. Mensch reprend cette idée essentielle que vendre de l'électrcité sans la tranformer en IA est une stratégie de pays non industrialisé. C'est précisément la trajectoire que la banane rouge doit empêcher : la France ne doit pas devenir la batterie d'un système industriel arbitré ailleurs.
Souveraineté = levier, pas isolationnisme. Importer 100% des services numériques = aucune carte à la table. Exporter de la technologie = levier réel. Mistral fait 70% hors de France, 25% hors d'Europe. Postionnement de Mensch contre le libre-échange naïf et contre l'autarcie symbolique.
Urgence : fenêtre de 2 ans. Les hyperscalers déploient 1 trillion en 2026 et monopolisent l'énergie européenne avant que la demande ne se matérialise. Surplus français de 9 GW capté par ceux qui paient avant la demande et aujourd'hui gaspillés en bradant à nos voisins. Mistral vise 1 GW d'ici 2029, insuffisant faute de visibilité marché. C'est le calendrier réel d'une résurgence civilisationnelle : deux ans pour reprendre une position dans la chaîne, ou disparition durable de la fonction.
Commande publique = levier décisif sous-utilisé. 50% du PIB européen. Doctrine américaine depuis les années 40. Tabou européen à briser. Préférence en bout de chaîne sur les services à forte valeur ajoutée, pas en subvention amont. Planifier la demande, pas la dépense. Application directe de la doctrine défendue ici : l'État ne distribue pas, il oriente la demande vers la base productive nationale.
Critique de la régulation comme protection. La régulation favorise toujours les gros, donc les Américains. RGPD + DSA + AI Act + copyright = empilement incohérent, 27 régulateurs.
Fragmentation : 60 telcos contre 3 aux US, fiscalité et droit social non unifiés. Mais attention au récit colonial intériorisé : "l'Europe a perdu car elle régule." Ce n'est pas le point central. Le point central est la domination géopolitique américaine et le manque d'investissement européen.
Validation directe du refus de l'échelle européenne : Mensch ne propose jamais d'action européenne coordonnée - à mon humble avis à raison, car les débats et les conflits à cette échelle empêchent d'être à la bonne vitesse d'exécution - il vise la commande publique nationale (Luxembourg cité en contre-exemple positif), le surplus énergétique national, les champions industriels nationaux. La seule chose qu'il demande à l'Europe c'est d'alléger sa réglementation.
Campus IA. Participation Mistral minoritaire. Capitaux étrangers faute de fonds de pension européens. Acceptable sous gouvernance contrôlée (siège BPI). Une partie servira les hyperscalers car la demande européenne est à 80% américaine ; trajectoire d'inversion à construire. Réfutation des critiques environnementale : nucléaire français = empreinte réduite vs Texas ; densité élevée (1 GW = 100 ha) ; internaliser la production pour avoir voix sur les externalités, sinon importer les arbitrages d'autrui. Logique banane rouge appliquée : un site énergie-ancré dont la chaîne aval reste à capturer.
Défense. Travail avec MinArm sans droit de regard sur l'usage final : pas de légitimité démocratique face à l'armée. (J'aime qu'ils n'essayent pas de se substituer à l'état contrairement aux hyperscaler américains). L'IA est désormais indispensable à la dissuasion conventionnelle (drones russes massivement IA-pilotés). Cyber : tous les modèles frontière découvrent vulnérabilités et orchestrent attaques, capacité linéaire et prédictible. Mythos d'Anthropic : marketing de la peur, pas une exclusivité technique.
Modèle économique et productivité. Chez Mistral, ingénieurs n'écrivent plus de code, x2 productivité en six mois. Services client x5. 10% masse salariale = prix d'achat pour 20% de gain net (règle : la techno ne capture jamais plus de 50% de la valeur créée). Trois chocs simultanés : destruction-transformation d'emplois rapide, inflation par conflit d'usage électrique, déficit commercial des services multiplié par 5. Triade analytique à intégrer. Le déplacement valeur travail→capital, avec capital majoritairement non-européen, est le problème distributif central : qui capte les gains de productivité IA en France, et comment cette captation peut financer la reproduction démographique des strates productives plutôt que repartir en dividendes hors-zone.
Bulle. Pas de bulle de demande, problème d'offre (semi, mémoire, hélium, électrons saturés). 50 Md$ pour 1 GW, retour attendu 100 Md,valeur client 200Md : ordres cohérents si parts captées vite.
Médiation cognitive. Les modèles "actionnent une politique" : biais de code, choix de bibliothèques, médiation de l'information et de l'action. Si les modèles sont importés, les représentations culturelles, la langue, l'éthique opérationnelle sont arbitrées ailleurs. C'est le mécanisme exact par lequel la France-fonction peut être désaccouplée de la France-civilisation : les institutions continuent d'opérer, mais sur des arbitrages cognitifs faits hors-sol. La contre-ingérence informationnelle n'est dès lors pas un service périphérique, c'est la condition d'existence d'une souveraineté cognitive dès lors que l'IA générative médie l'accès à l'information.
Indépendance. Capital américain dans Mistral < 30%. Mission : rester indépendant, viser cotation, refuser rachat. "Si vous vous faites racheter, vous avez raté." Critique frontale de la culture exit-vers-US dominante dans l'entrepreneuriat européen, c'est-à-dire de la stratégie qui transforme systématiquement chaque succès européen en filiale américaine.
Impression globale très satisfaisante de m'entendre moi-même dans le smots de Mensch.
Il reste cependant encore tellement de travail de plaidoyer pour que ces évidences prénètrent l'esprit de tous les politiques.
Mais nous sommes sur le bonne voie.
https://t.co/rSLjA5yA1O
"Au bout d'un certain temps, les innovations technologiques finissent toujours par profiter au plus grand nombre".
Voilà une idée que j'ai pas mal entendue ces jours-ci. Qu'à la fin, la technologie finit inexorablement par renforcer la classe moyenne, ou le bien être du plus grand nombre. Pour ceux-là, il est bon de convoquer les travaux de Bob Allen, un économiste qui a démontré que la condition de la classe moyenne Britannique s'est dégradée très substantiellement entre 1790 et 1860, au moment même où s'exprimait à plein la première révolution industrielle (Voir Engels' Pause: A Pessimist`s Guide to the British Industrial Revolution) et où des fortunes immenses se créaient. Ca n'a pas été un petit incident : ça a duré 70 ans — difficile de qualifier cela de 'frottement schumpéterien'. Durant des décennies des millions de personnes, des enfants en particulier, ont dû travailler 14 à 16 heures par jour, juste pour survivre. Et non, ce n'est en aucun cas la main invisible du marché qui a mis fin à cette situation, mais bien les lois sociales mises en place très progressivement à partir de 1838, lois ont permis de redistribuer de la valeur aux travailleurs et des droits sociaux (NB : je rappelle ici que je suis un entrepreneur, que j'ai passé 30 ans de ma vie à monter des entreprises et à lever des fonds, et que me suspecter d'avoir une inclinaison naturelle et ancienne pour le marxisme est un peu fort de café).
Ce qui me semble inquiétant, c'est que le contexte contemporain a une similitude frappante avec la situation telle qu'elle existait dans la première moitié du XIXe siècle : Concentration historiquement forte des capitaux. Collision entre le pouvoir politique et économique. Et surtout, bataille d'empires : c'est l'argument qu'utilisaient les grands industriels britanniques du XIXe siècle pour légitimer la nécessité de garder des salaires bas (l'un des fameux arguments d'Engel), de sorte à damer le pion des autres puissances concurrentes, dont la France. Certes, il ne s'agit plus de bas salaires (quoique), mais il s'agit d'empêcher l'antitrust d'agir (entreprises trop grosses, asséchant les capitaux pour les autres), d'empêcher l'apparition de contraintes liées à la sécurité de ces modèles (qui se mettent potentiellement à créer des virus, ou à percer la sécurité des systèmes d'information), de limiter l'accès des tiers aux technologies critiques, etc. Si on voulait créer un contexte qui pourrait se retourner à terme contre la classe moyenne, on ne ferait pas autrement.
Je note que les premiers commentateurs de mon nouvel ouvrage Le Péril IA sont assez unanimes sur le fait qu'il est incomparablement plus sombre que ne l'étaient les précédents ; mais je l'assume. Ce n'est pas fortuit : il est encore temps d'agir. Et à ceux-là, il faut faire observer que la seconde partie décrit les nombreux champs du possible qu'ouvre l'IA, qui sont encore inexplorés aussi bien sur le plan politique qu'en ce qui concerne notre potentiel individuel. C'est les idées que je développe dans mon dernier livre "Le Péril IA, devenir des machines ou rester vivants" https://t.co/WwbFR8w9a9
poke @CarlosDiaz
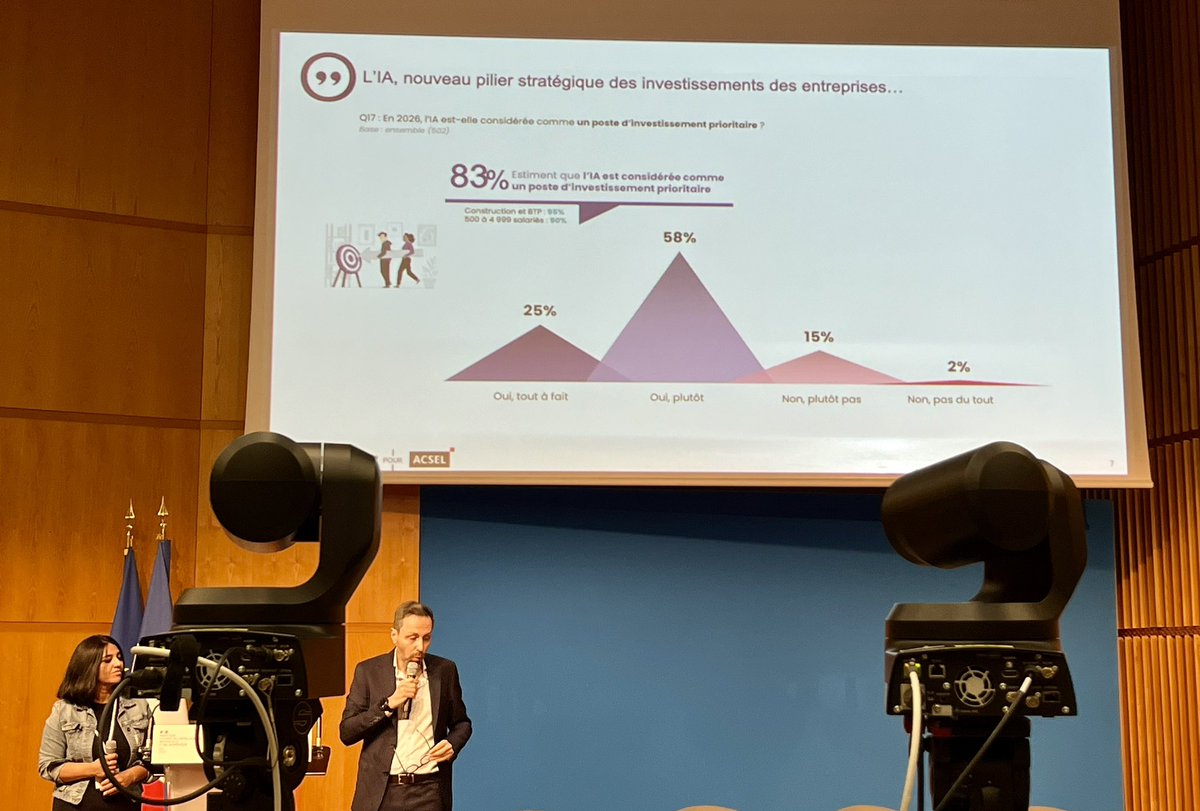
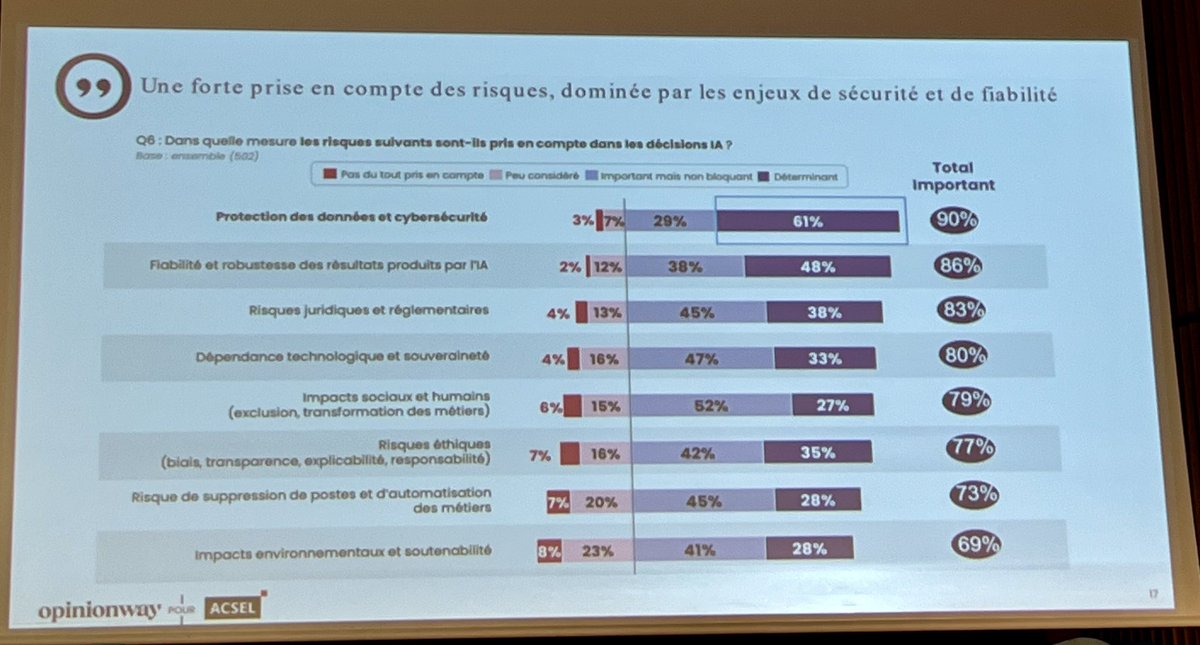
Suite de la restitution des résultats du baromètre "Croissance & #IA" de l’@AcselDigital.
Où l’on mesure la bascule opérée par les entreprises et leur maturité :
✅ 83% considèrent comme prioritaire d’investir dans l’IA
✅ 98% estiment que l’IA impacte déjà leur croissance
🚀
Présentation ce matin à Bercy du baromètre "Croissance & #IA" de l’@AcselDigital, qui nous révèle que :
✅ 95% des entreprises estiment que le #digital a un impact sur leur CA.
Elles étaient 62% dans l’édition précédente ; ce n’est plus une vague, c’est un tsunami !
#TransfoNum
🚨 BREAKING: OpenAI and Google are about to have a massive legal problem.
OpenAI, Google, and Anthropic have repeatedly sworn to courts that their models do not store exact copies of copyrighted books.
They claim their "safety training" prevents regurgitation.
Researchers just dropped a paper called "Alignment Whack-a-Mole" that proves otherwise.
They didn't use complex jailbreaks or malicious prompts.
They just took GPT-4o, Gemini, and DeepSeek, and fine-tuned them on a normal, benign task: expanding plot summaries into full text.
The safety guardrails instantly collapsed.
Without ever seeing the actual book text in the prompt, the models started spitting out exact, verbatim copies of copyrighted books.
Up to 90% of entire novels, word-for-word. Continuous passages exceeding 460 words at a time.
But here is the part that changes everything.
They fine-tuned a model exclusively on Haruki Murakami novels.
It didn't just learn Murakami. It unlocked the verbatim text of over 30 completely unrelated authors across different genres.
The AI wasn't learning the text during fine-tuning.
The text was already permanently trapped inside its weights from pre-training. The fine-tuning just turned off the filter.
It gets worse.
They tested models from three completely different tech giants. All three had memorized the exact same books, in the exact same spots.
A 90% overlap. It's a fundamental, industry-wide vulnerability.
For years, AI companies have argued in court that their models are just "learning patterns," not storing raw data.
This paper provides the smoking gun.
> be us, two French students on a gap year
> take 12 hours of train in a single day to make it to a @ycombinator x Paris event last July
> hear @t_blom mention the opportunity to rethink the audit and consulting model
> spend months doing traditional consulting to understand exactly where it breaks
> publish two benchmarks seen by 12M+ people to better understand frontier models outside of maths and code
> spend weeks designing an AI-native alternative to consulting
> build the first end-to-end version
> apply to YC
> get into YC to build a new way for companies to solve business problems
Can’t wait for what comes next !
Google vient de sortir son Figma Killer.
Ça s'appelle Stitch. C'est gratuit. Et ça introduit un concept que les devs vont adorer : DESIGN.md
👇 La vidéo complète
https://t.co/gAB3fWMCEK
C'est quoi ?
→ Tu décris ton app en langage naturel
→ L'IA génère l'UI haute fidélité
→ Tu exportes en React / HTML
→ Et tu connectes ça à Claude Code via MCP
Le DESIGN.md c'est le CLAUDE.md du design :
Un fichier markdown qui décrit ton design system, portable entre projets et outils.
J'ai tout testé en live. Le bon, le mauvais, et mon avis honnête.
Tout le monde a accès à un crayon. Pourtant presque personne n'écrit un bon roman.
Tout le monde a accès à des instruments. Pourtant presque personne ne compose un bon album.
"L'IA va permettre à tout le monde de créer des apps incroyables" est exactement le même raisonnement.
Le code n'a jamais été le vrai skill. Le code c'est le crayon, c'est le médium.
Ce que les agents IA automatisent, c'est la friction du médium.
Mais construire un bon logiciel demande de maîtriser des dizaines de concepts qui n'ont rien à voir avec le fait de taper du code :
- penser en systèmes, comprendre comment les composants cohabitent
- structurer la data pour qu'elle scale et reste maintenable
- avoir du taste sur l'UX, savoir ce qui fait qu'un produit est excellent vs correct
- savoir définir un problème avant de le résoudre
- comprendre l'architecture, le edge case, le tradeoff
Un romancier ne galère pas parce que le crayon est dur à tenir.
Il galère parce qu'il faut maîtriser les arcs narratifs, le worldbuilding, le style, le rythme, la tension. Le crayon c'est le plus simple dans l'équation.
Le software c'est pareil. La barre d'entrée pour builder n'a jamais été le code. C'est tout ce qui vient avant et autour.
Les agents IA vont créer plus de builders. Mais pas plus de bons builders.
Exactement comme l'accès universel au crayon n'a pas créé plus de bons romanciers.
-> Premier cas criminel de fraude au streaming par IA. Et c'est complètement fou.
Un homme de Caroline du Nord a utilisé l'IA pour générer des centaines de milliers de chansons. Il les a mises sur Spotify, Apple Music, Amazon.
Puis il a botté des milliards de streams sur ses propres morceaux.
-> 660 000 faux streams par jour. Répartis sur des milliers de titres pour que personne ne remarque rien.
-> 1,2 million de dollars par an. Pour de la musique qu'aucun humain n'a jamais écoutée.
-> Résultat : 8 millions de dollars empochés.
Pendant ce temps, les vrais artistes galèrent à 0,003€ par stream, font de la promo sur TikTok, supplient pour des placements en playlist.
Lui ? L'IA a fait la musique ET le public.
Il a été rattrapé. Il va rembourser les 8 millions.
Mais ce problème le dépasse :
L'industrie musicale a passé 10 ans à combattre le piratage. Maintenant elle doit combattre des chansons qui n'existent pas, écoutées par des gens qui n'existent pas.
Et depuis cette affaire, l'IA n'a fait que s'améliorer.
Le playbook est public. La fraude de demain sera encore plus difficile à détecter.
L'IA ne change pas que la création. Elle change aussi la triche.
#RGPD
La CJUE met du plomb dans l’aile de la stratégie consistant à s’inscrire sur des sites ou newsletters dans le seul but de demander ensuite un droit d’accès aux données avec l’espoir qu’il n’y soit pas donné suite, pour demander une indemnité. C’est un abus de droit.
Jeff Bezos prépare l'un des plus gros paris industriel de la décennie.
100 milliards de dollars. Un fonds pour racheter des entreprises manufacturières et les transformer avec l'IA.
Selon le Wall Street Journal, Bezos a déjà rencontré des fonds souverains au Moyen-Orient et à Singapour pour lever ce montant colossal.
Les secteurs ciblés : semi-conducteurs, défense, aérospatiale.
Le projet s'appelle "Project Prometheus" — une startup dont Bezos est co-CEO, dédiée à appliquer l'IA générative à l'ingénierie et à la production industrielle. Elle a déjà levé 6,2 milliards fin 2025.
Et au board ? David Limp, le CEO de Blue Origin.
Ce qu'il faut comprendre :
- Jusqu'ici, la course à l'IA se jouait dans le logiciel. Chatbots, génération d'images, code.
- Bezos vient de déplacer le terrain de jeu dans le monde physique.
- On parle de réinventer la façon dont on fabrique des puces, des avions, des voitures. Avec l'IA comme moteur.
L'IA ne va pas juste changer ce qu'on voit sur nos écrans. Elle va changer ce qu'on construit avec nos mains.
Et Bezos vient de mettre 100 milliards sur cette conviction.